大家好,我是老三,面渣反击 继续这一节,我们必须在另一次面试中询问知识点——Java并发。
这篇文章有点长,4万字,图文详解60道Java并发面试题。人已经肝麻了,大家都可以了、慢慢看!扶我起来,我还能肝!
基础
1.并行和并发有什么区别?
从操作系统的角度来看,线程是CPU分配的最小单位。
- 并行就是同时执行两个线程。这需要两个CPU分别执行两个线程。
- 并发就是同一时刻,只有一个执行,但是一个时间段内,两个线程都执行了。并发的实现依赖于CPU切换线程,本上对用户没有感知,因为切换时间很短。
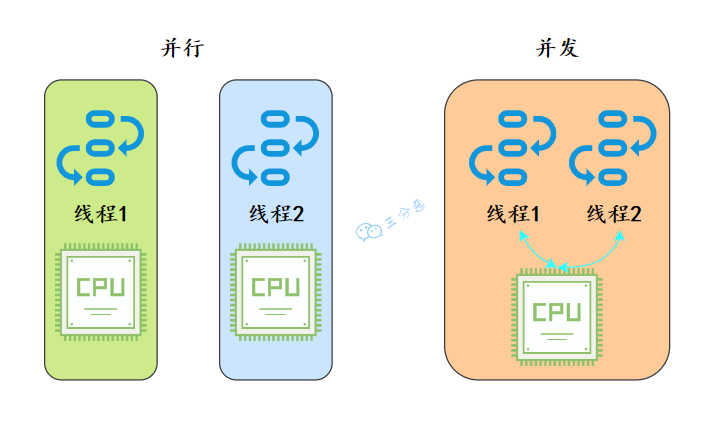
就像我们去食堂吃饭一样,平行的是我们在多个窗口排队,几个阿姨同时做饭;并发是我们挤在一个窗口,阿姨给了一勺,匆忙给了一勺。
2.过程和线程是什么?
要说线程,首先要说过程。
- 流程:流程是数据集中代码的运行活动,是系统资源分配和调度的基本单位。
- 线程:线程是过程的执行路径,一个过程中至少有一个线程,多个线程共享过程的资源。
在分配资源时,操作系统将资源分配给流程, 但是 CPU 资源特殊,分配到线程,因为真的需要占用CPU线程运行,所以也说线程是 CPU基本单位的分配。
比如在Java当我们开始的时候 main 事实上,函数启动了一个函数JVM进程,而 main 函数的线程是这个过程中的线程,也称为主线程。
一个过程中有多个线程,多个线程共享堆和方法区资源,但每个线程都有自己的程序计数器和堆栈。
3.创建线程的方法有多少?
Java中创建线程主要有三种方式,分别为继承Thread类、实现Runnable接口、实现Callable接口。
- 继承Thread类,重写run()方法,调用start()启动线程的方法
public class ThreadTest {
/** * 继承Thread类 */ public static class MyThread extends Thread {
@Override public void run() {
System.out.println("This is child thread"); } } public static void main(String[] args) {
MyThread thread = new MyThread(); thread.start(); } } - 实现 Runnable 接口,重写run()方法
public class RunnableTask implements Runnable {
public void run() {
System.out.println("Runnable!"); } public staticvoid main(String[] args) {
RunnableTask task = new RunnableTask();
new Thread(task).start();
}
}
上面两种都是没有返回值的,但是如果我们需要获取线程的执行结果,该怎么办呢?
- 实现Callable接口,重写call()方法,这种方式可以通过FutureTask获取任务执行的返回值
public class CallerTask implements Callable<String> {
public String call() throws Exception {
return "Hello,i am running!";
}
public static void main(String[] args) {
//创建异步任务
FutureTask<String> task=new FutureTask<String>(new CallerTask());
//启动线程
new Thread(task).start();
try {
//等待执行完成,并获取返回结果
String result=task.get();
System.out.println(result);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
4.为什么调用start()方法时会执行run()方法,那怎么不直接调用run()方法?
JVM执行start方法,会先创建一条线程,由创建出来的新线程去执行thread的run方法,这才起到多线程的效果。
**为什么我们不能直接调用run()方法?**也很清楚, 如果直接调用Thread的run()方法,那么run方法还是运行在主线程中,相当于顺序执行,就起不到多线程的效果。
5.线程有哪些常用的调度方法?
在Object类中有一些函数可以用于线程的等待与通知。
-
wait():当一个线程A调用一个共享变量的 wait()方法时, 线程A会被阻塞挂起, 发生下面几种情况才会返回 :
-
(1) 线程A调用了共享对象 notify()或者 notifyAll()方法;
-
(2)其他线程调用了线程A的 interrupt() 方法,线程A抛出InterruptedException异常返回。
-
-
wait(long timeout) :这个方法相比 wait() 方法多了一个超时参数,它的不同之处在于,如果线程A调用共享对象的wait(long timeout)方法后,没有在指定的 timeout ms时间内被其它线程唤醒,那么这个方法还是会因为超时而返回。
-
wait(long timeout, int nanos),其内部调用的是 wait(long timout)函数。
上面是线程等待的方法,而唤醒线程主要是下面两个方法:
- notify() : 一个线程A调用共享对象的 notify() 方法后,会唤醒一个在这个共享变量上调用 wait 系列方法后被挂起的线程。 一个共享变量上可能会有多个线程在等待,具体唤醒哪个等待的线程是随机的。
- notifyAll() :不同于在共享变量上调用 notify() 函数会唤醒被阻塞到该共享变量上的一个线程,notifyAll()方法则会唤醒所有在该共享变量上由于调用 wait 系列方法而被挂起的线程。
Thread类也提供了一个方法用于等待的方法:
-
join():如果一个线程A执行了thread.join()语句,其含义是:当前线程A等待thread线程终止之后才
从thread.join()返回。
- sleep(long millis) :Thread类中的静态方法,当一个执行中的线程A调用了Thread 的sleep方法后,线程A会暂时让出指定时间的执行权,但是线程A所拥有的监视器资源,比如锁还是持有不让出的。指定的睡眠时间到了后该函数会正常返回,接着参与 CPU 的调度,获取到 CPU 资源后就可以继续运行。
- yield() :Thread类中的静态方法,当一个线程调用 yield 方法时,实际就是在暗示线程调度器当前线程请求让出自己的CPU ,但是线程调度器可以无条件忽略这个暗示。
Java 中的线程中断是一种线程间的协作模式,通过设置线程的中断标志并不能直接终止该线程的执行,而是被中断的线程根据中断状态自行处理。
- void interrupt() :中断线程,例如,当线程A运行时,线程B可以调用钱程interrupt() 方法来设置线程的中断标志为true 并立即返回。设置标志仅仅是设置标志, 线程A实际并没有被中断, 会继续往下执行。
- boolean isInterrupted() 方法: 检测当前线程是否被中断。
- boolean interrupted() 方法: 检测当前线程是否被中断,与 isInterrupted 不同的是,该方法如果发现当前线程被中断,则会清除中断标志。
6.线程有几种状态?
在Java中,线程共有六种状态:
| 状态 | 说明 |
|---|---|
| NEW | 初始状态:线程被创建,但还没有调用start()方法 |
| RUNNABLE | 运行状态:Java线程将操作系统中的就绪和运行两种状态笼统的称作“运行” |
| BLOCKED | 阻塞状态:表示线程阻塞于锁 |
| WAITING | 等待状态:表示线程进入等待状态,进入该状态表示当前线程需要等待其他线程做出一些特定动作(通知或中断) |
| TIME_WAITING | 超时等待状态:该状态不同于 WAITIND,它是可以在指定的时间自行返回的 |
| TERMINATED | 终止状态:表示当前线程已经执行完毕 |
线程在自身的生命周期中, 并不是固定地处于某个状态,而是随着代码的执行在不同的状态之间进行切换,Java线程状态变化如图示:
7.什么是线程上下文切换?
使用多线程的目的是为了充分利用CPU,但是我们知道,并发其实是一个CPU来应付多个线程。
为了让用户感觉多个线程是在同时执行的, CPU 资源的分配采用了时间片轮转也就是给每个线程分配一个时间片,线程在时间片内占用 CPU 执行任务。当线程使用完时间片后,就会处于就绪状态并让出 CPU 让其他线程占用,这就是上下文切换。
8.守护线程了解吗?
Java中的线程分为两类,分别为 daemon 线程(守护线程)和 user 线程(用户线程)。
在JVM 启动时会调用 main 函数,main函数所在的钱程就是一个用户线程。其实在 JVM 内部同时还启动了很多守护线程, 比如垃圾回收线程。
那么守护线程和用户线程有什么区别呢?区别之一是当最后一个非守护线程束时, JVM会正常退出,而不管当前是否存在守护线程,也就是说守护线程是否结束并不影响 JVM退出。换而言之,只要有一个用户线程还没结束,正常情况下JVM就不会退出。
9.线程间有哪些通信方式?
关键字volatile可以用来修饰字段(成员变量),就是告知程序任何对该变量的访问均需要从共享内存中获取,而对它的改变必须同步刷新回共享内存,它能保证所有线程对变量访问的可见性。
关键字synchronized可以修饰方法或者以同步块的形式来进行使用,它主要确保多个线程在同一个时刻,只能有一个线程处于方法或者同步块中,它保证了线程对变量访问的可见性和排他性。
可以通过Java内置的等待/通知机制(wait()/notify())实现一个线程修改一个对象的值,而另一个线程感知到了变化,然后进行相应的操作。
管道输入/输出流和普通的文件输入/输出流或者网络输入/输出流不同之处在于,它主要用于线程之间的数据传输,而传输的媒介为内存。
管道输入/输出流主要包括了如下4种具体实现:PipedOutputStream、PipedInputStream、 PipedReader和PipedWriter,前两种面向字节,而后两种面向字符。
如果一个线程A执行了thread.join()语句,其含义是:当前线程A等待thread线程终止之后才从thread.join()返回。。线程Thread除了提供join()方法之外,还提供了join(long millis)和join(long millis,int nanos)两个具备超时特性的方法。
ThreadLocal,即线程变量,是一个以ThreadLocal对象为键、任意对象为值的存储结构。这个结构被附带在线程上,也就是说一个线程可以根据一个ThreadLocal对象查询到绑定在这个线程上的一个值。
可以通过set(T)方法来设置一个值,在当前线程下再通过get()方法获取到原先设置的值。
关于多线程,其实很大概率还会出一些笔试题,比如交替打印、银行转账、生产消费模型等等,后面老三会单独出一期来盘点一下常见的多线程笔试题。
ThreadLocal
ThreadLocal其实应用场景不是很多,但却是被炸了千百遍的面试老油条,涉及到多线程、数据结构、JVM,可问的点比较多,一定要拿下。
10.ThreadLocal是什么?
ThreadLocal,也就是线程本地变量。如果你创建了一个ThreadLocal变量,那么访问这个变量的每个线程都会有这个变量的一个本地拷贝,多个线程操作这个变量的时候,实际是操作自己本地内存里面的变量,从而起到线程隔离的作用,避免了线程安全问题。
- 创建
创建了一个ThreadLoca变量localVariable,任何一个线程都能并发访问localVariable。
//创建一个ThreadLocal变量
public static ThreadLocal<String> localVariable = new ThreadLocal<>();
- 写入
线程可以在任何地方使用localVariable,写入变量。
localVariable.set("鄙人三某”);
- 读取
线程在任何地方读取的都是它写入的变量。
localVariable.get();
11.你在工作中用到过ThreadLocal吗?
有用到过的,用来做用户信息上下文的存储。
我们的系统应用是一个典型的MVC架构,登录后的用户每次访问接口,都会在请求头中携带一个token,在控制层可以根据这个token,解析出用户的基本信息。那么问题来了,假如在服务层和持久层都要用到用户信息,比如rpc调用、更新用户获取等等,那应该怎么办呢?
一种办法是显式定义用户相关的参数,比如账号、用户名……这样一来,我们可能需要大面积地修改代码,多少有点瓜皮,那该怎么办呢?
这时候我们就可以用到ThreadLocal,在控制层拦截请求把用户信息存入ThreadLocal,这样我们在任何一个地方,都可以取出ThreadLocal中存的用户数据。
很多其它场景的cookie、session等等数据隔离也都可以通过ThreadLocal去实现。
我们常用的数据库连接池也用到了ThreadLocal:
- 数据库连接池的连接交给ThreadLoca进行管理,保证当前线程的操作都是同一个Connnection。
12.ThreadLocal怎么实现的呢?
我们看一下ThreadLocal的set(T)方法,发现先获取到当前线程,再获取ThreadLocalMap,然后把元素存到这个map中。
public void set(T value) {
//获取当前线程
Thread t = Thread.currentThread();
//获取ThreadLocalMap
ThreadLocalMap map = getMap(t);
//讲当前元素存入map
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
ThreadLocal实现的秘密都在这个ThreadLocalMap了,可以Thread类中定义了一个类型为ThreadLocal.ThreadLocalMap的成员变量threadLocals。
public class Thread implements Runnable {
//ThreadLocal.ThreadLocalMap是Thread的属性
ThreadLocal.ThreadLocalMap threadLocals = null;
}
ThreadLocalMap既然被称为Map,那么毫无疑问它是<key,value>型的数据结构。我们都知道map的本质是一个个<key,value>形式的节点组成的数组,那ThreadLocalMap的节点是什么样的呢?
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
//节点类
Entry(ThreadLocal<?> k, Object v) {
//key赋值
super(k);
//value赋值
value = v;
}
}
这里的节点,key可以简单低视作ThreadLocal,value为代码中放入的值,当然实际上key并不是ThreadLocal本身,而是它的一个,可以看到Entry的key继承了 WeakReference(弱引用),再来看一下key怎么赋值的:
public WeakReference(T referent) {
super(referent);
}
key的赋值,使用的是WeakReference的赋值。
所以,怎么回答ThreadLocal原理?要答出这几个点:
- Thread类有一个类型为ThreadLocal.ThreadLocalMap的实例变量threadLocals,每个线程都有一个属于自己的ThreadLocalMap。
- ThreadLocalMap内部维护着Entry数组,每个Entry代表一个完整的对象,key是ThreadLocal的弱引用,value是ThreadLocal的泛型值。
- 每个线程在往ThreadLocal里设置值的时候,都是往自己的ThreadLocalMap里存,读也是以某个ThreadLocal作为引用,在自己的map里找对应的key,从而实现了线程隔离。
- ThreadLocal本身不存储值,它只是作为一个key来让线程往ThreadLocalMap里存取值。
13.ThreadLocal 内存泄露是怎么回事?
我们先来分析一下使用ThreadLocal时的内存,我们都知道,在JVM中,栈内存线程私有,存储了对象的引用,堆内存线程共享,存储了对象实例。
所以呢,栈中存储了ThreadLocal、Thread的引用,堆中存储了它们的具体实例。
ThreadLocalMap中使用的 key 为 ThreadLocal 的弱引用。
“弱引用:只要垃圾回收机制一运行,不管JVM的内存空间是否充足,都会回收该对象占用的内存。”
那么现在问题就来了,弱引用很容易被回收,如果ThreadLocal(ThreadLocalMap的Key)被垃圾回收器回收了,但是ThreadLocalMap生命周期和Thread是一样的,它这时候如果不被回收,就会出现这种情况:ThreadLocalMap的key没了,value还在,这就会。
那怎么解决内存泄漏问题呢?
很简单,使用完ThreadLocal后,及时调用remove()方法释放内存空间。
ThreadLocal<String> localVariable = new ThreadLocal();
try {
localVariable.set("鄙人三某”);
……
} finally {
localVariable.remove();
}
那为什么key还要设计成弱引用?
key设计成弱引用同样是为了防止内存泄漏。
假如key被设计成强引用,如果ThreadLocal Reference被销毁,此时它指向ThreadLoca的强引用就没有了,但是此时key还强引用指向ThreadLoca,就会导致ThreadLocal不能被回收,这时候就发生了内存泄漏的问题。
14.ThreadLocalMap的结构了解吗?
ThreadLocalMap虽然被叫做Map,其实它是没有实现Map接口的,但是结构还是和HashMap比较类似的,主要关注的是两个要素:元素数组和散列方法。
-
元素数组
一个table数组,存储Entry类型的元素,Entry是ThreaLocal弱引用作为key,Object作为value的结构。
private Entry[] table;
-
散列方法
散列方法就是怎么把对应的key映射到table数组的相应下标,ThreadLocalMap用的是哈希取余法,取出key的threadLocalHashCode,然后和table数组长度减一&运算(相当于取余)。
int i = key.threadLocalHashCode & (table.length - 1);
这里的threadLocalHashCode计算有点东西,每创建一个ThreadLocal对象,它就会新增0x61c88647,这个值很特殊,它是 也叫 。hash增量为 这个数字,带来的好处就是 hash 。
private static final int HASH_INCREMENT = 0x61c88647;
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}
15.ThreadLocalMap怎么解决Hash冲突的?
我们可能都知道HashMap使用了链表来解决冲突,也就是所谓的链地址法。
ThreadLocalMap没有使用链表,自然也不是用链地址法来解决冲突了,它用的是另外一种方式——。开放定址法是什么意思呢?简单来说,就是这个坑被人占了,那就接着去找空着的坑。
如上图所示,如果我们插入一个value=27的数据,通过 hash计算后应该落入第 4 个槽位中,而槽位 4 已经有了 Entry数据,而且Entry数据的key和当前不相等。此时就会线性向后查找,一直找到 Entry为 null的槽位才会停止查找,把元素放到空的槽中。
在get的时候,也会根据ThreadLocal对象的hash值,定位到table中的位置,然后判断该槽位Entry对象中的key是否和get的key一致,如果不一致,就判断下一个位置。
16.ThreadLocalMap扩容机制了解吗?
在ThreadLocalMap.set()方法的最后,如果执行完启发式清理工作后,未清理到任何数据,且当前散列数组中Entry的数量已经达到了列表的扩容阈值(len*2/3),就开始执行rehash()逻辑:
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
再着看rehash()具体实现:这里会先去清理过期的Entry,然后还要根据条件判断size >= threshold - threshold / 4 也就是size >= threshold* 3/4来决定是否需要扩容。
private void rehash() {
//清理过期Entry
expungeStaleEntries();
//扩容
if (size >= threshold - threshold / 4)
resize();
}
//清理过期Entry
private void expungeStaleEntries() {
Entry[] tab = table;
int len = tab.length;
for (int j = 0; j < len; j++) {
Entry e = tab[j];
if (e != null && e.get() == null)
expungeStaleEntry(j);
}
}
接着看看具体的resize()方法,扩容后的newTab的大小为老数组的两倍,然后遍历老的table数组,散列方法重新计算位置,开放地址解决冲突,然后放到新的newTab,遍历完成之后,oldTab中所有的entry数据都已经放入到newTab中了,然后table引用指向newTab
具体代码:
17.父子线程怎么共享数据?
父线程能用ThreadLocal来给子线程传值吗?毫无疑问,不能。那该怎么办?
这时候可以用到另外一个类——InheritableThreadLocal。
使用起来很简单,在主线程的InheritableThreadLocal实例设置值,在子线程中就可以拿到了。
public class InheritableThreadLocalTest {
public static void main(String[] args) {
final ThreadLocal threadLocal = new InheritableThreadLocal();
// 主线程
threadLocal.set("不擅技术");
//子线程
Thread t = new Thread() {
@Override
public void run() {
super.run();
System.out.println("鄙人三某 ," + threadLocal.get());
}
};
t.start();
}
}
那原理是什么呢?
原理很简单,在Thread类里还有另外一个变量:
ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
在Thread.init的时候,如果父线程的inheritableThreadLocals不为空,就把它赋给当前线程(子线程)的inheritableThreadLocals。
if (inheritThreadLocals && parent.inheritableThreadLocals != null)
this.inheritableThreadLocals =
ThreadLocal.createInheritedMap(parent.inheritableThreadLocals);
Java内存模型
18.说一下你对Java内存模型(JMM)的理解?
Java内存模型(Java Memory Model,JMM),是一种抽象的模型,被定义出来屏蔽各种硬件和操作系统的内存访问差异。
JMM定义了线程和主内存之间的抽象关系:线程之间的共享变量存储在主内存(Main Memory)中,每个线程都有一个私有的本地内存(Local Memory),本地内存中存储了该线程以读/写共享变量的副本。
Java内存模型的抽象图:
本地内存是JMM的 一个抽象概念,并不真实存在。它其实涵盖了缓存、写缓冲区、寄存器以及其他的硬件和编译器优化。
图里面的是一个双核 CPU 系统架构 ,每个核有自己的控制器和运算器,其中控制器包含一组寄存器和操作控制器,运算器执行算术逻辅运算。每个核都有自己的一级缓存,在有些架构里面还有一个所有 CPU 共享的二级缓存。 那么 Java 内存模型里面的工作内存,就对应这里的 Ll 缓存或者 L2 缓存或者 CPU 寄存器。
19.说说你对原子性、可见性、有序性的理解?
原子性、有序性、可见性是并发编程中非常重要的基础概念,JMM的很多技术都是围绕着这三大特性展开。
- :原子性指的是一个操作是不可分割、不可中断的,要么全部执行并且执行的过程不会被任何因素打断,要么就全不执行。
- :可见性指的是一个线程修改了某一个共享变量的值时,其它线程能够立即知道这个修改。
- :有序性指的是对于一个线程的执行代码,从前往后依次执行,单线程下可以认为程序是有序的,但是并发时有可能会发生指令重排。
分析下面几行代码的原子性?
int i = 2;
int j = i;
i++;
i = i + 1;
- 第1句是基本类型赋值,是原子性操作。
- 第2句先读i的值,再赋值到j,两步操作,不能保证原子性。
- 第3和第4句其实是等效的,先读取i的值,再+1,最后赋值到i,三步操作了,不能保证原子性。
原子性、可见性、有序性都应该怎么保证呢?
- 原子性:JMM只能保证基本的原子性,如果要保证一个代码块的原子性,需要使用
synchronized。 - 可见性:Java是利用
volatile关键字来保证可见性的,除此之外,final和synchronized也能保证可见性。 - 有序性:
synchronized或者volatile都可以保证多线程之间操作的有序性。
20.那说说什么是指令重排?
在执行程序时,为了提高性能,编译器和处理器常常会对指令做重排序。重排序分3种类型。
- 编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
- 指令级并行的重排序。现代处理器采用了指令级并行技术(Instruction-Level Parallelism,ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应 机器指令的执行顺序。
- 内存系统的重排序。由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。
从Java源代码到最终实际执行的指令序列,会分别经历下面3种重排序,如图:
我们比较熟悉的双重校验单例模式就是一个经典的指令重排的例子,Singleton instance=new Singleton();对应的JVM指令分为三步:分配内存空间–>初始化对象—>对象指向分配的内存空间,但是经过了编译器的指令重排序,第二步和第三步就可能会重排序。
JMM属于语言级的内存模型,它确保在不同的编译器和不同的处理器平台之上,通过禁止特定类型的编译器重排序和处理器重排序,为程序员提供一致的内存可见性保证。
21.指令重排有限制吗?happens-before了解吗?
指令重排也是有一些限制的,有两个规则happens-before和as-if-serial来约束。
happens-before的定义:
- 如果一个操作happens-before另一个操作,那么第一个操作的执行结果将对第二个操作可见,而且第一个操作的执行顺序排在第二个操作之前。
- 两个操作之间存在happens-before关系,并不意味着Java平台的具体实现必须要按照 happens-before关系指定的顺序来执行。如果重排序之后的执行结果,与按happens-before关系来执行的结果一致,那么这种重排序并不非法
happens-before和我们息息相关的有六大规则:
- :一个线程中的每个操作,happens-before于该线程中的任意后续操作。
- :对一个锁的解锁,happens-before于随后对这个锁的加锁。
- :对一个volatile域的写,happens-before于任意后续对这个volatile域的读。
- :如果A happens-before B,且B happens-before C,那么A happens-before C。
- :如果线程A执行操作ThreadB.start()(启动线程B),那么A线程的 ThreadB.start()操作happens-before于线程B中的任意操作。
- :如果线程A执行操作ThreadB.join()并成功返回,那么线程B中的任意操作 happens-before于线程A从ThreadB.join()操作成功返回。
22.as-if-serial又是什么?单线程的程序一定是顺序的吗?
as-if-serial语义的意思是:不管怎么重排序(编译器和处理器为了提高并行度),。编译器、runtime和处理器都必须遵守as-if-serial语义。
为了遵守as-if-serial语义,编译器和处理器不会对存在数据依赖关系的操作做重排序,因为这种重排序会改变执行结果。但是,如果操作之间不存在数据依赖关系,这些操作就可能被编译器和处理器重排序。为了具体说明,请看下面计算圆面积的代码示例。
double pi = 3.14; // A
double r = 1.0; // B
double area = pi * r * r; // C
上面3个操作的数据依赖关系:
A和C之间存在数据依赖关系,同时B和C之间也存在数据依赖关系。因此在最终执行的指令序列中,C不能被重排序到A和B的前面(C排到A和B的前面,程序的结果将会被改变)。但A和B之间没有数据依赖关系,编译器和处理器可以重排序A和B之间的执行顺序。
所以最终,程序可能会有两种执行顺序:
as-if-serial语义把单线程程序保护了起来,遵守as-if-serial语义的编译器、runtime和处理器共同编织了这么一个“楚门的世界”:单线程程序是按程序的“顺序”来执行的。as- if-serial语义使单线程情况下,我们不需要担心重排序的问题,可见性的问题。
23.volatile实现原理了解吗?
volatile有两个作用,保证和。
volatile怎么保证可见性的呢?
相比synchronized的加锁方式来解决共享变量的内存可见性问题,volatile就是更轻量的选择,它没有上下文切换的额外开销成本。
volatile可以确保对某个变量的更新对其他线程马上可见,一个变量被声明为volatile 时,线程在写入变量时不会把值缓存在寄存器或者其他地方,而是会把值刷新回主内存 当其它线程读取该共享变量 ,会从主内存重新获取最新值,而不是使用当前线程的本地内存中的值。
例如,我们声明一个 volatile 变量 volatile int x = 0,线程A修改x=1,修改完之后就会把新的值刷新回主内存,线程B读取x的时候,就会清空本地内存变量,然后再从主内存获取最新值。
volatile怎么保证有序性的呢?
重排序可以分为编译器重排序和处理器重排序,valatile保证有序性,就是通过分别限制这两种类型的重排序。
为了实现volatile的内存语义,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。
- 在每个volatile写操作的前面插入一个
StoreStore屏障 - 在每个volatile写操作的后面插入一个
StoreLoad屏障 - 在每个volatile读操作的后面插入一个
LoadLoad屏障 - 在每个volatile读操作的后面插入一个
LoadStore屏障
锁
24.synchronized用过吗?怎么使用?
synchronized经常用的,用来保证代码的原子性。
synchronized主要有三种用法:
- 作用于当前对象实例加锁,进入同步代码前要获得
synchronized void method() {
//业务代码
}
-
:也就是给当前类加锁,会作⽤于类的所有对象实例 ,进⼊同步代码前要获得当前 class 的锁。因为静态成员不属于任何⼀个实例对象,是类成员( static 表明这是该类的⼀个静态资源,不管 new 了多少个对象,只有⼀份)。
如果⼀个线程 A 调⽤⼀个实例对象的⾮静态 synchronized ⽅法,⽽线程 B 需要调⽤这个实例对象所属类的静态 synchronized ⽅法,是允许的,不会发⽣互斥现象,因为访问静态 synchronized ⽅法占⽤的锁是当前类的锁,⽽访问⾮静态 synchronized ⽅法占⽤的锁是当前实例对象锁。
synchronized void staic method() {
//业务代码
}
- :指定加锁对象,对给定对象/类加锁。 synchronized(this|object) 表示进⼊同步代码库前要获得给定对象的锁。 synchronized(类.class) 表示进⼊同步代码前要获得 当前 的锁
synchronized(this) {
//业务代码
}
25.synchronized的实现原理?
synchronized是怎么加锁的呢?
我们使用synchronized的时候,发现不用自己去lock和unlock,是因为JVM帮我们把这个事情做了。
-
synchronized修饰代码块时,JVM采用
monitorenter、monitorexit两个指令来实现同步,monitorenter指令指向同步代码块的开始位置,monitorexit指令则指向同步代码块的结束位置。反编译一段synchronized修饰代码块代码,
javap -c -s -v -l SynchronizedDemo.class,可以看到相应的字节码指令。
-
synchronized修饰同步方法时,JVM采用
ACC_SYNCHRONIZED标记符来实现同步,这个标识指明了该方法是一个同步方法。同样可以写段代码反编译看一下。
synchronized锁住的是什么呢?
monitorenter、monitorexit或者ACC_SYNCHRONIZED都是的。
实例对象结构里有对象头,对象头里面有一块结构叫Mark Word,Mark Word指针指向了。
所谓的Monitor其实是一种,也可以说是一种。在Java虚拟机(HotSpot)中,Monitor是由的,可以叫做内部锁,或者Monitor锁。
ObjectMonitor的工作原理:
- ObjectMonitor有两个队列:_WaitSet、_EntryList,用来保存ObjectWaiter 对象列表。
- _owner,获取 Monitor 对象的线程进入 _owner 区时, _count + 1。如果线程调用了 wait() 方法,此时会释放 Monitor 对象, _owner 恢复为空, _count - 1。同时该等待线程进入 _WaitSet 中,等待被唤醒。
ObjectMonitor() { _header = NULL; _count = 0 标签:连接器主线变送器保护地流量变送器类型