我的博客链接
在知识地图嵌入任务中,作者提出了一个简单高效的对比学习框架,将知识地图嵌入到不同三元组中相关实体和实体-关系之间的语义相似性中,并将该框架作为额外的约束项一起训练KGE,这可以减少不同三元组中相关实体与实体之间的语义距离,从而提高知识图谱嵌入的性能。
0. 前言
Topic
data mine; topic mine;
problems in previous work
- 大多数以前的知识图嵌入模型忽略了不同三元组中相关实体和实体关系之间的语义相似性。
motivation
challenge
提出了一个简单高效的对比学习框架,可以减少不同三元组相关实体与实体之间的语义距离,从而提高知识图嵌入的性能。
contrastive learning;Knowledge graph embedding;
- 作者可以借鉴比较学习方法对损失函数的额外约束。
5. 还有哪些问题?
- 相当于在原有的KGE在此基础上,增加了约束;
- 通过比较学习,似乎需要大量的数据预处理工作(寻找正实例对,负实例对);
0.1 待学习知识
- Contrastive Learning
1 背景知识
Contrastive Learning
The key idea of contrastive learning is pulling the semantically close pairs together and push apart the negative pairs.
2 模型
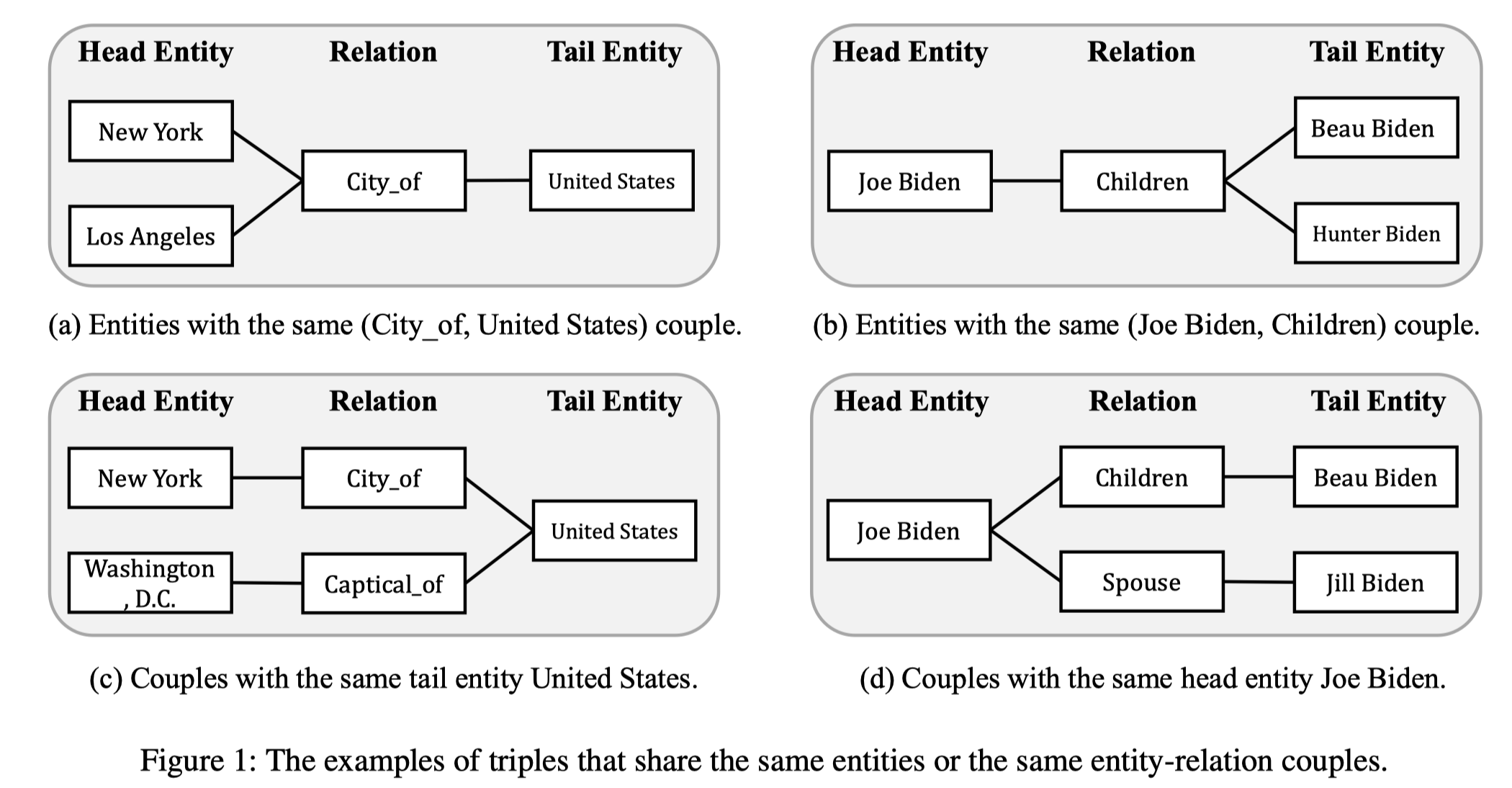
正样例选择
- 头实体与尾实体关系相同,尾实体相似。
- 对于一个实体-关系,有相同的另一个实体 实体-关系对;
编码器
两层MLP
对比损失
使用以下函数: C L ( z i , z i ) = ? 1 ∣ P ( i ) ∣ log ∑ z i ∈ P ( i ) e sim ( z i , z i ) / τ ∑ z j ∈ N ( i ) e sim ( z i , z j ) / τ \mathrm{CL}\left(\mathbf{z}_{i}, \mathbf{z}_{i}^{ }\right)=\frac{-1}{|P(i)|} \log \frac{\sum_{z_{i}^{ } \in P(i)} e^{\operatorname{sim}\left(\mathbf{z}_{i}, \mathbf{z}_{i}^{ }\right) / \tau}}{\sum_{z_{j} \in N(i)} e^{\operatorname{sim}\left(\mathbf{z}_{i}, \mathbf{z}_{j}\right) / \tau}} CL(zi,zi )=∣P(i)∣−1log∑zj∈N(i)esim(zi,zj)/τ∑zi+∈P(i)esim(zi,zi+)/τ
- 其中,一个实例 z i z_{i} zi和它的所有正样例 z i + z_{i}^{+} zi+,黑体为其表示向量。sim是余弦相似度,P(i) 是 minibatch 中所有正例的集合,N(i) 是 batch 中所有负例的集合。
L c ( h i , r j , t k ) = C L ( h i , h i + ) + C L ( t k , t k + ) + C L ( h i R j , ( h i R j ) + ) + C L ( R j t ‾ k , ( R j t ‾ k ) + ) \begin{aligned} \mathcal{L}_{c}\left(h_{i}, r_{j}, t_{k}\right) &=\mathrm{CL}\left(\mathbf{h}_{i}, \mathbf{h}_{i}^{+}\right)+\mathrm{CL}\left(\mathbf{t}_{k}, \mathbf{t}_{k}^{+}\right) \\ &+\mathrm{CL}\left(\mathbf{h}_{i} \mathbf{R}_{j},\left(\mathbf{h}_{i} \mathbf{R}_{j}\right)^{+}\right) \\ &+\mathrm{CL}\left(\mathbf{R}_{j} \overline{\mathbf{t}}_{k},\left(\mathbf{R}_{j} \overline{\mathbf{t}}_{k}\right)^{+}\right) \end{aligned} Lc(hi,rj,tk)=CL(hi,hi+)+CL(tk,tk+)+CL(hiRj,(hiRj)+)+CL(Rjtk,(Rjtk)+)
损失求导
h i t + 1 = h i t − η ∂ C L ( h i , h i + ) ∂ h i = h i t + η ∑ h i + ∈ P ( i ) h i + τ ∣ P ( i ) ∣ − η ∑ h j ∈ N ( i ) ( e ( h i ⋅ h j / τ ) h j ) τ ∣ P ( i ) ∣ ∑ h j ∈ N ( i ) e ( h i ⋅ h j / τ ) \begin{array}{l}\mathbf{h}_{i}^{t+1}=\mathbf{h}_{i}^{t}-\eta \frac{\partial \mathrm{CL}\left(\mathbf{h}_{i}, \mathbf{h}_{i}^{+}\right)}{\partial \mathbf{h}_{i}} \\ =\mathbf{h}_{i}^{t}+\frac{\eta \sum_{h_{i}^{+} \in P(i)} \mathbf{h}_{i}^{+}}{\tau|P(i)|}-\frac{\eta \sum_{h_{j} \in N(i)}\left(e^{\left(\mathbf{h}_{i} \cdot \mathbf{h}_{j} / \tau\right)} \mathbf{h}_{j}\right)}{\tau|P(i)| \sum_{h_{j} \in N(i)} e^{\left(\mathbf{h}_{i} \cdot \mathbf{h}_{j} / \tau\right)}}\end{array} hit+1=hit−η∂hi∂CL(hi,hi+)=hit+τ∣P(i)∣η∑hi+∈P(i)hi+−τ∣P(i)∣∑hj∈N(i)e(hi⋅hj/τ)η∑hj∈N(i)(e(hi⋅hj/τ)hj)
- 通过求导后梯度下降的方向,可以看到,实例的优化方向和向所有正实例的方式一致,远离负样例的方向;
加权对比损失
作者发现不同的对比损失项对于不同的知识图谱有着不同的影响,所以作者设计一个超参数进行调整: L c w ( h i , r j , t k ) = α h C L ( h i , h i + ) + α t C L ( t k , t k + ) + α h r C L ( h i R j , ( h i R j ) + ) + α t r C L ( R j t ‾ k , ( R j t ‾ k ) + ) \begin{aligned} \mathcal{L}_{c}^{w}\left(h_{i}, r_{j}, t_{k}\right) &=\alpha_{h} \mathrm{CL}\left(\mathbf{h}_{i}, \mathbf{h}_{i}^{+}\right)+\alpha_{t} \mathrm{CL}\left(\mathbf{t}_{k}, \mathbf{t}_{k}^{+}\right) \\ &+\alpha_{h r} \mathrm{CL}\left(\mathbf{h}_{i} \mathbf{R}_{j},\left(\mathbf{h}_{i} \mathbf{R}_{j}\right)^{+}\right) \\ &+\alpha_{t r} \mathrm{CL}\left(\mathbf{R}_{j} \overline{\mathbf{t}}_{k},\left(\mathbf{R}_{j} \overline{\mathbf{t}}_{k}\right)^{+}\right) \end{aligned} Lcw(hi,rj,tk)