DBSCAN它出现得更早(1996年),更具代表性的,虽然该算法本身就是密度聚类算法,但也可以使用,其思想是在样本空间中找到低密度的异常样本。本文介绍了基本原理以及如何进行异常检测,并介绍了聚类的应用。
DBSCAN是英文缩写,意思是:DBSCAN将簇定义为,能将密度足够高的区域分成簇,并能在噪声空间数据库中找到任何形状的聚类。
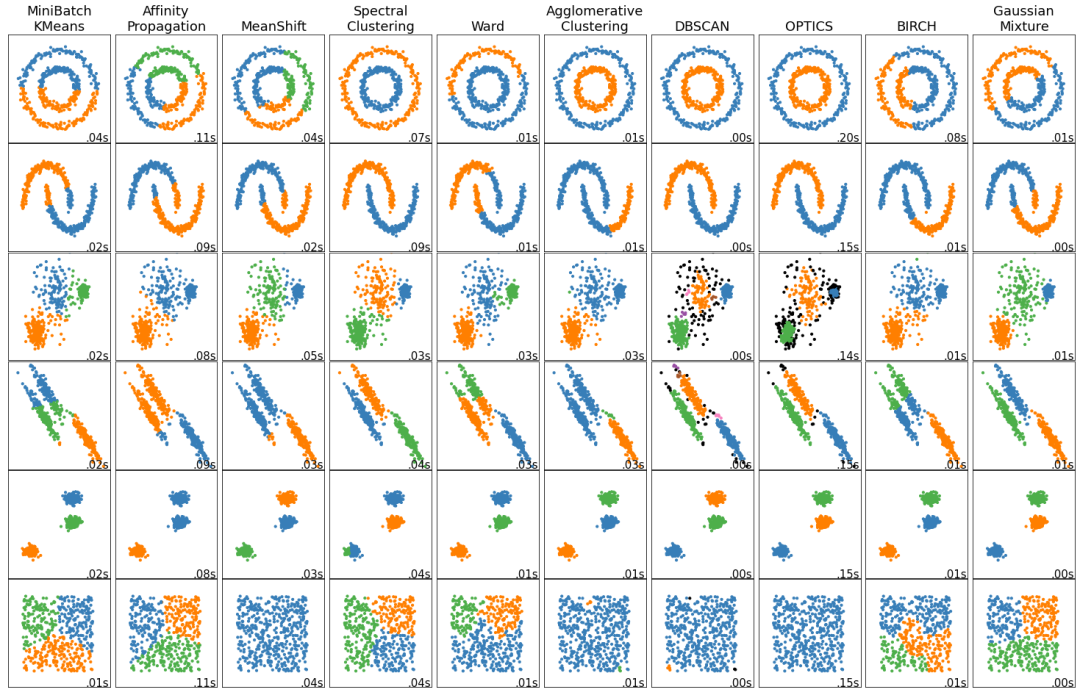
在聚类问题中,如果有各种数据集,可以采用如果各种数据呈非球形分布(如太极图、笑脸图等),则采用聚类算法kmeans在这种情况下,算法效果将大大降低。如下图所示,聚类算法更为合适。
各种聚类算法对不同形状的簇的聚类效果聚类效果。
基于密度,远离密度核心的噪声点分为一簇;无需事先知道聚类簇的数量;可以找到任何形状的聚类簇
DBSCAN的基本概念可以用1个思想,2个参数,3种类别,4种关系来总结。
,直观效果,DBSCAN算法可以找到样本点的所有密集区域,并将这些密集区域作为聚类簇。
可以简单地理解,该算法是基于密度的生长,类似于病毒感染。只要密度足够大,就可以感染过去。如果密度较小,请停止感染,如下图所示。
可视化网站:https://www.naftaliharris.com/blog/visualizing-dbscan-clustering/
这两个算法参数实际上可以描述什么是密集的:
这两个参数恰到好处sklearn.cluster.DBSCAN算法中的两个参数是:和 :eps如果某个数据点的邻域至少有一个数据点的邻域半径min_sample对于一个数据点,将该数据点视为核心点。如果某个核心点的邻域中还有其他核心点,则将其视为同一簇。
如果将eps如果设置得很小,可能没有点成为核心点,所有点都可能被标记为噪音。
如果将eps如果设置得很大,所有的点都会分成同一个簇。
如果min_samples如果设置太大,则意味着更少的点将成为核心点,更多的点将被标记为噪声。如下所示,如果指定半径r的点中有满足条件的点,则可以认为该区域密集
我们可以简单地理解,邻域半径R内样本点的数量大于或等于minpoints点称为核心点,不属于核心点,但在某个核心点的邻域内的点称为边界点,既不是核心点,也不是边界点,而是噪声点。
对某个数据集D,样本p-领域至少包含MinPts样本(包括样本p),所以样本p称为核心点。
即:
称p为核心点,其中-领域的表达式为:
非核心点样本b,在任何核心点p的-领域中,样本b称为边界点。
即:
称b为边界点。对于非核心点的样本n,若n不在任何核心点p的-领域,则样本n称为噪声点。
即:
称n为噪声点。
假设MinPts=4.核心点、非核心点和噪声分布如下图所示:
DBSCAN算法分组的原理类似于亲戚、家庭和家庭的划分,如 父亲、母亲和孩子可以通过基因和婚姻分为一个家庭;如果家庭和家庭的长辈可以通过基因或婚姻来确定亲属关系,那么可以分为家庭或亲戚。DBSCAN划分的原理也差不多,但这里的基因或婚姻关系是r-邻域(一般理解可以理解为半径为r的球),只要多个对象可以通过r邻域连接起来,就可以分为一类。
若P为核心点,Q在P的R在邻域内,那叫P到Q密度直达。如果P到达,任何核心点到自身密度直达,密度直达不对称。Q密度可达,Q到P密度不一定可达。
若有核心点P2,P3,……,Pn,且P1到P2密度直达,P2到P3密度直达,……,P(n-1)到Pn密度直达,Pn直接到Q密度,然后P1.Q密度可达
若有核心点S,使得S到P如果P和Q密度可达,则P和Q密度可达Q密度相连。,如果P和Q如果密度相连,Q和P也有一定的密度连接,密度连接的两点属于同一聚类簇。
若两点不属于密度连接,则两点非密度连接,非密度连接的两点属于不同的聚类簇,或存在噪声点。
若点Q在核心点Pr-在邻域内,Q可以从P直接密度到达,假设M=6.上图点P是核心点。点Q在点Pr在邻域内,P和Q可以达到直接密度。当然,其他五点和P也可以直接密度达到
看下图:核心样本Y的邻域内样本X,称为Y到X密度是直接的。请注意,这种关系是单向的,反向不一定建立
若存在 P1,P2,......,Pm是一列核心点, Pi-1 是从 Pi 出发关于r和M直接密度可达的(即P2在 P1的圈里,P3在P2的圈里,P4在P3的圈里,以此类推,Pm在Pm-1的圈里),则称 点Pm是从 P1 出发关于r和M密度可达的
在看下图:核心样本Y到核心样本P3是密度直达的,核心样本P3到核心样本P2是密度直达的,核心样本P2到样本X是密度直达的,像这种通过P3和P2的中转,在样本Y到样本X建立的关系叫做密度可达。
如果样本集中存在点O,使得点P、Q是从o出发关于r和M密度可达的,那么点P、Q是关于r和M密度相连的(通俗理解,P是家庭O中男方的远房亲戚,Q是家庭O中女方的远房亲戚,那么P和Q也是亲戚关系)
再看看下图:核心样本O到样本Y是密度可达的,同时核心样本O到样本X是密度可达的,这样的关系,我们可以说样本X和样本Y是密度相连的。
对于一系列密度可达的点而言,其邻域范围内的点都是密度相连的,下图所示是一个minPoints为5的领域,红色点为core ponit, 绿色箭头连接起来的则是密度可达的样本集合,在这些样本点的邻域内的点构成了一个密度相连的样本集合,这些样本就属于同一个cluster
DBSCAN的聚类过程就是根据核心点来推导出最大密度相连的样本集合,首先随机寻找一个核心样本点,按照minPoints和eps来推导其密度相连的点,赋予一个cluser编号,然后再选择一个没有赋予类别的核心样本点,开始推导其密度相连的样本结合,一直迭代到所有的核心样本点都有对应的类别为止。
DBSCAN的算法步骤比较简单,主要分成两步。
扫描全部样本点,如果某个样本点R半径范围内点数目>=MinPoints,则将其纳入核心点列表,并将其密度直达的点形成对应的临时聚类簇。
对于每一个临时聚类簇,检查其中的点是否为核心点,如果是,将该点对应的临时聚类簇和当前临时聚类簇合并,得到新的临时聚类簇。
重复此操作,直到当前临时聚类簇中的每一个点要么不在核心点列表,要么其密度直达的点都已经在该临时聚类簇,该临时聚类簇升级成为聚类簇。
继续对剩余的临时聚类簇进行相同的合并操作,直到全部临时聚类簇被处理。反复寻找这些核心点直接密度可达或密度可达的点,将其加入到相应的类,对于核心点发生密度可达状况的类,给予合并(组建好各个家庭后,如果家庭中长辈之间有亲戚关系,则把家庭合并为一个大家族)
DBSCAN算法可以抽象为以下几步:
1)找到每个样本的邻域内的样本个数,若个数大于等于MinPts,则该样本为核心点;
2)找到每个核心样本密度直达和密度可达的样本,且该样本亦为核心样本,忽略所有的非核心样本;
3)若非核心样本在核心样本的邻域内,则非核心样本为边界样本,反之为噪声。
https://scikit-learn.org/stable/modules/generated/sklearn.cluster.DBSCAN.html
sklearn.cluster.DBSCAN(eps=0.5, *,
min_samples=5,
metric='euclidean',
metric_params=None,
algorithm='auto',
leaf_size=30,
p=None,
n_jobs=None
): float,ϵ-邻域的距离阈值
:int,样本点要成为核心对象所需要的 ϵ-邻域的样本数阈值
:度量方式,默认为欧式距离,可以使用的距离度量参数有:
-
欧式距离 “euclidean”
曼哈顿距离 “manhattan”
切比雪夫距离“chebyshev”
闵可夫斯基距离 “minkowski”
带权重闵可夫斯基距离 “wminkowski”
标准化欧式距离 “seuclidean”
马氏距离“mahalanobis”
自己定义距离函数
:近邻算法求解方式,有四种:
-
“brute”蛮力实现
“kd_tree” KD树实现
“ball_tree”球树实现
“auto”上面三种算法中做权衡,选择一个拟合最好的最优算法。
:使用“ball_tree”或“kd_tree”时,停止建子树的叶子节点数量的阈值
:只用于闵可夫斯基距离和带权重闵可夫斯基距离中p值的选择,p=1为曼哈顿距离, p=2为欧式距离。如果使用默认的欧式距离不需要管这个参数。
:CPU并行数,若值为 -1,则用所有的CPU进行运算
: 核心点的索引,因为labels_不能区分核心点还是边界点,所以需要用这个索引确定核心点
:训练样本的核心点
:每个点所属集群的标签,也就是聚类的编号,-1代表噪声点
先看个简单的案例
from sklearn.cluster import DBSCAN
import numpy as np
X = np.array([[1, 2], [2, 2], [2, 3],
[8, 7], [8, 8], [25, 80]])
clustering = DBSCAN(eps=3, min_samples=2).fit(X)
clustering.labels_
array([ 0, 0, 0, 1, 1, -1])0,,0,,0:表示前三个样本被分为了一个群
1, 1:中间两个被分为一个群
-1:最后一个为异常点,不属于任何一个群
再生成个复杂点的数据看看
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
# 生成随机簇类数据,样本数为600,类别为5
X, y = make_blobs(random_state=170,
n_samples=600,
centers=5
)
# 绘制延伸图
plt.scatter(X[:,0],X[:,1])
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
plt.show()
# dbscan聚类算法 按照经验MinPts=2*ndims,因此我们设置MinPts=4。
dbscan = DBSCAN(eps=1,
min_samples=4)
clusters = dbscan.fit_predict(X)
# dbscan聚类结果
plt.scatter(X[:,0],X[:,1],
c=clusters,
cmap="plasma")
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
plt.title("eps=0.5,minPts=4")
plt.show()
# 性能评价指标ARI
from sklearn.metrics.cluster import adjusted_rand_score
# ARI指数 ARI= 0.99为了较少算法的计算量,我们尝试减小MinPts的值。
print("ARI=",round(adjusted_rand_score(y,clusters),2))由上文可知,DBSCAN主要包含两个参数:
:邻域半径,也就是我们要观察的最小半径是多少
:形成簇类所需的最小样本个数,比如MinPts等于5,形成簇类的前提是至少有一个样本的-邻域大于等于5。
如下图,如果值取的太小,部分样本误认为是噪声点(白色);值取的多大,大部分的样本会合并为同一簇类。
同样的,若MinPts值过小,则所有样本都可能为核心样本;MinPts值过大时,部分样本误认为是噪声点(白色),如下图:
根据经验,minPts的最小值可以从数据集的维数D得到,即。若minPts=1,含义为所有的数据集样本都为核心样本,即每个样本都是一个簇类;若minPts≤2,结果和单连接的层次聚类相同;因此minPts必须大于等于3,因此一般认为minPts=2*dim,若数据集越大,则minPts的值选择的亦越大。
eps值常常用k-距离曲线(k-distance graph)得到,计算每个样本与所有样本的距离,选择第k个最近邻的距离并从大到小排序,得到k-距离曲线,曲线拐点对应的距离设置为eps,如下图:
由图可知或者根据k-距离曲线的定义可知:样本点第k个近邻距离值小于归为簇类,大于的样本点归为噪声点。根据经验,一般选择值等于第(minPts-1)的距离,计算样本间的距离前需要对数据进行归一化,使所有特征值处于同一尺度范围,有利于参数的设置。
如果(k+1)-距离曲线和k-距离曲线没有明显差异,那么minPts设置为k值。例如k=4和k>4的距离曲线没有明显差异,而且k>4的算法计算量大于k=4的计算量,因此设置MinPts=4。
数据来自于kaggle上的一个信用卡欺诈检测比赛,数据质量高,正负样本比例非常悬殊,很典型的异常检测数据集,在这个数据集上来测试一下各种异常检测手段的效果。当然,可能换个数据集结果就会有很大不同,结果仅供参考。
我们用一个信用卡欺诈的数据来进行测试,看看聚类算法用于异常检测的效果怎么样。
信用卡欺诈是指故意使用伪造、作废的信用卡,冒用他人的信用卡骗取财物,或用本人信用卡进行恶意透支的行为,信用卡欺诈形式分为3种:。欺诈案件中,有60%以上是伪造信用卡诈骗,其特点是团伙性质,从盗取卡资料、制造假卡、贩卖假卡,到用假卡作案,牟取暴利。而信用卡欺诈检测是银行减少损失的重要手段。
该数据集包含欧洲持卡人于 2013 年 9 月通过信用卡进行的交易信息。此数据集显示的是两天内发生的交易,在 284807 笔交易中,存在 492 起欺诈,数据集高度不平衡,正类(欺诈)仅占所有交易的 0.172%。原数据集已做脱敏处理和PCA处理,匿名变量V1, V2, ...V28 是 PCA 获得的主成分,唯一未经过 PCA 处理的变量是 Time 和 Amount。Time 是每笔交易与数据集中第一笔交易之间的间隔,单位为秒;Amount 是交易金额。Class 是分类变量,在发生欺诈时为1,否则为0。项目要求根据现有数据集建立分类模型,对信用卡欺诈行为进行检测。
PCA - "Principal Component Analysis" - 主成分分析,用于提取数据集的"主成分"特征,即对数据集进行降维处理。
数据集 Credit Card Fraud Detection 由比利时布鲁塞尔自由大学(ULB) - Worldline and the Machine Learning Group 提供。可从Kaggle上下载:https://www.kaggle.com/mlg-ulb/creditcardfraud
我们抽取一部分的数据来进行无监督的学习,这个算法说实话,太慢了,30w的数据,基本上要5-6min,所以我只挑了10w左右来做实验
import os
import pandas as pd
import numpy as np
# 工作空间设置
os.chdir('/Users/wuzhengxiang/Documents/DataSets/CreditCardFraudDetection')
os.getcwd()
# 数据读取
data = pd.read_csv('creditcard.csv')
# 查看 0 - 1 个数
import matplotlib.pyplot as plt
data.Class.value_counts()
num_nonfraud = np.sum(data['Class'] == 0)
num_fraud = np.sum(data['Class'] == 1)
plt.bar(['Fraud', 'non-fraud'], [num_fraud, num_nonfraud], color='red')
plt.show()
# 数据集划分 + 简单的特征工程
data['Hour'] = data["Time"].apply(lambda x : divmod(x, 3600)[0])
X = data.drop(['Time','Class'],axis=1)
Y = data.Class
# 数据归一化
from sklearn.preprocessing import StandardScaler
sd = StandardScaler()
column = X.columns
X[column] = sd.fit_transform(X[column])
#训练集交叉验证,开发集测试泛化性能
from sklearn.model_selection import train_test_split
X_train,X_test,Y_train,Y_test = train_test_split(X,Y,
test_size=0.55,
random_state=0
)
from sklearn.cluster import DBSCAN
import numpy as np
clustering = DBSCAN(eps=3.8, min_samples=13).fit(X_train)
pd.Series(clustering.labels_).value_counts()
0 113644
1 8372
-1 6016
2 32
4 16
8 15
3 14
5 14
6 13
10 9
9 9
7 9
X_train['labels_'] = clustering.labels_
X_train['labels'] = Y_train
X_train[X_train['labels']==1]
[218 rows x 32 columns]
X_train[(X_train['labels']==1)&(X_train['labels_']==-1)]
[186 rows x 32 columns]可以看到,异常簇有6016个样本,覆盖了186个样本,所以从覆盖的角度来说,还是可以的,但是准确率就比较差了,也可能我技术不好,从这个案例来看,在比较高维度的实际数据中,这个算法并不是很适合用来做异常检测,只有在维度比较低的情况下,做异常检测效果不错。并未我在试验的时候,进行了很多半径和样本数量的尝试。如果要得到比较理想的效果,可能还需要更加深入的研究。看了这个算法,还是比较用来做聚类,异常检测有点费劲了。后面继续研究该算法在聚类里面的应用。
1)相比K-Means,DBSCAN 。
2)可以的稠密数据集进行聚类,相对的,K-Means之类的聚类算法一般只适用于凸数据集。
3)可以在,对数据集中的异常点不敏感。
4)聚类结果没有偏倚,相对的,K-Means之类的聚类算法初始值对聚类结果有很大影响。
1)算法要对数据集中的每个样本都进行计算,如果数据集样本量很大,那么计算效率、对计算机算力的要求等就有了很大考验,可以对搜索最近邻时建立的KD树或者球树进行规模限制来改进。
2)对于具有不同密度的簇,DBSCAN 算法的效果可能不是很好,当空间聚类的密度不均匀、样本分布较分散、聚类间距差相差很大时,聚类质量较差,需要,这对分析人员是一个很大的挑战
3)在两个聚类交界边缘的点会视乎它在数据库的次序决定加入哪个聚类,幸运地,这种情况并不常见,而且对整体的聚类结果影响不大(DBSCAN*变种算法,把交界点视为噪音,达到完全决定性的结果。)
4)调参相对于传统的K-Means之类的聚类算法稍复杂,主要需要对距离阈值eps,邻域样本数阈值MinPts联合调参,不同的参数组合对最后的聚类效果有较大影响,DBSCAN聚类算法对的,如果指定不当,该算法将造成聚类质量的下降,DBSCAN 算法的两个参数也是要根据具体的数据情况进行多次尝试。
5)作为异常检测时,并没有异常程度,只有一个标签,是够异常
推荐阅读:
我的2022届互联网校招分享
我的2021总结
浅谈算法岗和开发岗的区别
互联网校招研发薪资汇总
2022届互联网求职现状,金9银10快变成铜9铁10!!
保持谦逊、保持自律、保持进步
发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记