xml
XML 用于传输和存储数据。
HTML 用于显示数据的设计。
什么是 XML
- XML 指扩展标记语言(EXtensible Markup Language)。
- XML 是一种很像HTML标记语言。
- XML 其设计目的是传输数据,而不是显示数据。
- XML 标签没有预定义,需要自己定义。
- XML 设计为自我描述。
- XML 是 W3C 推荐标准。
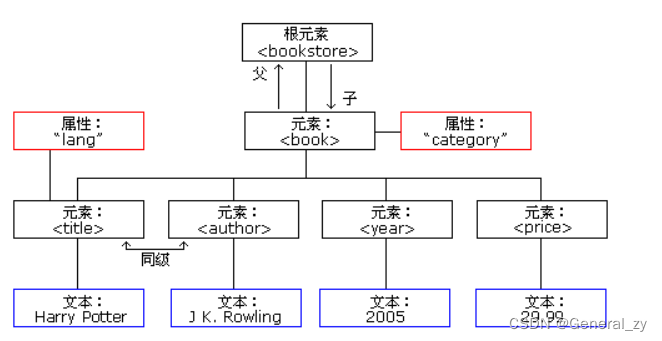
XML 树结构
XML 文档使用简单的自我描述语法:
第一行是 XML 声明。它的定义 XML 的版本(1.0)以及使用的编码 <?xml version="1.0" encoding="UTF-8"?> 根元素 <note> 4 行描述根的 4 个子元素 <to>Tove</to> <from>Jani</from> <heading>Reminder</heading> <body>Don't forget me this weekend!</body> </note> XML 文件形成树结构
XML 文档必须包含根元素。这个元素是所有其他元素的父元素。
XML 文档中的元素形成了一棵文档树。树从根开始,扩展到树的底部。
所有元素都可以有子元素:
<root> <child> <subchild>...</subchild> </child> <child> <subchild>...</subchild> </child> <child> <subchild>...</subchild> </child> <child> <subchild>.....</subchild>
</child>
</root>
xml语法
- XML 文档必须有根元素
- XML 声明
XML 声明文件的可选部分,如果存在需要放在文档的第一行 <?xml version="1.0" encoding="utf-8"?> - 所有的 XML 元素都必须有一个关闭标签(声明不是 XML 文档本身的一部分,它没有关闭标签。)
- XML 标签对大小写敏感
- XML 必须正确嵌套
- XML 属性值必须加引号
- 特殊字符
在 XML 中,只有字符 "<" 和 "&" 确实是非法的。大于号是合法的,但是用实体引用来代替它是一个好习惯。< < less than > > greater than & & ampersand ' ' apostrophe " " quotation mark - XML 中的注释
<!-- This is a comment --> - 在 XML 中,空格会被保留。在 XML 中,文档中的空格不会被删减。
XML 元素
一个元素可以包含:
- 其他元素
- 文本
- 属性
XML 命名规则
XML 元素必须遵循以下命名规则:
- 名称可以包含字母、数字以及其他的字符
- 名称不能以数字或者标点符号开始
- 名称不能以字母 xml(或者 XML、Xml 等等)开始
- 名称不能包含空格
可使用任何名称,没有保留的字词。
XML 属性
属性难以阅读和维护。请尽量使用元素来描述数据。而仅仅使用属性来提供与数据无关的信息。
XML 命名空间
在 XML 中,元素名称是由开发者定义的,当两个不同的文档使用相同的元素名时,就会发生命名冲突。 假设两个文档都有<table>这个标签,又同时使用两个文档就会出现冲突。
使用前缀来避免命名冲突
<h:table>
<h:tr>
<h:td>Apples</h:td>
<h:td>Bananas</h:td>
</h:tr>
</h:table>
<f:table>
<f:name>African Coffee Table</f:name>
<f:width>80</f:width>
<f:length>120</f:length>
</f:table>
XML 命名空间 - xmlns 属性
命名空间是在元素的开始标签的 xmlns 属性中定义的。
xmlns:前缀=“URI”。
<root xmlns:h="http://www.w3.org/TR/html4/" xmlns:f="http://www.w3cschool.cc/furniture">
<h:table>
<h:tr>
<h:td>Apples</h:td>
<h:td>Bananas</h:td>
</h:tr>
</h:table>
<f:table>
<f:name>African Coffee Table</f:name>
<f:width>80</f:width>
<f:length>120</f:length>
</f:table>
</root>
默认的命名空间
xmlns="namespaceURI"
<table xmlns="http://www.w3.org/TR/html4/">
<tr>
<td>Apples</td>
<td>Bananas</td>
</tr>
</table>
lxml和xml库
- xml是自带的,纯python的,速度慢
- lxml是第三方的,基于Cython的,速度快
lxml
pip install lxml
xpath常用表达式
| 表达式 | 描述 |
| nodename | 选取此节点的所有子节点 |
| / | 从当前节点选取直接子节点 |
| // | 从当前节点选取子孙节点 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
| * | 通配符,选择所有元素节点与元素名 |
| @* | 选取所有属性 |
| [@attrib] | 选取具有给定属性的所有元素 |
| [@attrib='value'] | 选取给定属性具有给定值的所有元素 |
| [tag] | 选取所有具有指定元素的直接子节点 |
| [tag='text'] | 选取所有具有指定元素并且文本内容是text节点 |
使用
- lxml.etree.HTML(html_str)方法可以自动补全不完整的标签。
- lxml.etree.XML(xml_str)同理
- fromstring、XML、HTML、parse:返回的是一个Element对象,是一个节点,主要用于解析文档碎片
- parse(): 返回值是一个ElementTree类型的对象,完整的xml树结构,parse主要用来解析完整的文档,而不是Element对象。
结点操作
创建节点
root = etrre.Element('root')
获取节点名称
print(root.tag)
添加子节点
child_sub = etree.SubElement(root, 'child_sub')
或
child_append = etree.Element('child_append')
root.append(child_append)
或
root.insert(0, child_append)
删除子节点
root.remove(child_sub) # 删除名字为child_sub节点
root.clear() # 清空root的所有子节点
访问节点
child_sub = root[0] # 通过下标来访问子节点
child_sub = root[0: 1][0] # 通过切片的方式来访问节点
for c in root: # 通过遍历来获取所有节点
print(c.tag)
c_append_index = root.index(child_append) # 获取节点的索引
print(len(root)) # 获取子节点的数量
print(child_sub.getparent().tag) # 查询父节点
print(root.getchildren()) # 查询所有子节点
print(root.getroot()) # 获取根节点
print(root.find('b')) # 查询第一个b标签
print(root.findall('.//b')) # 查询所有b标签
属性操作
创建属性
root = etree.Element('root', language='中文') # 创建节点时创建属性
root.set('hello', 'python') # 使用set方法为root节点添加属性
获取属性
print(root.get('language')) # 使用get方法获取属性
print(root['language'])
print(root.keys())
print(root.values())
print(root.items())
修改属性
root['language'] = 'English'
文本操作
- 在lxml中访问xml文本的方式有多种,可以使用text、tail属性的方式访问文本,也可以使用xpath语法访问文本。
- text属性用于成对便签的读取和设置
- tail属性用于单一标签的读取和设置
xml文件序列化
# 创建xml文本
root = '<root>data</root>'
# 将节点(Element对象)转为ElementTree对象。
tree = etree.ElementTree(root)
tree.write('text.xml', pretty_print=True, xml_declartion=True, encoding='utf-8')
命名空间处理
from lxml import etree
str_xml = """ <A xmlns="http://This/is/a/namespace"> <B>dataB1</B> <B>dataB2</B> <B><C>datac</C></B> </A> """
xml = etree.fromstring(str_xml) # 解析字符串
ns = xml.nsmap # 获取命名空间map(dict)
print(ns)
print(ns[None])
>>> {
None: 'http://This/is/a/namespace'}
>>> http://This/is/a/namespace
xpath
html = etree.HTML(text) # 也可以使用XML和fromstring方法
# 获取所有的class属性为item-1的href属性
href_list = html.xpath('//li[@class="item-1"]/a/@href')
# 获取所有的class属性为item-1的text内容
text_list = html.xpath('//li[@class="item-1"]/a/text()')
- 返回空列表:根据xpath语法规则字符串,没有定位到任何元素
- 返回由字符串构成的列表:xpath字符串规则匹配的一定是文本内容或某属性的值
- 返回由Element对象构成的列表:xpath规则字符串匹配的是标签,列表中的Element对象可以继续进行xpath