1 声音特性
声音(sound)它是由物体振动产生的声波。它是一种通过介质传播的波动现象,可以被人或动物听觉器官感知。最初振动的物体叫声源。声音以波的形式振动传播。声音是声波通过任何介质传播形成的运动。
频率:是每秒通过一定点声波的数量。它的测量单位是赫兹。1000赫或1000赫意味着每秒通过一定点声波有1000个周期,1兆赫意味着每秒有1万个周期。
音节:就是听觉能够自然察觉到的最小语音单位,音节有声母、韵母、声调三部分组成。一个汉字的读音就是一个音节,一个英文单词可能有一个或多个音节构成,并且按照音节的不同,可以分为不同的种类。
音素:它是从音节中分析出来的最小语音单元。当语音分析到音素时,它不能再分割。例如,她穿红色衣服是五个音节,红色可以进一步分为三个音素–h,o,ng。对音素的分析需要一定的语音知识,但如果读得慢一点,还是可以体会到的。
音位:指能区分意义的音素,如bian,pian,bu,pu就是靠b,p两种音素可以区分,所以b,p是两个音位。 人耳能听到的音频范围:20HZ–20KHZ。声音频率:3000HZ–3.4KHZ。乐器音频范围:20HZ–20KHZ。
2 语音时域特征
语音信号有时会改变特征,这是一个不稳定的随机过程。但在短时间内,其特征的基本特征 保持不变,即语音的短期稳定性。
在时域,语音信号可以直接用其时间波表示。其中,清音段类似于白噪声,频率高,但振幅小,周期性不明显;浊音周期明显,振幅大,频率相对较低。通过短期能量、短期过零率等方法可以分析语音信号的这些时域特征。
2.1 短时能量
由于语音信号的能量随时间而变化,清音和浊音之间的能量差异相当明显。因此,分析短期能量和短期平均范围可以描述语音特征的变化。
定义n时语音信号的短时平均能量为: 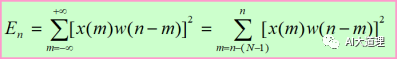 式中,N为窗长,可见短时能量是一帧样点值的加权平方和。特别是当窗函数为矩形窗时,有:
式中,N为窗长,可见短时能量是一帧样点值的加权平方和。特别是当窗函数为矩形窗时,有:
2.2 短时幅度
短期能量的一个主要问题是对信号电平值过于敏感。由于需要计算信号样值的平方和,因此在实现定点时容易溢出。为了克服这一缺点,可以定义一个短期平均范围函数来衡量语音范围的变化: 以上风格可以理解为w(n)对|x(n)|线性滤波如下的线性滤波操作。与短期能量相比,短期平均范围相当于用绝对值代替平方和,简化了操作。
2.3 短时过零率
短时平均过零率是语音信号时域分析中的一个特征参数。它是指每帧中信号通过零值的次数。
①对于有时间横轴的连续语音信号,可以通过横轴观察语音的时域波形。
②在离散时间的语音信号下,如果相邻的采样具有不同的代数符号,则称为过零,因此可以计算过零次数。
单位时间内的过零次数称为过零率。长时间过零率称为平均过零率。如果是正弦信号,其平均过零率是信号频率的两倍,除以采样频率,采样频率是固定的。因此,过零率可以在一定程度上反映信号的频率信息。短期平均过零率定义为:
3 语音频域特征
3.1 信号分类
计算信号能量(作用于单位电阻的电压信号) 释放的能量)信号可分为:
功率信号:能量无限,不能用能量表示,所以用平均功率表示;
能量信号:能量有限,平均功率为0;
3.2 频谱
功率信号频谱(离散): 含义: 周期功率信号振幅值f0)傅里叶级数展开后,多次离散倍频nf0表征,每个频点的幅值C(nf0)也即该频点的贡献权系数。
3.3 功率谱密度
功率信号的功率谱密度(连续):
含义:
按频点贡献传播信号功率;
因为它的能量是无限的,所以不能铺能量,只能用有限的功率;
积分功率谱密度,可获得局部频段承载的功率;
相比功率信号的频谱突出各频点对功率信号的信号幅值的贡献,功率谱密度突出各频点对功率信号的功率的贡献。
3.4 频谱密度
能量信号的频谱密度(连续): 含义:
能量信号通过傅里叶转换转换为连续频域;
但由于能量有限,离散贡献频点权系数(几乎为0)不能用,只能用频谱密度来表示。
3.5 能量谱密度
能量信号的能量谱密度(连续): 含义:
在频谱上铺设信号能量;
局部积分能量谱密度,可获得局部频段承载的能量;
与能量信号的频谱密度相比,能量谱密度突出了连续频点对能量信号的信号幅度值的贡献。
(AI大语音:语音信号时间有限,振幅有限,即能量有限,频率为0,应为能量信号,不能计算功率谱。我们实际上做了一个假设,语音帧,每一帧都是一个周期信号,所以它是一个周期信号,周期信号是一个功率信号。也就是说,能量信号确实是在分帧之前的。分帧后在做FFT的时候又在负无穷到正无穷上进行了周期扩长,所以才是功率信号。)
4 语音识别过程
所谓语音识别,是将语音信号转换为相应的文本信息,系统主要包括四个部分:特征提取、声学模型、语言模型、字典和解码。此外,为了更有效地提取特征,通常需要过滤收集到的声音信号、帧和其他音频数据预处理,从原始信号中提取需要分析的音频信号;特征提取将声音信号从时域转换为频域,为声学模型提供适当的特征向量;声学模型根据声学特征计算声学特征中每个特征向量的得分;语言模型根据语言学相关理论计算声信号对应短语序列的可能性;最后,根据现有字典解码短语序列,获得最终可能的文本表示。 预处理:
- 静音切除术一般称为静音切除术,以减少对后续步骤的干扰。VAD。
- 声音分帧,即将声音切割成一小段和一小段,每个小段被称为一帧,使用移动窗口函数来实现,而不是简单的切割,通常在帧之间重叠。
特征提取:主要算法有线性预测倒谱系数(LPCC)和Mel 倒谱系数(MFCC),目的是将每一帧波形变成包含声音信息的多维向量。
声学模型(AM):通过训练语音数据,输入是特征向量,输出是音素信息。字典:单词或单词对应于音素, 简单来说, 汉语是拼音和汉字的对应,英语是音标和单词的对应。
语言模型(LM):通过训练大量的文本信息,获得单个单词或单词相互关联的概率。
解码:通过声学模型、字典、语言模型输出提取特征后的音频数据。
语音识别过程的例子(只是图像表达,不是真实数据和过程):
1.语音信号:PCM文件等(我是机器人) 2. 特征提取:提取特征向量[1 2 3 4 56 0 …] 3. 声学模型:[1 2 3 4 56 0]-> w o s i j i q i r n 4. 字典:窝:w o;我:w o;是:s i;机:j i;器:q i;人:r n;级:j i;忍:r n; 5. 语言模型:我:0.0786, 是:0.0546,我是:0.0898,机器:0.0967,机器人:0.6785; 6. 输出文字:我是机器人;
参考链接:https://zhuanlan.zhihu.com/p/176820760