文章目录
-
- 一、Kafka Streams概述
-
- 1)Kafka Streams是什么
- 2)流式计算与批量计算的区别
- 3)Kafka Streams特点
- 二、Kafka Streams流处理拓扑
-
- 1)相关概念
- 2)Kafka Streams中两种定义流处理的方法
- 3)流处理中的三个时间
- 4)KTable和KSteam
- 5)窗口
- 三、Kafka Streams原理与架构
-
- 1)流分区和任务
- 2)线程模型
- 3)本地状态存储
- 4)容错
- 四、应用简单(WordCount示例)
-
- 1)启动zookeeper和kafka(无鉴权)
- 2)创建topic
- 3)Maven依赖配置
- 4)修改源码
- 5)启动 Wordcount 应用程序
- 6)通过jar包启动程序
一、Kafka Streams概述
官网文档:https://kafka.apache.org/32/documentation/streams/
1)Kafka Streams是什么
Kafka Streams是一套,它基于重要性它可以存储在概念上Kafka流式处理和分析中的数据,简称流式计算。
2)流式计算与批量计算的区别
- :输入是连续的,通常先定义目标计算,然后在数据到来后将计算逻辑应用到数据中,通常用增量计算代替全量计算。
- :一般先有全数据集,然后定义计算逻辑,并将计算应用于全数据。其特点是全计算,计算结果一次全输出。
3)Kafka Streams特点
- ,任何嵌入都很容易 Java 应用程序,并与用户拥有的任何现有的包装、部署和操作工具集成。
- 除了作为内部消息传递层Apache Kafka本身之外,;值得注意的是,它的使用 Kafka 对分区模型进行水平扩展处理,同时保持强大的排序保证。
- 支持,这样可以实现窗口连接、聚合等非常快速高效的状态操作。
- 支持处理语义,即使在处理过程中,确保每个记录只处理一次,也只处理一次 Streams 客户端或 Kafka 当代理出现故障时也是如此。
- 采用实现毫秒处理延迟,并支持操作,记录无序到达。
- 提供必要的流处理原语和和。
二、Kafka Streams流处理拓扑
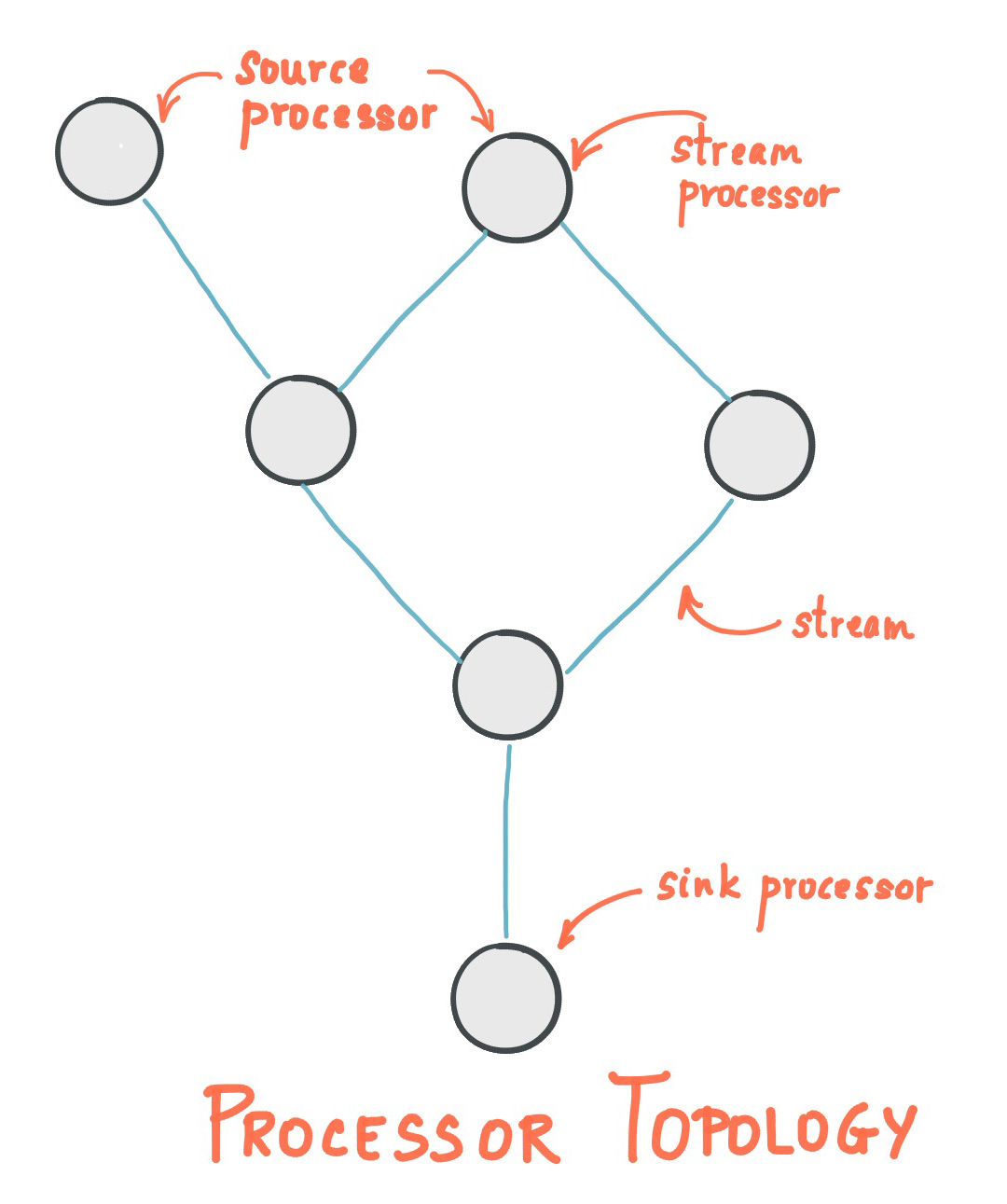
1)相关概念
- :它代表了一个无限不断更新的数据集。流是一个有序、可重放和容错的不可变数据记录序列,其中数据记录被定义为键对。
- 是任何使用 Kafka Streams 图书馆程序。它通过一个或多个处理器拓扑来定义其计算逻辑,其中处理器拓扑是由流(边)连接的流处理器(节点)图。
- 它是处理器拓扑中的一个节点;它表示一个处理步骤,通过从拓扑中的上游处理器游处理器,并可能产生一个或多个输出记录到下游处理器,以转换流中的数据。
拓扑有两种特殊处理器:
- :源处理器是一种没有任何上游处理器的特殊类型的流处理器。它使用这些主题的记录并将其转发到下游处理器,从一个或多个 Kafka 主题产生拓扑输入流。
- :接收器处理器是一种没有下游处理器的特殊类型的流处理器。它将上游处理器收到的任何记录发送到指定的处理器 Kafka 主题。
2)Kafka Streams两种定义流处理方法
- Kafka Streams DSL map提供最常见的数据转换操作;例如,开箱filter用join;
- aggregations较低级别的处理器 API允许开发人员定义和连接自定义处理器,并与状态存储交互。
3)流处理中的三个时间
流处理的一个关键方面是概念,以及它是如何建模和集成的。例如,一些操作,如添加窗口,是根据时间边界定义的。
- ——事件或数据记录发生的时间点最初是源头创建的。
例子:如果事件是由汽车发生的 GPS 如果传感器报告的地理位置发生变化,相关事件的时间将是 GPS 传感器捕获位置变化的时间。
- ——事件或数据记录只是流处理应用程序的时间点,即记录消耗的时间。处理时间可能比原始事件晚几毫秒、几个小时或几天。
示例:想象一个分析应用程序,它读取并处理从汽车传感器报告的地理位置数据,以将其呈现给车队管理仪表板。在这里,分析应用程序中的处理时间可能是事件时间后的毫秒或秒(例如,基于 Apache Kafka 和 Kafka Streams 实时管道)或几个小时(例如,基于 Apache Hadoop 或 Apache Spark 批处理管道)。
- ——事件或数据记录 Kafka 代理存储在主题分区中的时间点。与事件时间的区别在于,这个摄入时间戳是在 Kafka 代理将记录添加到目标主题中,而不是在源创建记录中。处理时间的区别在于处理时间是流程处理应用程序处理记录的时间。
例如,如果一个记录从未被处理过,它就没有处理时间的概念,但它仍然有一个摄入时间。
【温馨提示】 和 实际上,两者之间的选择是的(不是 Kafka Streams):从 Kafka 0.10.x 一开始,时间戳会自动嵌入 Kafka 消息中 Kafka 这些时间戳代表事件时间或摄取时间的配置。
4)KTable和KSteam
- ,可以认为所有记录都是通过的Insert only插入这个数据流的方式。
- ,可以理解为数据库中的表。每个记录都是KV键值对,key可以理解为数据库中的主键是唯一的value代表记录。我们可以认为KTable通过中间数据Update only以同样的方式进入。key,会覆盖掉原的那条记录。
综上来说,KStream是数据流,来多少数据就插入多少数据,是Insert only;KTable是数据集,相同key只允许保留最新的记录,也就是Update only。
5)窗口
流式数据在时间上无界的,但是聚合操作只能作用在特定(有界)的数据集,这时候就有了窗口的概念,在时间无界的数据流中定义一个边界来用于计算。
⼀个窗⼝包括窗⼝⼤⼩和滑动步长两个属性:
- :⼀条记录在窗⼝中持续的时间,持续时间超过窗⼝⼤⼩的记录将会被删除;
- :指定了⼀个窗⼝每次相对于前⼀个窗⼝向前移动的距离
【温馨提示】,如果超过窗⼝⼤⼩则会导致部分记录不属于任何窗⼝⽽不被处理。
Kafka Streams定义了三种窗⼝:
- :⼤⼩固定,可能会重叠的窗⼝模型
- :⼤⼩固定,不可重叠,⽆间隙的⼀类窗⼝模型
- :⼤⼩固定并且沿着时间轴连续滑动的窗⼝模型,如果两条记录时间戳之差在窗⼝⼤⼩之内,则这两条数据记录属于同⼀个窗⼝。在Kafka流中,滑动窗⼝只有在join操作的时候才⽤到。
三、Kafka Streams原理与架构
Kafka Streams 通过构建 Kafka 生产者和消费者库并利用 Kafka 的本机功能来提供数据并行性、分布式协调、容错和操作简单性,从而简化了应用程序开发。
1)流分区和任务
Kafka 的消息传递层对数据进行分区以进行存储和传输。Kafka Streams 对数据进行分区以进行处理。在这两种情况下,这种分区是实现数据局部性、弹性、可伸缩性、高性能和容错的原因。Kafka Streams 使用和的概念作为其基于 Kafka 主题分区的并行模型的逻辑单元。在并行性方面,Kafka Streams 和 Kafka 之间有着密切的联系:
- 每个流分区是一个完全有序的数据记录序列,并映射到一个 Kafka主题分区。
- 流中的数据记录映射到来自该主题的 Kafka消息。
- 数据记录的键决定了 Kafka 和 Kafka Streams 中数据的分区,即数据如何路由到主题内的特定分区。
【例如】如果您的输入主题有 ,那么您实例。这些实例将协作处理主题的数据。如果您运行的应用程序实例数量多于输入主题的分区,“多余”的应用程序实例将启动但保持空闲;但是,如果其中一个繁忙的,则其中。
下图显示了两个任务,每个任务分配有输入流的一个分区:
2)线程模型
Kafka Streams 允许用户配置库可用于并行化应用程序实例中的处理的线程数。每个线程可以使用其处理器拓扑独立地执行一个或多个任务。例如,下图显示了一个流线程运行两个流任务:
启动更多流线程或应用程序的更多实例仅相当于复制拓扑并让它处理不同的 Kafka 分区子集,从而有效地并行处理。值得注意的是,,因此不需要线程间协调。
3)本地状态存储
Kafka Streams提供了所谓的,流处理应用程序可以使用它来存储和查询数据,这是实现有状态操作时的重要能力。Kafka Streams应用程序中的,这些本地状态存储可以通过 API 访问,以存储和查询处理所需的数据。Kafka Streams 为此类本地状态存储提供容错和自动恢复。
【例如】Kafka Streams DSL会在您调用有状态运算符(例如join()or aggregate())或窗口化流时自动创建和管理此类状态存储。
下图显示了两个流任务及其专用的本地状态存储:
4)容错
Kafka Streams建立在 Kafka 原生集成的容错功能之上。;因此,当流数据被持久化到 Kafka 时,即使应用程序失败并需要重新处理它,它仍然可用。Kafka Streams 中的任务利用 Kafka 消费者客户端提供的容错能力来处理故障。如果任务在失败的机器上运行,Kafka Streams 会自动在应用程序的剩余运行实例之一中重新启动任务。
四、简单应用(WordCount示例)
官网示例:https://kafka.apache.org/32/documentation/streams/quickstart 源代码:https://github.com/apache/kafka/blob/3.2/streams/examples/src/main/java/org/apache/kafka/streams/examples/wordcount/WordCountDemo.java
1)启动zookeeper和kafka(无鉴权)
$ cd $KAFKA_HOME
$ ./bin/zookeeper-server-start.sh -daemon ./config/zookeeper.properties
$ ./bin/kafka-server-start.sh ./config/server.properties
2)创建topic
创建名为streams-plaintext-input的输入topic和名为streams-wordcount-output的输出topic:
$ cd $KAFKA_HOME
$ bin/kafka-topics.sh --create \
--bootstrap-server hadoop-node1:19092 \
--replication-factor 1 \
--partitions 1 \
--topic streams-plaintext-input
$ bin/kafka-topics.sh --create \
--bootstrap-server hadoop-node1:19092 \
--replication-factor 1 \
--partitions 1 \
--topic streams-wordcount-output \
--config cleanup.policy=compact
【温馨提示】我们创建启用压缩的输出topic,因为输出流是一个变更日志流,对于具有相同键的多条记录,后面的每条记录都是对前一条记录的更新。
查看topic
$ bin/kafka-topics.sh --bootstrap-server hadoop-node1:19092 --describe
3)Maven依赖配置
<!-- (必需)Kafka 客户端库。包含内置的序列化器/反序列化器 -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.2.0</version>
</dependency>
<!-- (必需)Kafka Streams 的基础库 -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>3.2.0</version>
</dependency>
<!-- (可选)用于 Scala 库的 Kafka Streams DSL,用于编写 Scala Kafka Streams 应用程序。不使用 SBT 时,您需要在工件 ID 后缀上您的应用程序使用的正确版本的 Scala ( _2.12, _2.13) -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams-scala_2.13</artifactId>
<version>3.2.0</version>
</dependency>
4)修改源码
【温馨提示】这里主要修改BOOTSTRAP_SERVERS_CONFIG配置,如果使用带鉴权的kafka就得配置鉴权了。
/* * Licensed to the Apache Software Foundation (ASF) under one or more * contributor license agreements. See the NOTICE file distributed with * this work for additional information regarding copyright ownership. * The ASF licenses this file to You under the Apache License, Version 2.0 * (the "License"); you may not use this file except in compliance with * the License. You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */
package org.apache.kafka.streams.examples.wordcount;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.KTable;
import org.apache.kafka.streams.kstream.Produced;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.Arrays;
import java.util.Locale;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
/** * Demonstrates, using the high-level KStream DSL, how to implement the WordCount program * that computes a simple word occurrence histogram from an input text. * <p> * In this example, the input stream reads from a topic named "streams-plaintext-input", where the values of messages * represent lines of text; and the histogram output is written to topic "streams-wordcount-output" where each record * is an updated count of a single word. * <p> * Before running this example you must create the input topic and the output topic (e.g. via * {@code bin/kafka-topics.sh --create ...}), and write some data to the input topic (e.g. via * {@code bin/kafka-console-producer.sh}). Otherwise you won't see any data arriving in the output topic. */
public final class WordCountDemo {
public static final String INPUT_TOPIC = "streams-plaintext-input";
public static final String OUTPUT_TOPIC = "streams-wordcount-output";
static Properties getStreamsConfig(final String[] args) throws IOException {
final Properties props = new Properties();
if (args != null && args.length > 0) {
try (final FileInputStream fis = new FileInputStream(args[0])) {
props.load(fis);
}
if (args.length > 1) {
System.out.println("Warning: Some command line arguments were ignored. This demo only accepts an optional configuration file.");
}
}
props.putIfAbsent(StreamsConfig.APPLICATION_ID_CONFIG, "streams-wordcount");
//修改的地方
props.putIfAbsent(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop-node1:19092,hadoop-node2:19092,hadoop-node3:19092");
props.putIfAbsent(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, 0);
props.putIfAbsent(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
props.putIfAbsent(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
// setting offset reset to earliest so that we can re-run the demo code with the same pre-loaded data
// Note: To re-run the demo, you need to use the offset reset tool:
// https://cwiki.apache.org/confluence/display/KAFKA/Kafka+Streams+Application+Reset+Tool
props.putIfAbsent(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
return props;
}
static void createWordCountStream(final StreamsBuilder builder) {
final KStream<String, String> source = builder.stream(INPUT_TOPIC);
final KTable<String, Long> counts = source
.flatMapValues(value -> Arrays.asList(value.toLowerCase(Locale.getDefault()).split("\\W+")))
.groupBy((key, value) -> value)
.count();
// need to override value serde to Long type
counts.toStream().to(OUTPUT_TOPIC, Produced.with(Serdes.String(), Serdes.Long()));
}
public static void main(final String[] args) throws IOException {
final Properties props = getStreamsConfig(args);
final StreamsBuilder builder = new StreamsBuilder();
createWordCountStream(builder);
final KafkaStreams streams = new KafkaStreams(builder.build(), props);
final CountDownLatch latch = new CountDownLatch(1);
// attach shutdown handler to catch control-c
Runtime.getRuntime().addShutdownHook(new Thread("streams-wordcount-shutdown-hook") {
@Override
public void run() {
streams.close();
latch.countDown();
}
});
try {
streams.start();
latch.await();
} catch (final Throwable e) {
System.exit(1);
}
System.exit(0);
}
}
5)启动 Wordcount 应用程序
1、在IDEA启动应用程序 2、现在我们可以在一个单独的终端中启动控制台来向这个主题写入一些输入数据:
$ cd $KAFKA_HOME
$ bin/kafka-console-producer.sh --bootstrap-server hadoop-node1:19092 --topic streams-plaintext-input
输入以下数据:
all streams lead to kafka
3、并通过在单独的终端中使用控制台使用者来检查 WordCount 演示应用程序的输出:
$ cd $KAFKA_HOME
$ bin/kafka-console-consumer.sh --bootstrap-server hadoop-node1:19092 \
--topic streams-wordcount-output \
--from-beginning \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
6)通过jar包启动程序
将java文件打包成jar包,DIEA打包步骤如下:
- File->Project Structure->Artifacts
- Build->Build Artifacts(开始打包) 找到对应的jar包程序,放在$KAFKA_HOME/libs/目录下,运行程序 修改名称
$ mv kafka.jar $KAFKA_HOME/libs/WordCountDemo.jar
运行
$ cd $KAFKA_HOME
# 启动生产者
$ bin/kafka-console-producer.sh --bootstrap-server hadoop-node1:19092 --topic streams-plaintext-input
# 输入以下数据:
hello kafka streams
# 启动应用程序(数据处理,数据统计)
$ bin/kafka-run-class.sh bigdata.kstreams.com.WordCountDemo
# 如果没有修改配置,使用官方提供的以下命令
$ bin/kafka-run-class.sh org.apache.kafka.streams.examples.wordcount.WordCountDemo
# 启动另外一个客户端,显示输出(消费者)
$ bin/kafka-console-consumer.sh --bootstrap-server hadoop-node1:19092 \
--topic streams-wordcount-output \
--from-beginning \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
【总结】Kafka Streams的作用和目的就是数据分析与处理,充当着spark和flink等计算引擎的角色,但是目前企业里把kafka作为计算引擎不多,还是传统用法多(数据缓冲、解耦、异步通信),所以kafka在计算引擎全面化落地还有很长的路要走。期待kafka的一体化实现(数据解耦+数据计算和分析)。
Kafka Streams的介绍就先到这里了,后续会有更全面的kafka API介绍和操作,有疑问的小伙伴,欢迎给我留言哦~