我的博客园:https://www.cnblogs.com/MaplesWCT/
A Survey on Federated Learning: The Journey From Centralized to Distributed On-Site Learning and Beyond
| Authors | Sawsan AbdulRahman, Hanine Tout, Hakima Ould-Slimane, Azzam Mourad, Chamseddine Talhi, Mohsen Guizani |
|---|---|
| Keywords | AI; DL; distributed intelligence; FL applications; FL; ML; privacy; resource management; security; |
| Abstract | 在隐私问题和深度学习愿景的推动下,近四年见证了机器学习适用机制的范式转变,称为联邦学习(FL)新兴模式正在超越集中系统和on-site分析。这是一种分散隐私的方法。它将原始数据保留在机器上,训练本地模型,减轻数据通信的负担,然后在中央服务器上学习和共享模型,以聚合和共享参与者之间构建的知识。本文首先基于不同的检查和比较ML部署架构,然后对FL深入广泛的调查。与现有评论相比,我们在全面分析主要技术挑战和当前相关工作的基础上FL对学科和研究领域进行了新的分类。在此背景下,我们详细阐述了核心系统模型与设计、应用领域、隐私与安全、资源管理等具有挑战性的方面、贡献与趋势。此外,为了实现更强大,我们还讨论了一些重要的挑战和开放的研究方向FL系统。 |
| Publication | INTERNET OF THINGS JOURNAL 2021 |
| DOI | 10.1109/jiot.2020.3030072 |
1 INTRODUCTION
如今,人们通过各种互联设备生产了大量的数据,AI让我们的生活更有效率。随着深度学习的快速发展,现有的方法继续支持云中心架构,集中存储和处理数据。除了不可接受的延迟和高成本外,数据隐私和安全也是主要问题。
没有严格的隐私考虑,敏感数据很容易泄露、攻击和网络风险。自21世纪以来,数亿大公司的用户受到了影响。在这种环境下,欧盟发布了它GDPR法规( General Data Protection Regulation),它通过设置规则、限制数据共享和存储来保护个人隐私。
进一步加强数据保护章制度的数据保护,on-site ML和FL已经发展起来代替集中式系统。
尽管on-site ML在本地保留原始数据,发布云ML任务给设备,但每个设备都建立自己的模型,不从其他设备的数据和经验中受益。
因此联邦学习(FL)克服这些问题些问题,保护了隐私,减轻了数据收集的负担。它是训练数据和本地计算处理的分散方法。FL在中间,原始数据保留在设备本地。在中央服务器上,只接收设备本地计算的更新和分析结果,并聚合成一个强化的全球模型,然后共享新模型。
现有与当前工作相关的调查文章概述:
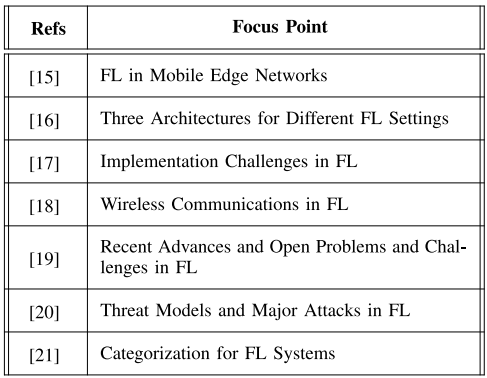
但文献仍然缺乏正确的文献FL对核心建模、应用、技术和部署的综合调查,提出了新的分类和关键挑战,包括核心系统模型和设计、应用、隐私、安全和资源管理。本文的主要贡献如下:
- 详细阐述了基础ML对部署架构的演变进行分析FL范式对当前研究和行业趋势中的努力和贡献进行了分类FL对核心系统模型和设计的关键技术设计的关键技术。我们进一步讨论了下一代FL解决方案铺平道路的挑战和有趣的开放研究方向。研究方向依据FL对系统模型与设计、应用、隐私与安全、资源管理等领域和主题进行分类。
- 建立了一个FL到目前为止,应用领域的分类系统已经被引入FL方法的所有领域。
- 确定和分析FL解决隐私和安全问题的关键贡献。确定和分析FL解决隐私和安全问题的关键贡献。
- 我们对为FL全面分析提出的资源管理机制,并根据目标函数和考虑的参数对优化方法进行分类。
2 机器学习结构的演变
本部分阐述ML架构的演变,从集中到分布式on-site到FL。
- 集中式ML:数据上传到云端,在云端训练模型,用户通过请求API模型模型和服务的方式。
- 分布式on-site学习:每个设备都用自己的数据在当地训练自己的模型第一次将初始模型发送到云中后,设备不再需要与云通信。
- 联邦学习:每个设备用自己的数据训练自己的模型,然后将模型参数发送到中央服务器进行聚合。数据保留在本地,知识通过聚合模型与用户共享。
2.1 集中式学习
在传统方法下,设备产生的数据不断上传到云中进行分析,可以从高性能服务器中提取更多的特性,更好地培训模型。Amazon Web Services、Google Cloud、Microsoft Azure都是可用的ML也就是说,模型可以大规模部署和使用服务提供商。
然而,设备生成的数据可能非常私密和多样化。当这些数据在云上共享时,用户隐私可能会因窃听攻击而妥协。这种集中方式还存在其他问题:
- 延迟。数据可能需要传输数千英里的云。
- 数据传输代价。将数据移入移出云都需要代价。
2.2 分布式on-site学习
on-site ML在中间,服务器向设备发布预训练或通用模型。部署模型后,每个设备使用自己的数据在当地训练自己的模型,然后根据自己的模型些预测和推理。
这种方法在隐私方面有明显的优势,数据从未离开过本地。已应用于皮肤病检测、医疗应用、指挥课堂、神经网络辅助服务等。
然而,在这种方法下,设备模型没有从其他设备的数据中受益,也没有发挥群体智慧。
2.3 联邦学习
Google在2016年提出了FL。在on-site ML之上,FL它还将训练任务放在设备本地,但同时将本地模型与学习相结合。它的主要目标是建立一个隐私保护ML的框架。
3 预备:FL框架及设计
本部分介绍FL流程、产品应用及正式问题声明。
3.1 产品应用及开源框架
FL首先在Gboard(Google测试安卓开发的键盘),FL加强未来建议功能和与用户的互动,提供更好的特点(如下一个词预测、词汇补充和修正等。
FL开源框架有:tensorflow federated(TFF),federated AI technology enabler(FATE),PySyft,PaddleFL,Clara训练框架。
在科研界,图片分类和语言模型是最先广泛应用基于FL为了测试它们的性能,手写字符Modified National Institute of Standards and Technology(MNIST)对图片the Canadian Institute For Advanced Research(CIFAR)是文献实验中最流行的数据集。
3.2 FL生命周期和协议
FL生命周期分为许多连续通信(round),一旦全局模型达到预期准确性,流程就完成了。服务器首先生成一个通用模型,每轮(round)重复以下步骤:
- 服务器选取部分客户机。尽管客户机选择的典型条件是基于设备充电、空闲和未测量的连接状态,但是很少有这方面的工作。
- 选定的客户机从服务器下载当前模型参数并初始化本地模型。
- 选定的客户机采用本地数据培训,优化全局模型。在大多数典型的技术中,客户机采用随机梯度下降算法(SGD)计算更新。由于通信带宽的限制,每个梯度上传服务器带宽是不够的,所以在一轮(round)中采用mini-batch在这台机器上多训练几个epoch通过上传服务器,可以更好地更新模型,降低通信成本。
- 一旦培训完成,客户机将优化的模型参数发送给服务器。在此过程中,由于连接差、有限的计算资源和大量的培训数据,一些客户机器可能会脱机,因此超出服务器控制的客户机器的停机率将被报告并继续处理。如果及时报告的客户机数量不够,则当前轮(round)终止。/li>
- 服务器在根据客户机的数据集大小对其进行加权后,聚合客户机更新(即联邦平均算法)。新的全局模型诞生,投入下一轮。
算 法 1 : F e d e r a t e d A v e r a g i n g 算 法 ( F e d A v g ) 。 K 个 客 户 端 编 号 为 k ; B , E , η 分 别 代 表 本 地 的 m i n i b a t c h s i z e , e p o c h s , 学 习 率 l e a r n i n g r a t e 服 务 器 执 行 : 初 始 化 w 0 f o r 每 轮 t = 1 , 2 , . . . , d o m ← m a x ( C ⋅ K , 1 ) / / C 为 比 例 系 数 S t ← ( 随 机 选 取 m 个 客 户 端 ) f o r 每 个 客 户 端 k ∈ S t 同 时 d o w t + 1 k ← 客 户 端 更 新 ( k , w t ) w t + 1 ← ∑ k = 1 K n k n w t + 1 k / / n k 为 客 户 机 k 上 的 样 本 数 量 , n 为 所 有 被 选 中 客 户 机 的 总 样 本 数 量 客 户 端 更 新 ( k , w ) : ▹ 在 客 户 端 k 上 运 行 β ← ( 将 P k 分 成 若 干 大 小 为 B 的 b a t c h ) / / P k 为 客 户 机 k 上 数 据 点 的 索 引 集 , P k 大 小 为 n k f o r 每 个 本 地 的 e p o c h i ( 1 ∼ E ) d o f o r b a t c h b ∈ β d o w ← w − η ▽ l ( w ; b ) / / ▽ 为 计 算 梯 度 , l ( w ; b ) 为 损 失 函 数 返 回 w 给 服 务 器 \begin{aligned} & 算法1:Federated\ Averaging算法(FedAvg)。 \\ & K个客户端编号为k;B,E,\eta分别代表本地的minibatch\ size,epochs,学习率learning\ rate \\ & \\ & 服务器执行:\\ & \quad 初始化w_0 \\ & \quad for \ 每轮t=1,2,...,do \\ & \qquad m \leftarrow max(C \cdot K,1) \qquad\qquad //C为比例系数 \\ & \qquad S_t \leftarrow (随机选取m个客户端) \\ & \qquad for \ 每个客户端k \in S_t 同时\ do \\ & \qquad \qquad w^k_{t+1} \leftarrow 客户端更新(k,w_t) \\ & \qquad w_{t+1} \leftarrow \sum^K_{k=1} \frac{n_k}{n} w^k_{t+1} \qquad\qquad //n_k为客户机k上的样本数量,n为所有被选中客户机的总样本数量\\ & \\ & 客户端更新(k,w): \qquad \triangleright 在客户端k上运行 \\ & \quad \beta \leftarrow (将P_k分成若干大小为B的batch) \qquad\qquad //P_k为客户机k上数据点的索引集,P_k大小为n_k \\ & \quad for\ 每个本地的epoch\ i(1\sim E) \ do \\ & \qquad for\ batch\ b \in \beta \ do \\ & \qquad \qquad w \leftarrow w-\eta \triangledown l(w;b) \qquad\qquad //\triangledown 为计算梯度,l(w;b)为损失函数\\ & \quad 返回w给服务器 \end{aligned} 算法1:Federated Averaging算法(FedAvg)。K个客户端编号为k;B,E,η分别代表本地的minibatch size,epochs,学习率learning rate服务器执行:初始化w0for 每轮t=1,2,...,dom←max(C⋅K,1)//C为比例系数St←(随机选取m个客户端)for 每个客户端k∈St同时 dowt+1k←客户端更新(k,wt)wt+1←k=1∑Knnkwt+1k//nk为客户机k上的样本数量,n为所有被选中客户机的总样本数量客户端更新(k,w):▹在客户端k上运行β←(将Pk分成若干大小为B的batch)//Pk为客户机k上数据点的索引集,Pk大小为nkfor 每个本地的epoch i(1∼E) dofor batch b∈β dow←w−η▽l(w;b)//▽为计算梯度,l(w;b)为损失函数返回w给服务器
3.3 问题公式化
FL关注有监督ML,样本 i i i特征向量为 x i x_i xi,标签为 y i y_i yi,训练目标是通过最小化损失函数 f i ( w ) f_i(w) fi(w)来找到模型参数向量 w w w。基于ML模型,问题可以是凸的和非凸的。由于FL建立在非凸神经网络上,它的有限和函数优化算法描述如下(整个样本集的平均损失函数值最小): min f ( w ) , where f ( w ) = 1 n ∑ i = 1 n f ( x i , y i , w ) f ( w ) = 1 n ∑ i = 1 n f i ( w ) \begin{aligned} \min f(w), \quad \text { where } \quad f(w) &=\frac{1}{n} \sum_{i=1}^{n} f\left(x_{i}, y_{i}, w\right) \\ f(w) &=\frac{1}{n} \sum_{i=1}^{n} f_{i}(w) \end{aligned} minf(w), where f(w)f(w)=n1i=1∑nf(xi,yi,w)=n1i=1∑nfi(w) 在FL里客户机的数据从未被组装,所以上式需要修改一下。设 K K K个客户机参与学习,每个客户机有 n k = ∣ P k ∣ n_k=|P_k| nk=∣Pk∣个样本, P k P_k Pk是整个数据集 P P P分配给客户机 k k k的部分, P = ∪ k = 1 K P k P=\cup_{k=1}^{K} P_{k} 标签: 流量传感器p11146st智能型压力变送器cyb