论文名称:TCCT: Tightly-coupled convolutional transformer on time series forecasting 论文下载:https://doi.org/10.1016/j.neucom.2022.01.039 论文年份:2021 1(2022/05/01) 论文代码:https://github.com/OrigamiSL/TCCT2021
论文总结
TCCT:时间序列预测的紧耦合卷积 Transformer
松耦合:模型只使用常用 CNN 例如,应用标准卷积层和最大池化层 Transformer,或以其他方式顺序或并行堆叠 CNN 块和 Transformer 块。松耦法在一定程度上得到了改进 Transformer 性能模型。
紧耦:只有在 Transformer 模型中应用,才能将 Transformer 和 CNN 紧密结合,充分发挥其优势。
其基于 Informer 和 LogSparseTransformer,这两篇论文在之前的博这两篇论文。然后再融合 CSPNet,TCN 扩张因果卷积 和 Yolov两种直通机制。其中,CSPNet 在此基础上提出 CSPAttention,降低内存复杂性,提高预测精度;扩展因果卷积用于增加指数的感觉野;直通机制取代 Informer 原蒸馏机制。提高计算效率,降低内存复杂性。
Abstract
Time series forecasting is essential for a wide range of real-world applications. Recent studies have shown the superiority of Transformer in dealing with such problems, especially long sequence time series input (LSTI) and long sequence time series forecasting (LSTF) problems. To improve the efficiency and enhance the locality of Transformer, these studies combine Transformer with CNN in varying degrees. However, their combinations are loosely-coupled and do not make full use of CNN. To address this issue, we propose the concept of tightly-coupled convolutional Transformer (TCCT) and three TCCT architectures which apply transformed CNN architectures into Transformer: (1) CSPAttention: through fusing CSPNet with self-attention mechanism, the computation cost of self-attention mechanism is reduced by 30% and the memory usage is reduced by 50% while achieving equivalent or beyond prediction accuracy. (2) Dilated causal convolution: this method is to modify the distilling operation proposed by Informer through replacing canonical convolutional layers with dilated causal convolutional layers to gain exponentially receptive field growth. (3) Passthrough mechanism: the application of passthrough mechanism to stack of self-attention blocks helps Transformer-like models get more fine-grained information with negligible extra computation costs. Our experiments on real-world datasets show that our TCCT architectures could greatly improve the performance of existing state-of-the-art Transformer models on time series forecasting with much lower computation and memory costs, including canonical Transformer, LogTrans and Informer.
时间序列预测对于广泛的实际应用至关重要。最近的研究表明, 特别是在处理这些问题方面具有优势。为了。但是,它们的组合是。为了解决这个问题,我们提出了这个问题和三个:
-
1)CSPAttention:通过。
-
2)因果卷积的扩张(Dilated causal convolution):这种方法是通过的。
-
3)直通机制(Passthrough mechanism):。
我们在真实世界数据集中的实验表明,我们 TCCT 现有最先进的架构可以大大提高 Transformer 在时间序列预测中,模型的性能降低了计算和内存成本,包括规范 Transformer,LogTrans 和 Informer。
1. Introduction
时间序列预测股市预测 [1]事件驱动的情绪分析 [2]工业资产监测 [3]卫星图像分类 [4] 许多其他领域都发挥着重要作用。在大数据时代,时间序列预测模型开始面临所以场景。为了满足长期预测的需要,包括 ARIMA [5,6] 和 SSM [7] 在内的。
基于深度神经网络的模型是解决上述问题的好候选人,特别是 Transformer 模型 [8-11]。与 CNN [12-14] 或 RNN [15-17] 与时间序列预测模型相比,。但是,Transformer 自注机制也带来了。当模型堆叠几个自注意力块时,情况会变得更糟。。
为了,最近提出了很多研究。。但是,现有的相关模型大多是。这里的松耦合意味着。
-
LogTrans [10] 线性投影用因果卷积层代替查询、键和值。 Informer [11] 使用标准卷积层和最大标准卷积层化层来连接自注意力块。
-
DS-Net [20] 分别使用基于 CNN 的网络和基于 Transformer 的网络生成特征图。
-
TransCNN [21] 将池化层应用于自注意力机制,并将自注意力块与由深度卷积层和最大池化层组成的 TDB 和 IRB 块连接起来。。
毫无疑问,。然而,。因此,在本文中,我们试图回答这个问题:?
为此,我们的工作深入研究了 Transformer 和 CNN 的紧密结合。在我们的工作中,转换后的三个经典 CNN 架构已成功应用于时间序列预测的 Transformer 模型。本文的贡献可以总结如下:
- 我们提出了 和的想法。转换后,这些架构不仅,“松耦合”方法也可以做到这一点,而且。它们也,可以处理其他类似 Transformer 的时间序列预测模型。
- 我们。它减少了近 30% 的内存占用和 50% 的 self-attention 机制的时间复杂度,同时实现了同等或更高的预测精度。
- 我们提出了。它帮助 Transformer 模型。因此,Transformer 的学习能力得到了加强。
- 我们提出了。。
2. Related works
2.1. Time series forecasting
由于时间序列预测在许多领域的广泛存在,人们提出了各种方法来解决时间序列预测问题。[5-7,22]。还存在受机器学习算法启发的方法,例如支持向量机 [1] 和分层贝叶斯方法 [23]。由于近来。流行的基于深度学习的方法主要基于 RNN [17,24–26]。与传统模型相比,它们取得了更好的性能,尤其是在处理多变量时间序列预测问题时,但在面对长序列时间序列输入(long sequence time series input,LSTI)或长序列时间序列预测( long sequence time series forecasting ,LSTF)问题时仍然不够好。为了寻找和建立输出和输入之间的长程依赖关系,。
2.2. Transformer models on time series forecasting
近年来已经提出了几种 Transformer 模型来解决时间序列预测问题。它们主要来自 Vaswani Transformer [27],基本上没有什么变化 [9,28,29]。 。 。这是我们的工作旨在解决的主要限制。然而,不可否认它们是最先进的,因此,,特别是更具竞争力的 Informer。
2.3. Related CNN
卷积神经网络 [18,30–32] 在处理计算机视觉问题时具有举足轻重的地位。在这么多伟大的作品中,我们想强调两个与我们的工作密切相关的 CNN 架构,。尽管计算机视觉和时间序列预测是完全不同的任务,但可以借鉴这两种 CNN 架构的一些好主意。 。在我们的论文中,类似的概念也。 Yolo 系列卷积网络是非常著名的实时目标检测器。即使是现在,最先进的基于 Yolo 或与 Yolo 相关的对象检测器也不断被提出,例如 PP-YOLOv2 [37]、YOLOS [38] 等。而不是将整个 Yolo 基线应用到 Transformer 架构中,我们只是编码器内的自注意力块堆栈。除了计算机视觉,CNN还在时间序列预测任务中占有一席之地,例如。
3. Preliminary
3.1. Problem definition
在介绍 Methodology 之前,我们首先提供时间序列预测问题的定义。假设我们有一个固定的输入窗口 { z i , 1 : t 0 } i = 1 N \{z_{i,1:t_0}\}^N_{i=1} { zi,1:t0}i=1N,任务是预测对应的固定目标窗口 { z i , t 0 + 1 : t 0 + T } i = 1 N \{z_{i,t_0+1:t_0+T}\}^N_{i=1} { zi,t0+1:t0+T}i=1N。 N 是指相关单变量时间序列的数量,t0 是输入窗口大小,T 是预测窗口大小。给定一个长度远大于预设输出窗口大小的长目标序列,采用滚动预测策略对整个序列进行预测。
3.2. Informer architecture
Informer 是从规范 Transformer [27] 派生的时间序列预测模型。 。由于其最先进的性能,我们将其。我们将简要介绍其,并请读者参考 [11] 了解更多详细信息。总结了四点。
A. 。 ProbSparse self-attention 。判断主导查询的方法是。。。
B. 除此之外,。。这样,。
C. 为了,Informer 也可以。第 i 个额外的编码器堆叠 k-i 个自注意力块,它的输入是主编码器输入的最后 1 / 2 i 1/2^i 1/2i,因此所有编码器的输出长度相同。我们将这种替代方法称为完全蒸馏操作以供后续使用。
D. 除了上述变化外,。解码器的输入向量由两部分组成,起始标记(token)和目标序列。。
具有完全蒸馏操作(distilling operation)和 3 层主编码器的 Informer 的总体架构如图 1 所示。 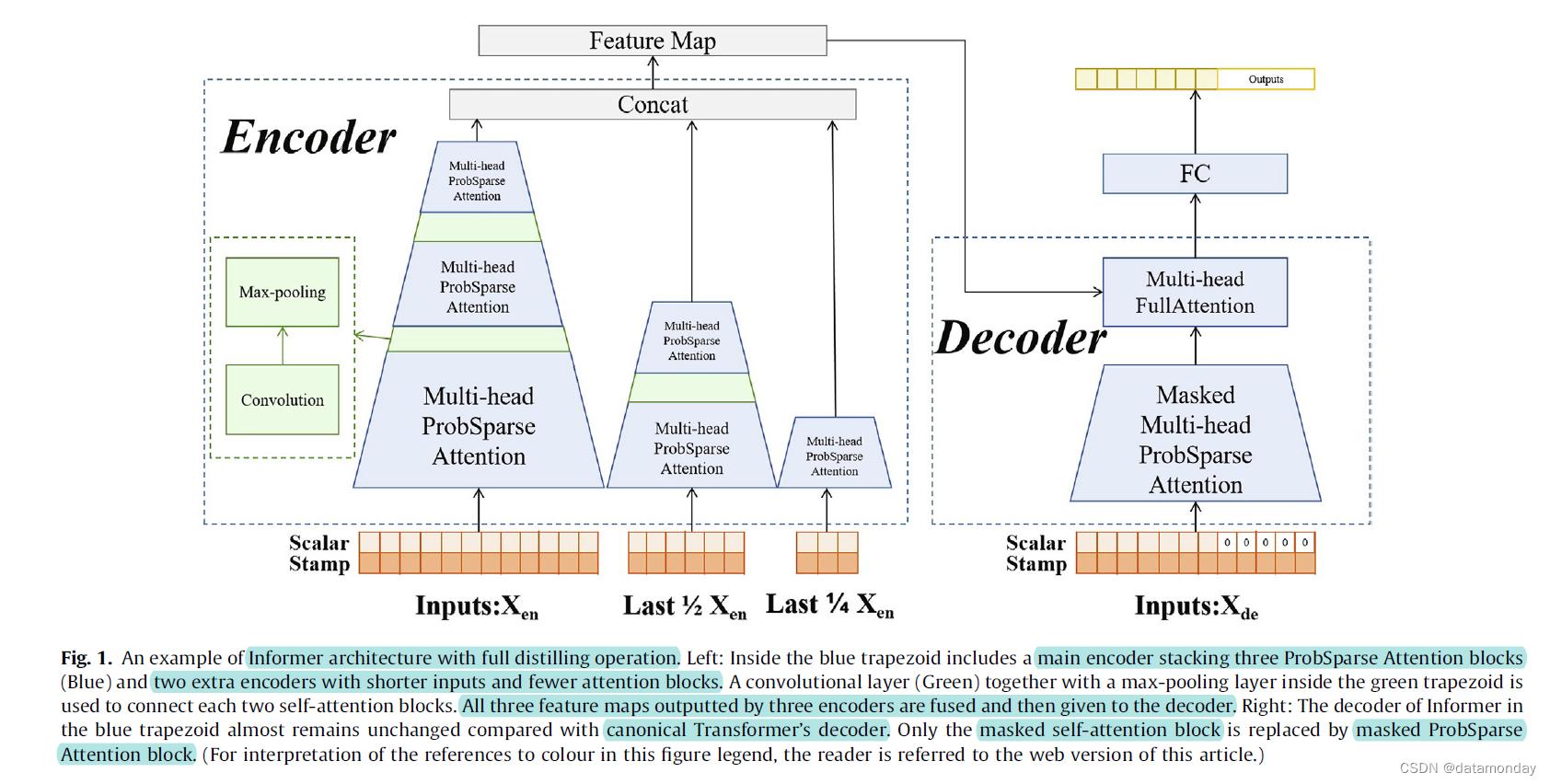 图 1. 具有完全蒸馏操作的 Informer 架构示例。左:蓝色梯形内部包括一个主编码器,堆叠了三个 ProbSparse Attention 块(蓝色)和两个额外的编码器,输入更短,注意力块更少。绿色梯形内的卷积层(绿色)和最大池化层用于连接每两个自注意力块。。右图:蓝色梯形中 Informer 的解码器与标准 Transformer 的解码器相比几乎没有变化。只有被掩蔽的自注意力块被掩蔽的 ProbSparse Attention 块替换。有关此图例中颜色参考的解释,请读者参考本文的网络版本。
图 1. 具有完全蒸馏操作的 Informer 架构示例。左:蓝色梯形内部包括一个主编码器,堆叠了三个 ProbSparse Attention 块(蓝色)和两个额外的编码器,输入更短,注意力块更少。绿色梯形内的卷积层(绿色)和最大池化层用于连接每两个自注意力块。。右图:蓝色梯形中 Informer 的解码器与标准 Transformer 的解码器相比几乎没有变化。只有被掩蔽的自注意力块被掩蔽的 ProbSparse Attention 块替换。有关此图例中颜色参考的解释,请读者参考本文的网络版本。
4. Methodology
我们首先依次介绍三种紧耦合卷积变换器(TCCT)架构:CSPAttention、扩张因果卷积和直通机制。然后将展示将 TCCT 架构与类似 Transformer 的时间序列预测模型相结合的方法。
4.1. CSPAttention
图 2. CSPAttention 块。输入(蓝色)分为两部分。第一个(绿色)通过 A 层传播,一个 1×1 卷积层,而另一个(红色)通过块 B 传播,一个自注意力块。最后将两个部分的输出连接在一起,作为整个 CSPAttention 块的最终输出。
我们提出的 CSPAttention 的一个块的架构如图 2 所示**。输入 R L × d R^{L \times d} RL×d,其中 L L L 是输入长度, d d d 是输入维度,通过维度 X = [ X 1 L × d 1 , X 2 L × d 2 ] X = [X^{L \times d_1}_1, X^{L \times d_2}_2] X=[X1L×d1,X2L×d2] 分为两部分。 X 1 X_1 X1 在经过一个 1×1 卷积层 A 后链接到块的末端,而 X 2 X_2 X2 充当self-attention block B 的输入。A 和 B 的输出通过维度连接起来作为整个block的输出**。
排除偏差,CSPAttention 的一个阶段的输出矩阵由下式给出 。整个输出 。此外,。 CSPAttention 的权重更新如下图所示: 其中 f 是权重更新函数,g 表示传播到第 i 条路径的梯度。可以看出,分割部分的梯度是分别积分的。 。CSPNet 已经展示了它在提高性能和减少基于 CNN 架构的计算方面的能力。我们的 CSPAttention 还降低了自注意力机制的内存流量和时间复杂度。假设一个规范的自注意力块的输入和输出维度都是 d 并且只有一个输入标记。如图 3(a) 所示,。因此,内存占用为 4 d 2 4d^2 4d2。然而,。相应的架构如图 3(b) 所示。因此,。
定理1。假设 CSPAttention 将输入维度分成两半,与规范的 self-attention 块相比,它至少减少了 50% 的时间复杂度。
证明推迟到附录 A。定理 1 意味着 。 CSPAttention 还可以应对其他类似 Transformer 的架构,并将它们升级为紧耦合卷积 Transformer 架构。我们以 LogTrans [10] 为例,。。它们相互独立,因此在图 4 中,LogSparse 自注意力可以直接替代图 2 中的规范自注意力。同样,当将 CSPAttention 应用于 Informer 时,ProbSparse 自注意力将升级为 ProbSparse CSPAttention。更重要的是,。
4.2. Dilated causal convolution
。为了进一步减少内存使用,。 。步长为 1 的内核大小为 3 的卷积层遵循前一个自注意块,以使特征更加了解局部上下文信息。。堆叠三个自注意力块的网络如图 5 所示。为简单起见,我们。
然而,。首先,。因此,。。
我们的解决方案。更正式地说,对于第 i 个自注意力块之后的第 i 个卷积层,序列 X ∈ R L × d X \in \R^{L \times d} X∈RL×d 的元素 x n ∈ R d x_n \in \R^d xn∈Rd 上的内核大小为 k k k 的扩张因果卷积运算 C C C 定义为: 。第 i 个扩张的因果卷积层的过滤器在两个相邻的过滤器抽头(filter taps)之间跳过 ( 2 i − 1 − 1 2^{i-1}-1 2i−1−1) 个元素。此外,。请注意,。我们在图 6 中提供了一个堆叠三个自注意力块并使用内核 3 的扩张因果卷积层的网络的图示。 比较图 5 和图 6,可以清楚地看出,。即使只有两个卷积层,。因此,堆叠更多的自注意块,差距会更大,因此,两个网络的表现会更好。除此之外,扩张因果卷积的应用只会带来少许的计算成本和内存使用(填充成本),可以忽略不计。
。
4.3. Passthrough mechanism
。类似的概念可以应用于基于 Transformer 的网络。 。
。假设一个编码器堆叠了 n 个自注意力块,那么每个自注意力块都会产生一个特征图。假设 CSPAttention 和扩张因果卷积已应用于该编码器,则第 k 个(k = 1,2. . .n)特征图的长度为 L / 2 k − 1 L/2^{k-1} L/2k−1,维度为 d d d。。这样,。但是,连接的特征图的维度为 ( 2 n − 1 ) × d (2^n - 1) \times d (2n−1)×d,。我们提出了一个堆叠三个自注意力块的网络,并采用了上面提到的所有 TCCT 架构,如图 7 所示。 。但是,。尽管。例如,假设 Informer 堆叠了 k 个编码器,则输入序列的前半部分仅存在于主编码器中,相反,输入序列的后 1 / 2 k − 1 1/2^{k-1} 1/2k−1 存在于每个单个编码器中。直通机制没有这样的不足。更重要的是,。
4.4. Transformer with TCCT architectures
以上所有架构都可以与 Transformer 或类 Transformer 的时间序列预测模型无缝协作,包括规范的 Transformer、LogTrans、Informer 等。与 Informer 协作的简单示例如图 8 所示,详细的编码器示例如图 9 所示。。 。例如,为了将 TCCT 架构与 LogTrans 相结合,图 8 中的(掩码)ProbSparse 自注意力块将被(掩码)LogSparse 自注意力块替换,其他架构保持不变。
5. Experiment
5.1. Datasets
我们主要在一个公共的真实世界 ETT1(电力Transformer温度)数据集上进行实验,该数据集由持续近 2 年的 ETT 数据组成。 。每个数据点由目标值“油温”和其他 6 个功率负载特征组成。在网络训练/验证/测试期间使用具有 Z 分数归一化的原始数据。。
更具体地说,上面的数据集在时间上被均匀、连续和紧凑地分割。训练子集包含前 12 个月的数据,验证子集包含接下来 4 个月的数据,测试子集包含最后 4 个月的数据。数据集的更详细信息显示在附录 D 中。
5.2. Methods
我们选择 Informer 作为基本基线,并分别测试我们提出的 TCCT 架构应对它的效果。 。广泛研究我们的 TCCT 架构可以在多大程度上改进 Informer。因此,选择了五种方法:
- Informer,只有一个编码器的基本 Informer
- Informer+,完全蒸馏操作的Informer
- TCCT_I,Informer 结合 CSPAttention
- TCCT_II,Informer 结合 CSPAttention 和扩张的因果卷积
- TCCT_III,Informer 与所有 TCCT 架构相结合。
在没有异常指令的情况下,Informer、TCCT_I、TCCT_II、TCCT_III 包含一个编码器堆叠 3 个自注意力块,而 Informer + 包含一个具有完全蒸馏操作的 3 编码器堆栈。此外,每个方法都包含一个 2 层解码器。
。此外,为了进一步研究我们提出的 TCCT 架构在增强其他 Transformer 或类似 Transformer 的模型在时间序列预测方面的适用性,。源代码位于 https://github.com/OrigamiSL/TCCT2021
5.3. Experiment details
进行了,以检查 TCCT 架构在时间序列预测方面为 Transformer 或类 Transformer 模型带来的预测准确性和效率的改进。。所有方法都。解码器的起始令牌长度与编码器的输入长度保持一致。 。。所有实验均在单个 Nvidia GTX 1080Ti 12 GB GPU 上进行。进一步的具体细节在具体实验中显示。
5.4. Result and analysis
5.4.1. Ablation study on LSTF problem
在此设置下,将在单变量和多变量条件下评估五种方法的时间序列预测能力,从而说明三种 TCCT 架构分别提高 Informer 的预测准确度有多大。 ETTh1 和 ETTm1 数据集都用于检查。。选择 。 n 是指预测窗口大小。如果需要,还选择这两个标准来评估以下实验中的预测准确性。