module Shift_RAM_3X3( //global signals input clk, input rst_n, //Image data prepred to be processd input per_frame_vsync, //Prepared Image data vsync valid signal input per_frame_href, //Prepared Image data href vaild signal input per_frame_clken, //Prepared Image data output/capture enable clock input [7:0] per_img_Y, //Prepared Image brightness input //Image data has been processd output matrix_frame_vsync, //Prepared Image data vsync valid signal output matrix_frame_href, //Prepared Image data href vaild signal output matrix_frame_clken, //Prepared Image data output/capture enable clock output reg [7:0] matrix_p11, output reg [7:0] matrix_p12, output reg [7:0] matrix_p13, //3X3 Matrix output output reg [7:0] matrix_p21, output reg [7:0] matrix_p22, output reg [7:0] matrix_p23, output reg [7:0] matrix_p31, output reg [7:0] matrix_p32, output reg [7:0] matrix_p33 ); //---------------------------------------------- //consume 1clk wire [7:0] row1_data;//frame data of the 1th row
wire [7:0] row2_data;//frame data of the 2th row
reg [7:0] row3_data;//frame data of the 3th row
// ====================================================================================================
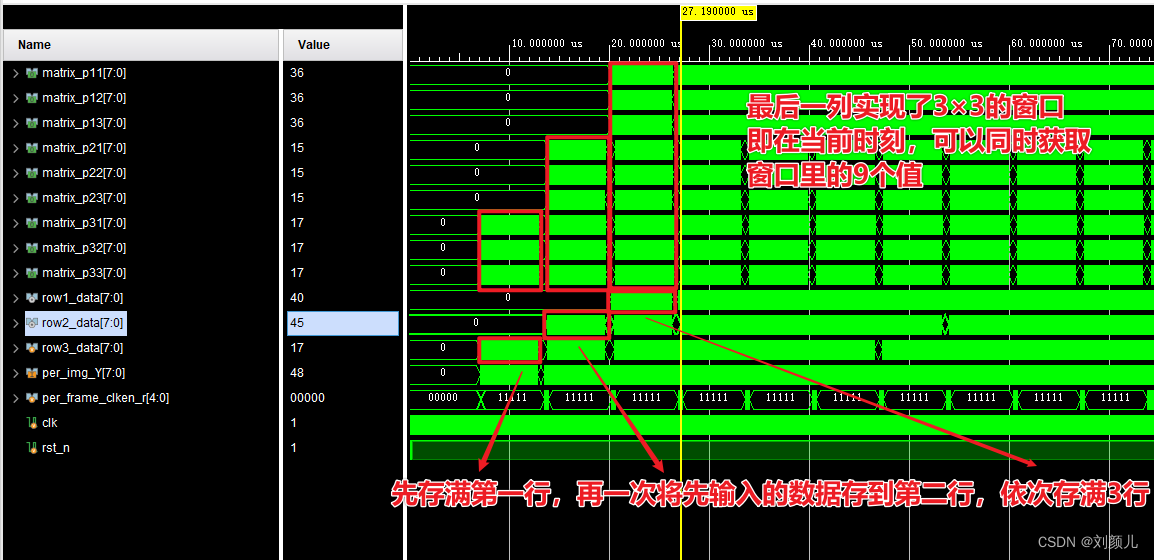
// 得到一个3×n的矩阵
// ====================================================================================================
// 将正在输入的Y值给data_3,data_3一直在最上面那一行
always @(posedge clk or negedge rst_n)begin
if(!rst_n)
row3_data <= 8'b0;
else begin
if(per_frame_clken)
row3_data <= per_img_Y;
else
row3_data <= row3_data;
end
end
//Shift_RAM_3X3_8bit1
//在这个IP和内部会先将输入的data_3存到RAM中,等存满一行后,就将data_3给data_2进行输出
Shift_RAM_3X3_8bit u1_Shift_RAM_3X3_8bit (
.D (row3_data), // 输入的灰度Y,即当前正在输入的那一行
.CLK (per_frame_clken & clk), // input wire CLK
.Q (row2_data) // output wire [7 : 0] Q
);
//Shift_RAM_3X3_8bit2
Shift_RAM_3X3_8bit u2_Shift_RAM_3X3_8bit (
.D (row2_data), // input wire [7 : 0] D
.CLK (per_frame_clken & clk), // input wire CLK
.Q (row1_data) // output wire [7 : 0] Q
);
// ====================================================================================================、、
//per_clken delay 3clk
reg [4:0]per_frame_clken_r;
reg [4:0]per_frame_vsync_r;
reg [4:0]per_frame_href_r;
always @(posedge clk or negedge rst_n)begin
if(!rst_n)begin
per_frame_clken_r <= 5'b0;
per_frame_vsync_r <= 5'b0;
per_frame_href_r <= 5'b0;
end
else begin
per_frame_clken_r <= {
per_frame_clken_r[3:0], per_frame_clken};
per_frame_vsync_r <= {
per_frame_vsync_r[3:0], per_frame_vsync};
per_frame_href_r <= {
per_frame_href_r [3:0], per_frame_href};
end
end
assign matrix_frame_clken = per_frame_clken_r[4];
assign matrix_frame_href = per_frame_href_r [4];
assign matrix_frame_vsync = per_frame_vsync_r[4];
/**************************************** (1)read data from shift_RAM (2)caulate the sobel (3)steady data after sobel generate ******************************************/
// 将那3行数据进行打拍
always @(posedge clk or negedge rst_n)begin
if(!rst_n)begin
{
matrix_p11, matrix_p12, matrix_p13} <= 24'h0;
{
matrix_p21, matrix_p22, matrix_p23} <= 24'h0;
{
matrix_p31, matrix_p32, matrix_p33} <= 24'h0;
end
else if(per_frame_clken_r[3])begin //shift_RAM data read clock enbale
{
matrix_p11, matrix_p12, matrix_p13} <= {
matrix_p12, matrix_p13, row1_data};//1th shift input
{
matrix_p21, matrix_p22, matrix_p23} <= {
matrix_p22, matrix_p23, row2_data};//2th shift input
{
matrix_p31, matrix_p32, matrix_p33} <= {
matrix_p32, matrix_p33, row3_data};//3th shift input
end
else begin
{
matrix_p11, matrix_p12, matrix_p13} <= {
matrix_p11, matrix_p12, matrix_p13};
{
matrix_p21, matrix_p22, matrix_p23} <= {
matrix_p21, matrix_p22, matrix_p23};
{
matrix_p31, matrix_p32, matrix_p33} <= {
matrix_p31, matrix_p32, matrix_p33};
end
end
endmodule