作者丨柒柒@知乎
来源丨https://zhuanlan.zhihu.com/p/447555827
编辑丨3D视觉工坊
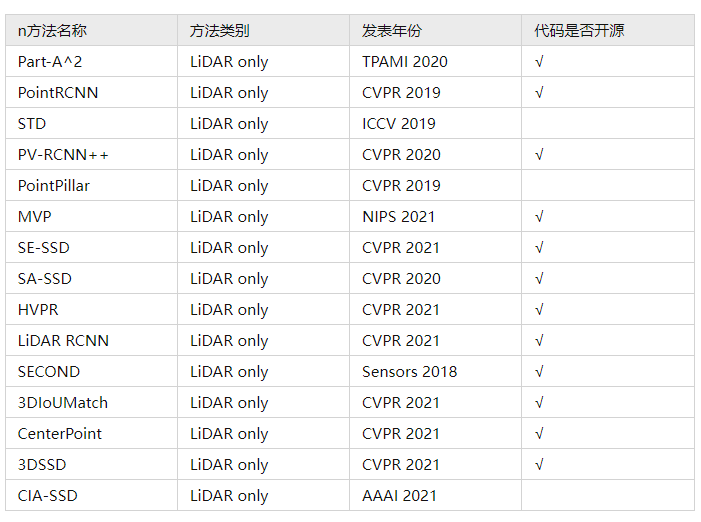
本文主要梳理了最近的3篇文章D Detection分类列出了一些我认为更重要具代表性的工作。
论文总结(1)主要讲解激光雷达点云的3D检测方法(LiDAR only)
https://zhuanlan.zhihu.com/p/436452723
本文总结(2)主要讲解基于多模态融合的3D检测方法(LiDAR RGB),欢迎补充指正。
论文地址:https://arxiv.org/pdf/1711.08488.pdf作者单位:University of Waterloo代码地址:GitHub - kujason/avod: Code for 3D object detection for autonomous driving(https://github.com/charlesq34/frustum-pointnets)一句话读论文:通过聚合不同视角的数据(RGB bird view point cloud)实现预测。
网络框架图
KITTI testset 实验结果图
网络框架的整个过程可以描述为:RGB和bird view point cloud data上同时使用RPN网络提取proposals,进一步预测多视角特征final results。
The proposed method uses feature extractors to generate feature maps from both the BEV map and the RGB image. Both feature maps are then used by the RPN to generate non-oriented region proposals, which are passed to the detection network for dimension refineme, orientation estimation, and category classification.
一是特征提取方法。文章中的特征提取类似FPN结构,即利用upsampling convolution实现了multi-scale feature fusion。
Inspired by the Feature Pyramid Network (FPN), we create a bottom-up decoder that learns to upsample the feature map back to the original input size, while maintaining run time spe
其二,3d bounding box编码方法ground plane 及top and bottom corner offsets将检测框编码为10维向量(2)x4 2)。
To reduce redundancy and keep these physical constraints, we propose to encode the bounding box with four corners and two height values representing the top and bottom corner offsets from the ground plane, determined from the sensor height.
论文地址:https://arxiv.org/pdf/1711.08488.pdf作者单位:Stanford University代码地址:GitHub - charlesq34/frustum-pointnets: Frustum PointNets for 3D Object Detection from RGB-D Data(https://github.com/charlesq34/frustum-pointnets)一句话读论文:用2D detector构造视锥区域约束3D检测。
网络框架图
KITTI testset 实验结果
从网络框图来看,本文显然属于LiDAR RGB fusion,不同于上文提到的AVOD-FPN基于feature层次融合,F-PointNet的融合属于results层次。换句话说,LiDAR数据不直接fuse2D图像特征2个图像特征D图像检测映射的视锥区域。
具体来说,网络框架的整体流程可以描述为:输入RGB图像得到2D检测结果映射为3D前背景点和3视锥区域D box预测。
As shown in the Figure, our system for 3D object detection consists of three modules: frustum proposal, 3D instance segmentation, and 3D amodal bounding box estimation.
首先,为什么视锥是有效的? (详见参考论文4.1节 Frustum Proposal)?首先,目前的2D一般情况下,检测器的检测相对成熟;其次,使用2D检测结果约束3D box点云搜索空间大大降低。
The resolution of data produced by most 3D sensors, especially real-time depth sensors, is still lower than RGB images from commodity cameras. Therefore, we leverage mature 2D object detector to propose 2D object regions in RGB images as well as to classify objects.
第二,视锥区域只检测一个物体。作者的解释是:一个视锥对应一个2D bounding box,而一个2D bounding box并且预测一个object。
Note that each frustum contains exactly one object of interest. Here those "other" points could be points of non-relevant areas (such as ground, vegetation) or othe instances that occlude or are behind the object of interest.
论文地址:https://arxiv.org/abs/1903.01864作者单位:South China University of Technology代码地址:github.com/zhixinwang/f(https://github.com/zhixinwang/frustum-convnet)一句话读论文:利用视锥组而非单一视锥特征进行3D box预测。
网络框架图
KITTI testset 实验结果
从网络框架图也能看出来,文章核心思路和上文中的F-PointNet类似,均是利用2D detector构造视锥区域约束3D检测。不同点在于:F-PointNet使用的是point segmentation feature,也就是point-level feature,F-ConvNet使用的是Frustum feature,也就是frustum-level的。Given 2D region proposals in an RGB image, our method first generates a sequence of frustums for each region proposal, and uses the obtained frustums to group local points. F-ConvNet aggregates point-wise features as frustumlevel feature vectors, and arrays these feature vectors as a feature map for use of its subsequent component of fully convolutional network (FCN), which spatially fuses frustum-level features and supports an end-to-end and continuous estimation of oriented boxes in the 3D space.
备注:感谢微信公众号「」整理。
其一,F-PointNet并非为end-to-end的方式;
it is not of end-to-end learning to estimate oriented boxes.
其二,视锥当中前景点往往很少,因此难以支撑准确的3D检测。
Final estimation relies on too few foreground points which themselves are possibly segmented wrongly.
其三,(这点是个人理解,大家见仁见智),point-level往往是local的也就是局部的,而frustum则更能表征object structure。
论文地址:https://arxiv.org/pdf/2109.01066.pdf作者单位:Google and Waymo 等一句话读论文:作者讨论的是如何有效融合RGB和LiDAR特征。
网络框架图
Waymo Open Dataset 实验结果
如何有效地对齐和融合不同模态特征(RGB and LiDAR)一直是3D目标检测中的难点问题,本文作者方法的核心就是用搜索架构(Architecture Search)寻找有效的跨模态特征组合方式,即论文中Sec3.2.2 Connection Architecture Search in 4D。
While the above projection will align the two sensors geometrically, it is not immediately obvious what information should be extracted from each and how the sensor features interact for the main task of object detection.
其一,RGB和LiDAR特征对齐方面(alignment)。特征对齐依然遵循传统思路,也就是对于每一个3D pillar feature vector而言,找到其在2D image上对应的2D rgb feature vector。
Given a set of RGB feature maps, we can compute the projection of each pillar into the 2D space and obtain a feature vector.
其二,RGB和LiDAR特征融合方面(fusion)。搜索方法其实主要用在fusion中,搜索简言之就是一定规则下的穷举。搜索想实现的结果是找到每一个3D pillar应该融合哪些层的rbg feature。那么为什么要考虑这个问题呢?作者文中给出的解释是,由于点云数据在距离上的分布差异性,其需要融合的2d feature也在尺度上存在差异。也就是说,这里作者给出的搜索规则的设计是从object scale/object distance的角度考虑的。
However, in the autonomous driving domain it is especially important to reliably detect objects at highly variable distances, with modern LiDAR sensors reaching several hundreds of meters of range. This implies that furtheraway objects will appear smaller in the images and the most valuable features for detecting them will be in earlier layers, compared to close-by objects.
论文地址:https://arxiv.org/pdf/1611.07759.pdf作者单位:Tsinghua University代码地址:https://github.com/leeyevi/MV3D_TF一句话读论文:通过聚合不同视角的数据(RGB+bird view point+front view point)实现预测。
网络框架图
KITTI testset 实验结果
论文整体结构挺清晰的,输入是多模态数据,包括RGB+bird view point+front view point。整体网络框架为two-stage架构,the first stage提取proposal,the second stage进一步微调。
In this paper, we propose a Multi-View 3D object detection network (MV3D) which takes multimodal data as input and predicts the full 3D extent of objects in 3D space. The main idea for utilizing multimodal information is to perform region-based feature fusion.
其一,在RPN阶段,3d proposals是在LiDAR bird view上提取的。此外,多模态特征的提取是将3d proposal投影到不同模态下提取对应特,这样做的好处是减少计算量。
Existing work usually encodes 3D LIDAR point cloud into a 3D grid or a front view map. While the 3D grid representation preserves most of the raw information of the point cloud, it usually requires much more complex computation for subsequent feature extraction. We propose a more compact representation by projecting 3D point cloud to the bird's eye view and the front view.
其二,在RCNN阶段,作者尝试了多种fusion网络,最终选用了如图所示的cascade式的结构。作者认为,这种方式有利于不同模态特征进行充分交互。
To combine information from different features, prior work usually use early fusion or late fusion. To enable more interactions among features of the intermediate layers from different views, we design the following deep fusion process.
6. CM3D (WACV 2021)
论文地址:https://arxiv.org/pdf/2008.10436.pdf作者单位:Shanghai Jiao Tong University一句话读论文:考虑两级feature fusion:point-wise fusion+roi-wise fusion
网络框架图
KITTI testset 实验结果
整体网络依然是一个two-stage框架,the first stage 生成proposals,the second stage 对proposal进一步分类微调。
RPN,即proposal生成部分,考虑point-wise fusion。
a)对于不同模态数据的特征提取框架,LiDAR point部分采用PointNet++,RGB image部分采用ResNet50+FPN。另外,需要注意这里的image输入为双目图像。
During the first stage, instead of subdividing point clouds into regular 3D voxels or organising data into different views, we utilize Pointnet++ to directly learn 3D representations from point clouds for classification and segmentation. For binocular images, we apply modified Resnet-50 and FPN as our backbone network to learn discriminative feature maps for future point-wise feature fusion.
b)如何保证2D和3D anchor的一致性,也就是文中Joint Anchor部分(Sec3.3.1)。论文的做法是将点云空间中生成的3D anchor映射到2D平面,以此实现对齐。
These 3D anchors are located at the center of each foreground point and then projected to images for 2D anchors producing. Benefited from the projection, there is no need to seed extra 2D anchors of different ratios for images because it's scale-adapted benefited from projection.
c)如何保证2D和3D proposal的一致性,也就是文中Joint Proposal部分(Sec3.3.2)。论文的做法是利用reprojection loss 约束2D和3D预测出的proposals。作者认为通过这种方式,可以通过2D proposal有效约束3D proposal的位置。更具体地说,作者认为对于3D检测而言,2D proposal回归的是一个视锥区域,这个视锥区域可以为3D box提供粗略定位。
Since the 2D and 3D anchor pairs are naturally produced by our joint anchoring mechanism, we hope to dig deeper to make full use of their inter-connection. As mentioned before, images represent a RGB projection of the world onto the camera plane, and thus 2D anchors correspond to the frustum area of the real world. By regressing 2D proposals, we are regressing a frustum area to its Ground Truth regions. Although it cannot provide precise 3D locations for 3D proposals, it’s still able to offer coarse directions for 3D regression. So we propose a reprojection loss to perform better proposal generation.
RCNN,即进一步分类回归部分,考虑roi-wise fusion。这个部分相对比较简单,顾名思义,就是利用the first stage生成的proposal,提取其feature并级联融合判断。
Given the high quality 3D proposals and corresponding representative fused features, we adopt a light-wight PointNet consisting of two MLP layers to encode the features to a discriminative feature vector.
论文地址:https://arxiv.org/pdf/2107.14391.pdf作者单位:University of Science and Technology of China代码地址:GitHub - djiajunustc/H-23D_R-CNN(https://github.com/djiajunustc/H-23D_R-CNN)一句话读论文:结合不同投影视角下的特征特性构成空间结构信息更丰富的3D feature。
网络框架图
KITTI testset 实验结果
整体网络依然属于two-stage范畴,the first stage提取proposals,the second stage进一步预测。
其一,在第一级也就是proposal生成部分,作者将点云数据分别投影到正视图和俯视图。在正视图利用圆柱/圆筒提取特征,也就是文中的Cylindrical Coordinates 。在俯视图利用类似pillar的方式提取特征,也就是文中的Cartesian Coordinates。
Given the input point clouds, we sequentially project the points into the perspective view and the bird-eye view, and leverage 2D backbone networks for feature extraction.
其二,在第二级也就是微调阶段,作者设计了HV RoI Pooling模块。作者认为voxel RoI Pooling存在的问题是,对于同一个grid point,根据不同的query radius进行 group(不同半径的同心圆可能会包括相同voxel feature),可能导致非空体素被重复采样。此外,随着网格数G和query radius r的增长,计算量成三次方增加。
the non-empty voxels within a small and a large query range centered on the same grid point can be highly reduplicate, which may incur the significance of multi-scale grouping.Besides, the computational cost of grouping neighbor voxels grows cubically with the partition grid numbe G and the query range r.
8. ContFuse (ECCV 2018)
论文地址:https://arxiv.org/pdf/2012.10992v1.pdf作者单位:Uber Advanced Technologies Group 等一句话读论文:利用continuous fusion layer融合多模态多尺度特征。
网络框架图
KITTI testset 实验结果
框架图很清晰了已经,文章的整体核心就是如何设计Continuous Fusion Layer融合多模态多尺度特征。所以这里只着重解释一下Continuous Fusion Layer。
其实说白了这个fusion layer本质上就是MLP,其重点在于如何找到image和LiDAR poings的对齐方式。这篇文章中作者的做法是:对于BEV图像上的每一个像素点,利用KNN找到其在点云LiDAR空间上邻近的K个points,再将这K个points投影到image上,得到其对应的image feature representation。
本文仅做学术分享,如有侵权,请联系删文。
1.面向自动驾驶领域的多传感器数据融合技术
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进4.国内首个面向工业级实战的点云处理课程5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
9.从零搭建一套结构光3D重建系统[理论+源码+实践]
10.单目深度估计方法:算法梳理与代码实现
11.自动驾驶中的深度学习模型部署实战
12.相机模型与标定(单目+双目+鱼眼)
13.重磅!四旋翼飞行器:算法与实战
14.ROS2从入门到精通:理论与实战
扫码添加小助手微信,可
也可申请加入我们的细分方向交流群,目前主要有、、、、、等微信群。
一定要备注:,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。也请联系。
▲长按加微信群或投稿
▲长按关注公众号
:针对3D视觉领域的五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款
圈里有高质量教程资料、答疑解惑、助你高效解决问题