BitMap
现代计算机采用二进制(bit,位)作为信息的基本单位,1 个字节等于 8 位,例如big字符串是由 3 它由字节组成,但实际上在计算机存储中用二进制表示,big分别对应的 ASCII 码分别是 98、105、103,对应的二进制是 01100010、01101001 和 01100111。
许多开发语言提供了操作位的功能,合理使用位可以有效地提高内存利用率和开发效率。
Bit-map 基本思想是用一个 bit 标记元素对应的位置 value,而 key 也就是这个元素。因为使用了。 bit 为单位存储数据,可以大大节省存储空间。
在 Java 中,int 占 4 字节,1 字节 = 8位(1 byte = 8 bit),假如我们用这个 32 个 bit 如果每个位的值表示一个数字,它能表示吗? 32 个数字,也就是说 32 只需要一个数字 int 占用的空间大小可以缩小空间 32 倍。
1 Byte = 8 Bit,1 KB = 1024 Byte,1 MB = 1024 KB,1GB = 1024 MB
假设网站有 1 1亿用户,每天独立访问的用户 5 如果每天使用集合类型和 BitMap 活跃用户分别存储:
- 假如用户 id 是 int 型,4 字节,32 位置,集合类型占据的空间是 50 000 000 * 4/1024/1024 = 200M;
- 若按位存储,5 数千万就是 5 千万,占据空间 50 000 000/8/1024/1024 = 6M。
那么如何用 BitMap 表示一个数?
上面说了用 bit 标记元素对应的位置 value,而 key 即使是这个元素,我们也可以把它拿走 BitMap 想象成一个以位为单位的,数组的每个单元只能存储 0 和 1(0 这意味着这个数字不存在,1 表示存在),数组的下标记 BitMap 中叫做偏移量。比如我们需要表示{1,3,5,7}这四个数字如下:
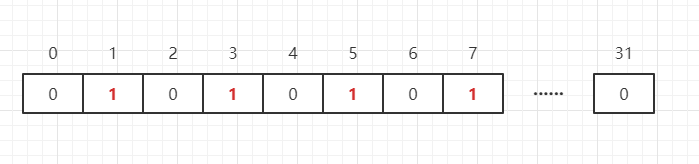
如果还有一个数字 65 呢?只需打开int[N/32 1]个 int 数组可以存储这些数据(包括 N 表示这组数据中的最大值),即:
int[0]:可以表示 0~31
int[1]:可以表示 32~63
int[2]:可以表示 64~95
假设我们需要判断任何整数是否在列表中, M/32 获得下标,M2知道它在这里下标的位置,如:
65/32 = 2,652=1,即 65 在int[2] 中的第 1 位。
布隆过滤器
布隆过滤器本质上是一种数据结构,具有高效插入和查询的概率数据结构,可以用来告诉你 “某 东西一定不存在或可能存在。
与传统相比 List、Set、Map 其他数据结构,效率更高,占用空间更少,但缺点是其返回的结果是概率性的,而不是准确的。
事实上,布隆过滤器被广泛应用、、等,Google 著名的分布式数据库 Bigtable 使用布隆过滤器找到不存在的行或列,以减少磁盘搜索 IO 次数,Google Chrome 布隆过滤器用于加速安全浏览服务。
在很多 Key-Value 布隆过滤器也用于加快系统中的查询过程,如 Hbase,Accumulo,Leveldb,一般而言,Value 保存在磁盘中,访问磁盘需要花费大量时间,然而使用布隆过滤器可以快速判断某个 Key 对应的 Value 是否存在可以避免许多不必要的磁盘 IO 操作。
通过一个 Hash 函数将元素映射成一个阵列(Bit Array)其中一点。这样,我们只需要看看这一点是否正确 1 知道是否可以集合。这是布隆过滤器的基本思想。
运用场景
1、目前有 10 自然数亿,随机排序,需要排序。限制条件是 32 位机完成,内存限制为 2G。如何完成?
2.如何快速定位亿级黑名单? URL 地址在黑名单上吗? URL 平均 64 字节)
3.需要分析用户登录行为来确定用户的活动?
4.网络爬虫-如何判断? URL 你爬过吗?
5.快速定位用户属性(黑名单、白名单等)
6.如何在磁盘中存储数据,避免大量无效? IO?
判断一个元素是否存在于亿级数据中?
8.缓存穿透。
缺乏传统的数据结构
一般来说,网页 URL 存入数据库进行搜索,或建立哈希表进行搜索 OK 了。
当数据量较小时,这样思考是正确的,值映射确实可以 HashMap 的 Key,然后可以在 O(1) 时间复杂 返回结果,效率奇高。但是 HashMap 实现也有缺点,如存储容量比例高,考虑到负载因子的存在,通常空间不能满,例如,如果一个 1000 万 HashMap,Key=String(长度不超过 16 字符,重复性极小),Value=Integer,会占用多少空间?1.2 个 G。
实际上用 bitmap,1000 万个 int 型,只需要 40M( 10 000 000 * 4/1024/1024 =40M)左右空间,比例 3%,1000 万个 Integer,需要 161M 左右空间,比例 13.3%。
可见,一旦你的价值很多,比如上亿,那么 HashMap 可想而知占据的内存大小。
但是,如果整个网页黑名单系统包含 100 亿个网页 URL,在数据库中搜索需要很长时间,如果是每个数据库 URL 空间为 64B,所以需要内存 640GB,一般服务器很难满足这一需求。
实现原理
假设我们有个集合 A,A 中有 n 个元素函数,A中的每个元素到一个长度为 a 位的数组 B在这些位置的不同位置设置二进制数 1.如果要检查的元素已经过去了 k在映射了哈希散列函数后,发现了它 k 位置上的二进制数,这个元素很可能属于集合A,反之,。
比如我们有 3 个 URL {URL1,URL2,URL3},通过一个hash 函数将它们映射到一个长度 16 如下:
若目前哈希函数为 Hash1(),假设通过哈希运算映射到数组Hash1(URL1) = 3,Hash1(URL2) = 6,Hash1(URL3) = 6,如下:
因此,如果我们需要判断URL1是否通过这个集合Hash(1)计算其下标并获得其值 1 说明存在。
由于 Hash 哈希冲突如上URL2,URL3都定位在一个位置,假设 Hash 如果我们的数组长度为 m 如果我们想把冲突率降低到一个点,比如 , 这个散列表只能容纳 m/100 显然,个元素的空间利用率变低了,也就是说,不可能(space-efficient)。
解决方案也很简单,即使用多种方法 Hash 算法,如果有一个说元素不集中,那肯定不是,如下:
Hash1(URL1) = 3,Hash2(URL1) = 5,Hash3(URL1) = 6 Hash1(URL2) = 5,Hash2(URL2) = 8,Hash3(URL2) = 14 Hash1(URL3) = 4,Hash2(URL3) = 7,Hash3(URL3) = 10 以上是布隆过滤器的做法,使用,每个字符串跟 k 个 bit 因此,冲突的概率降低了。
误判现象
上述做法也存在问题,因为随着越来越多的值的增加, 1 的 bit 会有越来越多的位置,所以即使一个值没有存储,如果哈希函数返回三个 bit 所有的位置都是其他值位 1 ,然后程序仍然会判断这个值的存在。例如,此时不存在 URL1000,哈希计算后发现 bit 位为下:
Hash1(URL1000) = 7,Hash2(URL1000) = 8,Hash3(URL1000) = 14 但这些 bit 位已经被URL1,URL2,RL3置为 1 了,此时程序就会判断 URL1000 值存在。
这就是布隆过滤器的误判现象,所以,
布隆过滤器可精确的代表一个集合,可精确判断某一元素是否在此集合中,精确程度由用户的具体设计决定,达到 100% 的正确是不可能的。但是布隆过滤器的优势在于,。
实现
Redis 的 bitmap
基于redis 的 bitmap数据结构的相关指令来执行。
RedisBloom
布隆过滤器可以使用 Redis 中的位图(bitmap)操作实现,直到 Redis4.0 版本提供了插件功能,Redis 官方提供的布隆过滤器才正式登场,布隆过滤器作为一个插件加载到 Redis Server 中,官网推荐了一个 RedisBloom 作为 Redis 布隆过滤器的 Module。
详细安装、指令操作参考:https://github.com/RedisBloom/RedisBloom
文档地址:https://oss.redislabs.com/redisbloom/
Guava 的 BloomFilter
Guava 项目发布版本11.0时,新添加的功能之一是BloomFilter类。
参考:https://blog.csdn.net/dnc8371/article/details/106705929
Redisson
Redisson 底层基于位图实现了一个布隆过滤器。
public static void main(String[] args) {
Config config = new Config();
// 单机环境
config.useSingleServer().setAddress("redis://192.168.153.128:6379");
//构造Redisson
RedissonClient redisson = Redisson.create(config);
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("nameList");
//初始化布隆过滤器:预计元素为100000000L,误差率为3%,根据这两个参数会计算出底层的 bit 数组大小
bloomFilter.tryInit(100000L, 0.03);
//将 10086 插入到布隆过滤器中
bloomFilter.add("10086");
//判断下面号码是否在布隆过滤器中
System.out.println(bloomFilter.contains("10086"));//true
System.out.println(bloomFilter.contains("10010"));//false
System.out.println(bloomFilter.contains("10000"));//false
}
解决缓存穿透
缓存穿透是指查询一个根本,缓存层和存储层都不会命中,如果从存储层查不到数据则不写入缓存层。
缓存穿透将导致不存在的数据每次请求都要到存储层去查询,失去了缓存保护后端存储的意义。缓存穿透问题可能会使,由于很多后端存储不具备高并发性,甚至可能造成后端存储宕掉。
因此我们可以用布隆过滤器来解决,在访问缓存层和存储层之前,将存在的 key 用布隆过滤器提前保存起来,做第一层拦截。
例如:一个推荐系统有 4 亿个用户 id,每个小时算法工程师会根据每个用户之前历史行为计算出推荐数据放到存储层中,但是最新的用户由于没有历史行为,就会发生缓存穿透的行为,为此可以将所有推荐数据的用户做成布隆过滤器。如果布隆过滤器认为该用户 id 不存在,那么就不会访问存储层,在一定程度保护了存储层。
注:
参考:
https://juejin.cn/post/7000159119059451941
https://www.cnblogs.com/cjsblog/p/11613708.html