k8s的CNI插件方案
- 1 基于隧道
- 2 基于路由
- 3 k8s网络插件
-
- 3.1 Flannel
-
- 3.1.1 简介
- 3.1.2 Flannel架构
- 3.1.3 flannel有三种工作方式:
- 3.1.4 flannel网络配置参数:
- 3.2 Calico
-
- 3.2.1 Calico简介
- 3.2.2 calico架构
- 3.2.3 calico 原理
- 3.2.4 calico网络模式
- 3.2.5 Calico网络策略:
- 3.3 Weave
- 3.4 Canal
- 3.5 flannel对比calico
原生NAT方案
隧道方案(Overlay),有代表性的方案Flannel、Docker Overlay、OVS等
有代表性的路由方案和有Calico、MacVlan
定制网络方案
隧道方案,即Overlay方案,借助容器宿主机网络,为容器构建三层路由可达虚拟网络。具体方法是将容器网络数据包整体包装放入宿主机网络报纸中,从宿主机网络转发到目标容器所在的宿主机,然后从目标容器所在的宿主机拆解报纸,获得容器网络数据包,交给容器网桥,然后从容器网桥转发到目标容器。隧道方案的优点是没有NAT方案的端口冲突,不消耗额外的骨干网络IP、通过构建不同的网络技术,与现有的网络技术没有冲突,灵活性大VLAN虚拟网络容易实现网络隔离,网络性能损失比原生NAT方案小,既满足了银行业务功能和安全监管的要求,又照顾了性能。因此隧道(Overlay)目前,该方案是用广泛,技术选择性最大,方案成熟度较高。因此,与其他方案相比,隧道方案的实施、定制和维护成本相对较低。但是,事情有两面性。如果选择隧道方案,还是有一些不可避免的问题需要考虑解决:
如果容器平台中的运行业务需要与其他平台上的运行业务进行通信,则需要配置从容器外部访问容器的路由,否则容器地址不能直接从容器平台外部访问。由于容器动态变化和跨主机迁移的特点,从外部访问容器的路由配置是一个复杂的问题,不仅需要在外部路由器和宿主机路由表中配置,还需要将这些配置动作与容器的启动和停止联动,这需要复杂性SDN能力;
由于容器网络数据包在宿主机网络报纸上传输时包装在底层网络上,因此容器网络数据包的地址对于普通防火墙来说是看不见的。如果需要准确设置容器数据包,成本很高,几乎不可行;灵活的方法可以考虑在启动时指定需要网络隔离的容器VLAN,通过不同的VLAN实现隔离;
由于容器网络数据包需要包装在底层宿主机网络报纸中,当你的底层网络也是时,它会增加底层网络数据包的长度Overlay网络,或者Overlay当层数较多时,会影响网络数据包承载数据的效率,包装和拆卸数据包的次数也会显著影响网络的传输效率。这个问题也需要注意关键的性能场景。
路由方案通过路由技术从三层或二层交叉主机容器NAT,没有Overlay方案所需的数据包包包包装和拆卸,每个容器都有路由IP地址,可以从容器平台的外部路由到达。该网络方案的优点是性能损失小,外部路由可达,传统防火墙仍能正常工作。但缺点是:
IP地址消耗量大,如果容器数量大,特别是使用微服务架构后,大量容器IP资源被消耗,可能会出现大量资源IP冲击路由表,导致路由效率下降;
在容器网络中,网络实体在容器平台外部的变化仍然无法感知,例如,当新容器创建或跨主机迁移时,Calico方案为例,Felix和BGP client该模块可以确保容器网络中的路由策略更新。然而,由于容器平台外部世界无法感知容器的变化,因此无法自动创建外部新容器的路由,仍需补充额外的路由更新工作。
1 基于隧道
1.隧道方案最普遍,在任何网络环境下都能正常工作,这与其原理密不可分。 2.最常见的隧道方案是flannel vxlan模式,以及calico的ipip其核心原理包括两部分。
分配网段 每台宿主机都有网络插件agent它们连接到过程中etcd集中存储,从虚拟IP在池中申请一个IP段占有自己的位置,宿主机上的每个容器从IP在段中分配一个虚拟的IP。
封装/解封 1)当不同宿主机上的容器相互访问时,数据包的源IP和目标IP都是容器IP。 2)数据包通过宿主机agent包装过程后,新数据包的源IP和目标IP它变成了两端宿主机的物理IP。 3)数据包送到目标宿主机后,通过agent解封后得到原始数据包,并将数据包发送到容器中进行处理,为两端容器营造互通感。 因为物理IP它属于三层网络,可以通过中间路由设备在互联网上交付,因此隧道方案对宿主机之间的网络环境没有特殊要求,因此隧道方案是普遍的。
优势/劣势 优点是只要宿主机对物理网络环境没有特殊要求IP层可以路由交通。
缺点是性能差,需要从以下几个方面来看: 封包和解包耗费CPU性能; 额外包装造成带宽浪费,约30%的带宽损失;
flannel vxlan和calico ipip模式是隧道方案,但是calico的封装协议IPIP的header性能比较小flannel vxlan好一点。
2 基于路由
1.路由方案性能最好,因为方案不需要封包和解包,所以没有隧道方案的缺点,网络性能很好。 2.常见的路由方案包括flannel的host-gw模式,以及calico的bgp模式。
下面以calico bpg以模式为例,基于路由的方案原理分析包括三个部分。 分配网段 还有每台宿主机agent,会从etcd中的虚拟IP池分配到一个IP子网段,宿主机上的每个容器都来自IP在段中分配一个虚拟的IP。
本地路由 1)假设我们在宿主机A上新建了一个容器,容器分配了一个虚拟容器IP,假设它是值得的k。 2)、agent如果数据包的目标地址等于数据包的目标地址k,然后将数据包发送到容器的虚拟网卡上。 3),另一个宿主机B上的容器IP是m,将数据包发送到k容器,数据包的目标地址是k,原地址是m。 4)由于路由方案不使用隧道密封物理IP在网络中流通,如何将数据包送达虚拟?IP k呢?
广播路由 1)路由方案将采用以下手段从m到k的虚拟IP互通问题。 2),即宿主A会以某种方式(例如(例如)BGP广播协议)自己虚拟IP将网段广播给宿主机B。 3).宿主机B收到广播后,将配置一条路由规则:如果数据包的目标地址属于宿主机A的虚拟IP网段将数据包发给宿主机A的物理IP。 4)这条路由规则相当于宿主机A的虚拟IP网段配备了转发网关,这是宿主机A的物理IP。这就要求宿主机B和宿主机A在两层网络上互通,即它们可以基于交换机MAC地址直接交换。 5)一旦数据包被送到宿主机A的物理IP,宿主机A可以应用刚才提到的本地路由规则,即数据包的目标IP是k,虚拟网卡直接送到相应的容器。 在整个过程中,从m到k的数据包使用虚拟容器IP,没有任何包装和解封,只有宿主机B收到的广播路由 宿主机A的本地路由在二层网络交换环境中实现了高效的通信。
优势/劣势 优点是没有封包和解包过程,完全基于宿主机两端的路由表。
缺点包括两个方面: 宿主机必须在同一个两层网络下,即连接到一个交换机,以便基于MAC不需要在那里通信IP手脚上动封包/解包。 由于宿主机上的每个容器都需要在这台机器上添加一条路由规则,而不同宿主机之间需要广播自己的网段路由规则。
3 k8s网络插件
网络架构是Kubernetes很多用户头疼的复杂方面之一。Kubernetes网络模型本身对某些特定的网络功能有一定的要求,但在实现方面也有一定的灵活性。因此,该行业有许多不同的网络解决方案来满足特定的环境和要求。 CNI这意味着容器网络接口,它是一种标准设计,使用户在创建或销毁容器时更容易配置容器网络。本文将重点探索和比较当前情况CNI插件:Flannel、Calico、Weave和Canal(技术上是多个插件的组合)。这些插件既能保证满足Kubernetes的网络要求,又能为Kubernetes集群管理员提供他们需要的特定网络功能。 CNI其初衷是在配置或销毁容器时,创建适当的网络配置和资源的框架。以下链接CNI本规范总结了用于准备网络的插件接口,允许容器运行时与插件协调: 插件负责接口配置和管理IP地址,通常提供和IP管理、每个容器的IP与多主机连接相关的分配和功能。在容器启动时,会调用网络插件进行分配IP网络的地址和配置,并在删除容器时再次调用,以清理这些资源。 操作或协调决定了容器应该添加哪个网络以及需要调用哪个插件。然后,插件将接口加到容器网络命名空间中,作为一个veth对的一侧。接着,它会在主机上进行更改,包括将veth的其他部分连接到网桥。再之后,它会通过调用单独的IPAM(IP地址管理)插件来分配IP地址并设置路由。 在Kubernetes中,kubelet可以在适当的时间调用它找到的插件,来为通过kubelet启动的pod进行自动的网络配置。 在对CNI插件们进行比较之前,我们可以先对网络中会见到的相关术语做一个整体的了解。
一些最常见的术语包括:
第2层网络:OSI(Open Systems Interconnections,开放系统互连)网络模型的“数据链路”层。第2层网络会处理网络上两个相邻节点之间的帧传递。第2层网络的一个值得注意的示例是以太网,其中MAC表示为子层。 第3层网络:OSI网络模型的“网络”层。第3层网络的主要关注点,是在第2层连接之上的主机之间路由数据包。IPv4、IPv6和ICMP是第3层网络协议的示例。 VXLAN:代表“虚拟可扩展LAN”。首先,VXLAN用于通过在UDP数据报中封装第2层以太网帧来帮助实现大型云部署。VXLAN虚拟化与VLAN类似,但提供更大的灵活性和功能(VLAN仅限于4096个网络ID)。VXLAN是一种封装和覆盖协议,可在现有网络上运行。 Overlay网络:Overlay网络是建立在现有网络之上的虚拟逻辑网络。Overlay网络通常用于在现有网络之上提供有用的抽象,并分离和保护不同的逻辑网络。 封装:封装是指在附加层中封装网络数据包以提供其他上下文和信息的过程。在overlay网络中,封装被用于从虚拟网络转换到底层地址空间,从而能路由到不同的位置(数据包可以被解封装,并继续到其目的地)。 网状网络:网状网络(Mesh network)是指每个节点连接到许多其他节点以协作路由、并实现更大连接的网络。网状网络允许通过多个路径进行路由,从而提供更可靠的网络。网状网格的缺点是每个附加节点都会增加大量开销。 BGP:代表“边界网关协议”,用于管理边缘路由器之间数据包的路由方式。BGP通过考虑可用路径,路由规则和特定网络策略,帮助弄清楚如何将数据包从一个网络发送到另一个网络。BGP有时被用作CNI插件中的路由机制,而不是封装的覆盖网络。 了解了技术术语和支持各类插件的各种技术之后,下面我们可以开始探索一些的CNI插件了。
Kubernetes的网络通信问题: 1. 容器间通信: 即同一个Pod内多个容器间通信,通常使用loopback来实现。 2. Pod间通信: K8s要求,Pod和Pod之间通信必须使用Pod-IP 直接访问另一个Pod-IP 3. Pod与Service通信: 即PodIP去访问ClusterIP,当然,clusterIP实际上是IPVS 或 iptables规则的虚拟IP,是没有TCP/IP协议栈支持的。但不影响Pod访问它. 4. Service与集群外部Client的通信,即K8s中Pod提供的服务必须能被互联网上的用户所访问到。
需要注意的是,k8s集群初始化时的service网段,pod网段,网络插件的网段,以及真实服务器的网段,都不能相同,如果相同就会出各种各样奇怪的问题,而且这些问题在集群做好之后是不方便改的,改会导致更多的问题,所以,就在搭建前将其规划好。 CNI(容器网络接口): 这是K8s中提供的一种通用网络标准规范,因为k8s本身不提供网络解决方案。 目前比较知名的网络解决方案有: flannel calico canel kube-router … 等等,目前比较常用的时flannel和calico,flannel的功能比较简单,不具备复杂网络的配置能力,calico是比较出色的网络管理插件,单具备复杂网络配置能力的同时,往往意味着本身的配置比较复杂,所以相对而言,比较小而简单的集群使用flannel,考虑到日后扩容,未来网络可能需要加入更多设备,配置更多策略,则使用calico更好 所有的网络解决方案,它们的共通性: 1. 虚拟网桥 2. 多路复用:MacVLAN 3. 硬件交换:SR-IOV(单根-I/O虚拟网络):它是一种物理网卡的硬件虚拟化技术,它通过输出VF(虚拟功能)来将网卡虚拟为多个虚拟子接口,每个VF绑定给一个VM后,该VM就可以直接操纵该物理网卡。
kubelet来调CNI插件时,会到 /etc/cni/net.d/目录下去找插件的配置文件,并读取它,来加载该插件,并让该网络插件来为Pod提供网络服务。
3.1 Flannel
3.1.1 简介
由CoreOS开发的项目Flannel,可能是最直接和最受欢迎的CNI插件。它是容器编排系统中最成熟的网络结构示例之一,旨在实现更好的容器间和主机间网络。随着CNI概念的兴起,Flannel CNI插件算是早期的入门。
与其他方案相比,Flannel相对容易安装和配置。它被打包为单个二进制文件FlannelD,许多常见的Kubernetes集群部署工具和许多Kubernetes发行版都可以默认安装Flannel。Flannel可以使用Kubernetes集群的现有etcd集群来使用API存储其状态信息,因此不需要专用的数据存储。
Flannel配置第3层IPv4 Overlay网络。它会创建一个大型内部网络,跨越集群中每个节点。在此Overlay网络中,每个节点都有一个子网,用于在内部分配IP地址。在配置Pod时,每个节点上的Docker桥接口都会为每个新容器分配一个地址。同一主机中的Pod可以使用Docker桥接进行通信,而不同主机上的pod会使用flanneld将其流量封装在UDP数据包中,以便路由到适当的目标。
Flannel有几种不同类型的后端可用于封装和路由。默认和推荐的方法是使用VXLAN,因为VXLAN性能更良好并且需要的手动干预更少。
总的来说,Flannel是大多数用户的不错选择。从管理角度来看,它提供了一个简单的网络模型,用户只需要一些基础知识,就可以设置适合大多数用例的环境。一般来说,在初期使用Flannel是一个稳妥安全的选择,直到你开始需要一些它无法提供的东西。
3.1.2 Flannel架构
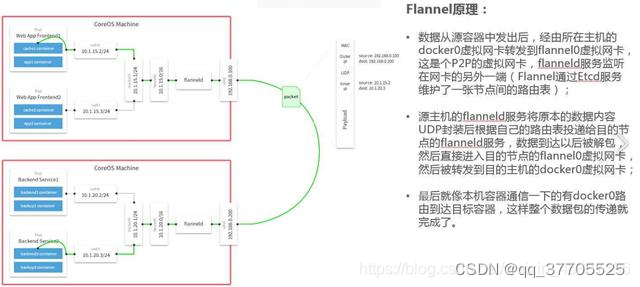 flannel的udp模式和vxlan模式都是属于隧道方式,也就是在udp的基础之上,构建虚拟网络,然后通过一个封包解包的过程来实现数据的传输。
flannel的udp模式和vxlan模式都是属于隧道方式,也就是在udp的基础之上,构建虚拟网络,然后通过一个封包解包的过程来实现数据的传输。
#模拟使用Flannel网络
(宿主机A上的docker容器(10.1.15.10)发送数据到宿主机B上的docker容器(10.1.20.20)的流程)
1>首先,docker容器10.1.15.10要发送数据到宿主机B上,进行匹配相关的路由,根据源容器和目的容器的IP匹配路由规则,同时匹配两个IP的路由规则是10.1.0.0/16,如果是同一个宿主机上的容器访问,匹配的是10.1.15.0或者10.1.20.0
2>数据从docker0网桥出来以后投递到flannel0网卡
3>监听flannel0网卡的Flanneld服务收到数据后封装成数据包发送到宿主机B
4宿主机B上的Flanneld服务接收到数据包后解包还原成原始数据
5>Flanneld服务发送数据到flannel0网卡,根据目的容器地址匹配到路由规则10.1.20.0/24(docker0)
6>投递数据到docker0网桥,进而进入到目标容器10.1.20.20
(1)引入了多个网络组件,在网络通信时需要转到flannel0网络接口,再转到用户态的flanneld程序,到对端后还需要走这个过程的反过程,所以也会引入一些网络的时延损耗。 (2)Flannel模型默认采用了UDP作为底层传输协议,UDP本身是非可靠协议,虽然两端的TCP实现了可靠传输,但在大流量、高并发的应用场景下还建议多次测试。 与其他方案相比,Flannel相对容易安装和配置。它被打包为单个二进制文件FlannelD,许多常见的Kubernetes集群部署工具和许多Kubernetes发行版都可以默认安装Flannel。Flannel可以使用Kubernetes集群的现有etcd集群来使用API存储其状态信息,因此不需要专用的数据存储。 Flannel配置第3层IPv4 Overlay网络。它会创建一个大型内部网络,跨越集群中每个节点。在此Overlay网络中,每个节点都有一个子网,用于在内部分配IP地址。在配置Pod时,每个节点上的Docker桥接口都会为每个新容器分配一个地址。同一主机中的Pod可以使用Docker桥接进行通信,而不同主机上的pod会使用flanneld将其流量封装在UDP数据包中,以便路由到适当的目标。 Flannel有几种不同类型的后端可用于封装和路由。默认和推荐的方法是使用VXLAN,因为VXLAN性能更良好并且需要的手动干预更少。 总的来说,Flannel是大多数用户的不错选择。从管理角度来看,它提供了一个简单的网络模型,用户只需要一些基础知识,就可以设置适合大多数用例的环境。一般来说,在初期使用Flannel是一个稳妥安全的选择,直到你开始需要一些它无法提供的东西。
Flannel:
IPIP/BGP 2 个方案表现一般,其中 VXLAN 方案是因为没法开 UDP Offload 导致性能偏低,其他的测试报告看来,一旦让网卡自行解 UDP 包拿到 MAC 地址,性能基本上可以达到无损,同时 CPU 占用率相当好。UDP 方案受限于 USER Space 的解包,仅仅比 weave ( UDP )要好一点。
优势:部署简单,性能一般。
劣势:没办法实现固定 IP 的容器漂移,没法做子网隔离,对上层设计依赖程度高,没有 IPAM , IP 地址浪费,对 Docker 启动方法有绑定。
flannel网络插件要怎么部署? 1. flannel部署到那个节点上? 因为kubelet是用来管理Pod的,而Pod运行需要网络,因此凡是部署kubelet的节点,都需要部署flannel来提供网络,因为kubelet正是通过调用flannel来实现为Pod配置网络的(如:添加网络,配置网络,激活网络等)。
2. flannel自身要如何部署? 1》它支持直接运行为宿主机上的一个守护进程。 2》它也支持运行为一个Pod 对于运行为一个Pod这种方式:就必须将flannel配置为共享当前宿主机的网络名称空间的Pod,若flannel作为控制器控制的Pod来运行的话,它的控制器必须是DaemonSet,在每一个节点上都控制它仅能运行一个Pod副本,而且该副本必须直接共享宿主机的网络名称空间,因为只有这样,此Pod才能设置宿主机的网络名称空间,因为flannel要在当前宿主机的网络名称空间中创建CNI虚拟接口,还要将其他Pod的另一半veth桥接到虚拟网桥上,若不共享宿主机的网络名称空间,这是没法做到的。
3.1.3 flannel的工作方式有3种:
通过在每一个节点上启动一个叫flannel的进程,负责为每一个节点上的子网划分,并将相关配置信息(如各节点的子网网段、外部IP等)保存到etcd中,而具体的网络报文转发交给backend实现。 flanneld可以在启动时通过配置文件指定不同的backend进行网络通信,目前比较成熟的backend有UDP、VXLAN和host-gateway三种。目前,VXLAN是官方比较推崇的一种backend实现方式。 UDP模式和VXLAN模式基于三层网络层即可实现,而host-gateway模式就必须要求集群所有机器在同一个广播域,也就是需要在二层网络同一个交换机下才能实现。 host-gatewa一般用于对网络性能要求比较高的场景,但需要基础网络架构的支持;UDP则用于测试及一般比较老的不支持VXLAN的Linux内核。 : 这种方式性能最差的方式,这源于早期flannel刚出现时,Linux内核还不支持VxLAN,即没有VxLAN核心模块,因此flannel采用了这种方式,来实现隧道封装,其效率可想而知,因此也给很多人一种印象,flannel的性能很差,其实说的是这种工作模式,若flannel工作在host-GW模式下,其效率是非常高的,因为几乎没有网络开销。 采用UDP模式时,需要在flanneld的配置文件中指定Backend.Type为UDP,可通过直接修改flanneld的ConfigMap的方式实现。
# kubectl get cm kube-flannel-cfg -n kube-system -o yaml
kubectl
net-conf.json: |
{
"Network": "10.233.64.0/18",
"Backend": {
"Type": "udp"
}
}
通过ip addr 命令可以发现节点上会多出一个flannel 0的网络接口,在UDP模式中,flanneld的主要作用为:
(1)UDP包封包解包
(2)节点上路由表的动态更新
工作流程图: 熟悉Linux的应该知道,Linux频繁内核态-用户态的切换,会造成频繁的上下文切换,会引发性能问题,所以从上面可以看到container的数据包,从离开src container后,经过了多次内核态-用户态的切换,并且,数据包是由用户态的flannel进行进行封包/解包的,从而导致了比较大的性能损耗,这也是为什么生产基本不会用这个方案,因为性能实在非常差。 同样需要在Backend.Type修改为VXLAN
net-conf.json: |
{
"Network": "10.233.64.0/18",
"Backend": {
"Type": "vxlan"
}
}
VXLAN模式下,会创建一个名为flannel 1的VTEP设备,数据的转发由内核完成,并不是flanned,flanned仅动态设置ARP和FDB表项. 工作流程图: vxlan本身就是内核特性,使用vxlan会在服务器中创建一个vtep设备(flannel 1),设备的封包/解包操作都在该设备下操作,所以直接在内核态操作,不需要CPU上下文切换,且和UDP直接三层封包不一样,vxlan是直接对二层数据帧进行封包。 而VxLAN有两种工作方式: a. VxLAN: 这是原生的VxLAN,即直接封装VxLAN首部,UDP首部,IP,MAC首部这种的。 b. DirectRouting: 这种是混合自适应的方式, 即它会自动判断,若当前是相同二层网络 (即:不垮路由器,二层广播可直达),则直接使用Host-GW方式工作,若发现目标是需要跨网段 (即:跨路由器)则自动转变为使用VxLAN的方式。 同上需要在Backend.Type修改为host-gw。
由于host-gw是纯路由模式,flannel需要通过etcd维护所有的静态路由,核心是IP包在封装成桢的时候,使用路由表的"下一跳"设置上的MAC地址,这样可以经过二层网络到达目的宿主机。这就要求所有的服务器在同一个二层网络下,这就使host-gw模式无法适用于集群规模较大且需要对节点进行网段划分的场景。
host-gw另外一个限制则是随着集群中节点规模的增大,flanneld维护主机上成千上万条路由表的动态更新也是一个不小的压力,因此在路由方式下,路由表规则的数量是限制网络规模的一个重要因素。
工作流程图: 在性能上,host-gw由于没有封包/解包,故性能最好
host-GW: 这种方式是宿主机内Pod通过虚拟网桥互联,然后将宿主机的物理网卡作为网关,当需要访问其它Node上的Pod时,只需要将报文发给宿主机的物理网卡,由宿主机通过查询本地路由表,来做路由转发,实现跨主机的Pod通信,这种模式带来的问题时,当k8s集群非常大时,会导致宿主机上的路由表变得非常巨大,而且这种方式,要求所有Node必须在同一个二层网络中,否则将无法转发路由,这也很容易理解,因为如果Node之间是跨路由的,那中间的路由器就必须知道Pod网络的存在,它才能实现路由转发,但实际上,宿主机是无法将Pod网络通告给中间的路由器,因此它也就无法转发理由。
3.1.4 flannel的网络配置参数:
-
Network: flannel使用的CIDR格式的网络地址,主要用于为Pod配置网络功能。 如: 10.10.0.0/16 —> master: 10.10.0.0/24 node01: 10.10.1.0/24 … node255: 10.10.255.0/24
-
SubnetLen: 把Network切分为子网供各节点使用时,使用多长的掩码来切分子网,默认是24位.
-
SubnetMin: 若需要预留一部分IP时,可设置最小从那里开始分配IP,如:10.10.0.10/24 ,这样就预留出了10个IP
-
SubnetMax: 这是控制最多分配多个IP,如: 10.10.0.100/24 这样在给Pod分配IP时,最大分配到10.10.0.100了。
-
Backend: 指定后端使用的协议类型,就是上面提到的:vxlan( 原始vxlan,directrouter),host-gw, udp flannel的配置: … net-conf.json: | { “Network”: “10.10.0.0/16”, “Backend”: { “Type”: “vxlan”, #当然,若你很确定自己的集群以后也不可能跨网段,你完全可以直接设置为 host-gw. “Directrouting”: true #默认是false,修改为true就是可以让VxLAN自适应是使用VxLAN还是使用host-gw了。 } }
#在配置flannel时,一定要注意,不要在半道上,去修改,也就是说要在你部署k8s集群后,就直接规划好,而不要在k8s集群已经运行起来了,你再去修改 https://github.com/coreos/flannel
3.2 Calico
3.2.1 Calico简介
Calico是一个纯三层的网络插件,calico的bgp模式类似于flannel的host-gw。 Calico方便集成OpenStack这种 IaaS云架构,为openstack虚拟机、容器、裸机提供多主机间通信。
3.2.2 calico架构
calico包括如下重要组件:Felix,etcd,BGP Client,BGP Route Reflector。下面分别说明一下这些组件。
Felix:主要负责路由配置以及ACLS规则的配置以及下发,它存在在每个node节点上。
etcd:分布式键值存储,主要负责网络元数据一致性,确保Calico网络状态的准确性,可以与kubernetes共用;
BGPClient(BIRD), 主要负责把 Felix写入 kernel的路由信息分发到当前 Calico网络,确保 workload间的通信的有效性;
BGPRoute Reflector(BIRD), 大规模部署时使用,摒弃所有节点互联的mesh模式,通过一个或者多个 BGPRoute Reflector 来完成集中式的路由分发;
3.2.3 calico 原理
calico是一个纯三层的虚拟网络,它没有复用docker的docker0网桥,而是自己实现的,calico网络不对数据包进行额外封装,不需要NAT和端口映射,扩展性和性能都很好。Calico网络提供了DockerDNS服务,容器之间可以通过hostname访问,Calico在每一个计算节点利用Linux Kernel实现了一个高效的vRouter(虚拟路由)来负责数据转发,它会为每个容器分配一个ip,每个节点都是路由,把不同host的容器连接起来,从而实现跨主机间容器通信。而每个vRouter通过BGP协议(边界网关协议)负责把自己节点的路由信息向整个Calico网络内传播——小规模部署可以直接互联,大规模下可通过指定的BGProute reflector来完成;Calico基于iptables还提供了丰富而灵活的网络策略,保证通过各个节点上的ACLs来提供多租户隔离、安全组以及其他可达性限制等功能。
Calico是一种非常复杂的网络组件,它需要自己的etcd数据库集群来存储自己通过BGP协议获取的路由等各种所需要持久保存的网络数据信息,因此在部署Calico时,早期是需要单独为Calico部署etcd集群的,因为在k8s中,访问etcd集群只有APIServer可以对etcd进行读写,其它所有组件都必须通过APIServer作为入口,将请求发给APIServer,由APIServer来从etcd获取必要信息来返回给请求者,但Caclico需要自己写,因此就有两种部署Calico网络插件的方式,一种是部署两套etcd,另一种就是Calico不直接写,而是通过APIServer做为代理,来存储自己需要存储的数据。通常第二种使用的较多,这样可降低系统复杂度。 当然由于Calico本身很复杂,但由于很多k8s系统可能存在的问题是,早期由于各种原因使用了flannel来作为网络插件(flannel会讲解原因)。
下图描述了从源容器经过源宿主机,经过数据中心的路由,然后到达目的宿主机最后分配到目的容器的过程。 整个过程中始终都是根据iptables规则进行路由转发,并没有进行封包,解包的过程,这和flannel比起来效率就会快多了。
calico 跨主机通信 下发 ACL 规则 Calico是一种非常复杂的网络组件,它需要自己的etcd数据库集群来存储自己通过BGP协议获取的路由等各种所需要持久保存的网络数据信息,因此在部署Calico时,早期是需要单独为Calico部署etcd集群的,因为在k8s中,访问etcd集群只有APIServer可以对etcd进行读写,其它所有组件都必须通过APIServer作为入口,将请求发给APIServer,由APIServer来从etcd获取必要信息来返回给请求者,但Caclico需要自己写,因此就有两种部署Calico网络插件的方式,一种是部署两套etcd,另一种就是Calico不直接写,而是通过APIServer做为代理,来存储自己需要存储的数据。通常第二种使用的较多,这样可降低系统复杂度。 当然由于Calico本身很复杂,但由于很多k8s系统可能存在的问题是,早期由于各种原因使用了flannel来作为网络插件,但后期发现需要使用网络策略的需求,怎么办? 目前比较成熟的解决方案是:flannel + Calico, 即使用flannel来提供简单的网络管理功能,而使用Calico提供的网络策略功能。
3.2.4 calico网络模式
1.ipip模式 把一个IP数据包又套在一个IP包里,即把IP层封装到IP层的一个tunnel,它的作用其实基本上就相当于一个基于IP层的网桥,一般来说,普通的网桥是基于mac层的,根本不需要IP,而这个ipip则是通过两端的路由做一个tunnel,把两个本来不通的网络通过点对点连接起来; calico以ipip模式部署完毕后,node上会有一个tunl0的网卡设备,这是ipip做隧道封装用的,也是一种overlay模式的网络。当我们把节点下线,calico容器都停止后,这个设备依然还在,执行 modprobe -r ipip 命令可以将它删除。
9: tunl0@NONE: <NOARP,UP,LOWER_UP> mtu 1440 qdisc noqueue state UNKNOWN qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
inet 10.233.110.0/32 brd 10.233.110.0 scope global tunl0
valid_lft forever preferred_lft forever
官方提供的calico.yaml模板里,默认打开了ip-ip功能,该功能会在node上创建一个设备tunl0,容器的网络数据会经过该设备被封装一个ip头再转发。这里,calico.yaml中通过修改calico-node的环境变量:CALICO_IPV4POOL_IPIP来实现ipip功能的开关:默认是Always,表示开启;Off表示关闭ipip。
# kubectl get daemonsets. calico-node -n kube-system -o yaml | grep -iA 1 ipip
- name: CALICO_IPV4POOL_IPIP
value: "Always"
当然Linux支持的五种ip隧道,可以通过ip tunnel help查看
[root@centos7 ~]# ip tunnel help
Usage: ip tunnel { add | change | del | show | prl | 6rd } [ NAME ]
[ mode { ipip | gre | sit | isatap | vti } ] [ remote ADDR ] [ local ADDR ]
ipip:即IPv4 in IPv4,在IPv4报文的基础上再封装一个IPv4报文。 gre:即通用路由封装(Generic Routing Encapsulation),定义了在任意一种网络层协议上封装其他任意一种网络层协议的机制,IPv4和IPv6都适用。 sit:和ipip类似,不同的是sit是用IPv4报文封装IPv6报文,即IPv6 over IPv4。 isatap:即站内自动隧道寻址协议(Intra-Site Automatic Tunnel Addressing Protocol),和sit类似,也是用于IPv6的隧道封装。 vti:即虚拟隧道接口(Virtual Tunnel Interface),是cisco提出的一种IPsec隧道技术。 2.BGP模式 边界网关协议(BorderGateway Protocol, BGP)是互联网上一个核心的去中心化的自治路由协议。它通过维护IP路由表或‘前缀’表来实现自治系统(AS)之间的可达性,属于矢量路由协议。BGP不使用传统的内部网关协议(IGP)的指标,而是基于路径、网络策略或规则集来决定路由。因此,它更适合被称为矢量性协议,而不是路由协议,通俗的说就是将接入到机房的多条线路(如电信、联通、移动等)融合为一体,实现多线单IP;
BGP机房的优点:服务器只需要设置一个IP地址,最佳访问路由是由网络上的骨干路由器根据路由跳数与其它技术指标来确定的,不会占用服务器的任何系统。
3.2.5 Calico网络策略:
Egress:是出站的流量,即自己是源,远端为服务端,因此我自己的源IP可确定,但端口不可预知, 目标的端口和IP都是确定的,因此to 和 ports都是指目标的IP和端口。 Ingress:是入站的流量,即自己为目标,而远端是客户端,因此要做控制,就只能对自己的端口 和 客户端的地址 做控制。 我们通过Ingress 和 Egress定义的网络策略是对一个Pod生效 还是 对一组Pod生效? 这个就要通过podSelector来实现了。 而且在定义网络策略时,可以很灵活,如:入站都拒绝,仅允许出站的; 或 仅允许指定入站的,出站都允许等等。 另外,在定义网络策略时,也可定义 在同一名称空间中的Pod都可以自由通信,但跨名称空间就都拒绝。
网络策略的生效顺序: 越具体的规则越靠前,越靠前,越优先匹配
网络策略的定义: kubectl explain networkpolicy spec: egress: <[]Object> :定义出站规则 ingress: <[]Object>: 定义入站规则 podSelector: 如论是入站还是出站,这些规则要应用到那些Pod上。 policyType:[Ingress|Egress| Ingress,Egress] : 它用于定义若同时定义了egress和ingress,到底那个生效?若仅给了ingress,则仅ingress生效,若设置为Ingress,Egress则两个都生效。 注意:policyType在使用时,若不指定,则当前你定义了egress就egress生效,若egress,ingress都定义了,则两个都生效!! 还有,若你定义了egress, 但policyType: ingress, egress ; egress定义了,但ingress没有定义,这种要会怎样? 其实,这时ingress的默认规则会生效,即:若ingress的默认规则为拒绝,则会拒绝所有入站请求,若为允许,则会允许所有入站请求, 所以,若你只想定义egress规则,就明确写egress !!
egress:<[]Object> ports: <[]Object> :因为ports是有端口号 和 协议类型的,因此它也是对象列表 port : protocol: 这两个就是用来定义目标端口和协议的。 to :<[]Object> podSelector: : 在控制Pod通信时,可控制源和目标都是一组Pod,然后控制这两组Pod之间的访问。 ipBlock:<[]Object> : 指定一个Ip地址块,只要在这个IP范围内的,都受到策略的控制,而不区分是Pod还是Service。 namespaceSelector: 这是控制对指定名称空间内的全部Pod 或 部分Pod做访问控制。
Ingress: from: 这个from指访问者访问的IP ports: 也是访问者访问的Port
#定义网络策略:
vim networkpolicy-demo.yaml
apiVersion: networking.k8s.io/v1
#注意:虽然kubectl explain networkpolicy中显示为 extensions/v1beta1 ,但你要注意看说明部分.
kind: NetworkPolicy
metadata:
name: deny-all-ingress
namespace: dev
spec:
podSelector: {} #这里写空的含义是,选择指定名称空间中所有Pod
policyTypes:
- Ingress #这里指定要控制Ingress(进来的流量),但又没有指定规则,就表示全部拒绝,只有明确定义的,才是允许的。
#egress: 出去的流量不控制,其默认规则就是允许,因为不关心,所以爱咋咋地的意思。
#写一个简单的自主式Pod的定义:
vim pod1.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod1
spec:
containers:
- name: myapp
image: harbor.zcf.com/k8s/myapp:v1
#创建dev名称空间,并应用规则
kubectl apply -f networkpolicy-demo.yaml -n dev
# kubectl describe -n dev networkpolicies
Name: deny-all-ingress
Namespace: dev
........................
Spec:
PodSelector: <none> (Allowing the specific traffic to all pods in this namespace)
Allowing ingress traffic:
<none> (Selected pods are isolated for ingress connectivity)
Allowing egress traffic:
<none> (Selected pods are isolated for egress connectivity)
#查看dev名称空间中的网络规则:
kubectl get networkpolicy -n dev
或
kubectl get netpol -n dev
#然后在dev 和 prod 两个名称空间中分别创建pod
kubectl apply -f pod1.yaml -n dev
kubectl apply -f pod1.yaml -n prod
#接着测试访问这两个名称空间中的pod
kubectl get pod -n dev -o wide
#测试访问:
curl http://POD_IP
kubectl get pod -n prod -o wide
#测试访问:
curl http://POD_IP
#通过以上测试,可以看到,dev名称空间中的pod无法被访问,而prod名称空间中的pod则可被访问。
#测试放行所有dev的ingress入站请求。
# vim networkpolicy-demo.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all-ingress
namespace: dev
spec:
podSelector: {}
ingress:
- {} #这就表示允许所有,因为定义了规则,但规则是空的,即允许所有。
policyTypes:
- Ingress
#接着测试,和上面测试一样,也是访问dev 和 prod两个名称空间中的pod,若能访问,则成功。
# kubectl describe -n dev netpol
Name: deny-all-ingress
Namespace: dev
.....................
Spec:
PodSelector: <none> (Allowing the specific traffic to all pods in this namespace)
Allowing ingress traffic:
To Port: <any> (traffic allowed to all ports)
From: <any> (traffic not restricted by source)
Allowing egress traffic:
<none> (Selected pods are isolated for egress connectivity)
Policy Types: Ingress
#先给pod1打上app=myapp的标签 #kubectl label pod pod1 app=myapp -n dev vim allow-dev-80.yaml apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-myapp-ingress spec: podSelector: matchLabels: app: myapp ingress: - from: - ipBlock: cidr: 10.10.0.0/16 except: - 10.10.1.2/32 ports: - protocol: TCP port: 88 - protocol: TCP port: 443 #查看定义的ingress规则 kubectl get netpol -n dev #然后测试访问 dev 名称空间中的pod curl http://Pod_IP curl http://Pod_IP:443 curl http://Pod_IP:88
上图测试:
1. 先给dev名称空间打上标签
kubectl label namespace dev ns=dev
2. 编写网络策略配置清单
vim allow-ns-dev.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-ns-dev
spec:
podSelector: {}
ingress:
- from:
- namespaceSelector:
matchLabels:
ns: dev
egress:
- to:
- namespaceSelector:
matchLabels:
ns: dev
#要控制egress,也是如此,只是将ingress替换为egress即可,然后在做测试。
另外,关于网络策略,建议:
名称空间内:
拒绝所有出站,入站流量
仅放行出站目标为当前名称空间内各Pod间通信,因为网络策略控制的颗粒度是Pod级别的,不是名称空间级别。
具体的网络策略,要根据实际需求,来定义ingress 和 egress规则。
(1)节点组网时可以直接利用数据中心的网络结构(L2或者L3),不需要额外的NAT、隧道或者Overlay Network,没有额外的封包解包,能够节约CPU运算,提高网络效率。
(2) 在小规模集群中可以直接互联,在大规模集群中可以通过额外的BGP route reflector来完成。
(3) 基于iptables或ipvs还提供了丰富的网络策略,实现了Kubernetes的Network Policy策略,提供容器间网络可达性限制的功能。
Calico是Kubernetes生态系统中另一种流行的网络选择。虽然Flannel被公认为是最简单的选择,但Calico以其性能、灵活性而闻名。Calico的功能更为全面,不仅提供主机和pod之间的网络连接,还涉及网络安全和管理。Calico CNI插件在CNI框架内封装了Calico的功能。
在满足系统要求的新配置的Kubernetes集群上,用户可以通过应用单个manifest文件快速部署Calico。如果您对Calico的可选网络策略功能感兴趣,可以向集群应用其他manifest,来启用这些功能。
尽管部署Calico所需的操作看起来相当简单,但它创建的网络环境同时具有简单和复杂的属性。与Flannel不同,Calico不使用overlay网络。相反,Calico配置第3层网络,该网络使用BGP路由协议在主机之间路由数据包。这意味着在主机之间移动时,不需要将数据包包装在额外的封装层中。BGP路由机制可以本地引导数据包,而无需额外在流量层中打包流量。
除了性能优势之外,在出现网络问题时,用户还可以用更常规的方法进行故障排除。虽然使用VXLAN等技术进行封装也是一个不错的解决方案,但该过程处理数据包的方式同场难以追踪。使用Calico,标准调试工具可以访问与简单环境中相同的信息,从而使更多开发人员和管理员更容易理解行为。
除了网络连接外,Calico还以其先进的网络功能而闻名。 网络策略是其最受追捧的功能之一。此外,Calico还可以与服务网格Istio集成,以便在服务网格层和网络基础架构层中解释和实施集群内工作负载的策略。这意味着用户可以配置强大的规则,描述Pod应如何发送和接受流量,提高安全性并控制网络环境。
如果对你的环境而言,支持网络策略是非常重要的一点,而且你对其他性能和功能也有需求,那么Calico会是一个理想的选择。此外,如果您现在或未来有可能希望得到技术支持,那么Calico是提供商业支持的。一般来说,当您希望能够长期控制网络,而不是仅仅配置一次并忘记它时,Calico是一个很好的选择。
Calico:
IPIP/BGP 2 个方案都有不错的表现,其中 IPIP 的方案在 big meg size 上的表现更好,但在 128 字节的时候表现异常,多次测试依然一样。BGP 方案比较稳定, CPU 消耗并没有 IPIP 大,当然带宽表现也稍微差点。不过整体上来说,无论是 BGP 还是 IPIP Tunnel , Calico 这套 Overlay SDN 的解决方案成熟度和可用性都是相当不错的,是上云首选。
优势:性能好,可控性高,隔离性好。
劣势:操作起来比较复杂,对 Iptables 有依赖。
https://github.com/projectcalico/cni-plugin
3.3 Weave
Weave是由Weaveworks提供的一种Kubernetes CNI网络选项,它提供的模式和我们目前为止讨论的所有网络方案都不同。Weave在集群中的每个节点之间创建网状Overlay网络,参与者之间可以灵活路由。这一特性再结合其他一些独特的功能,在某些可能导致问题的情况下,Weave可以智能地路由。 为了创建网络,Weave依赖于网络中每台主机上安装的路由组件。然后,这些路由器交换拓扑信息,以维护可用网络环境的***视图。当需要将流量发送到位于不同节点上的Pod时,Weave路由组件会自动决定是通过“快速数据路径”发送,还是回退到“sleeve”分组转发的方法。 快速数据路径依靠内核的本机Open vSwitch数据路径模块,将数据包转发到适当的Pod,而无需多次移入和移出用户空间。Weave路由器会更新Open vSwitch配置,以确保内核层具有有关如何路由传入数据包的准确信息。相反,当网络拓扑不适合快速数据路径路由时,sleeve模式可用作备份。它是一种较慢的封装模式,在快速数据路径缺少必要的路由信息或连接的情况下,它可以来路由数据包。当流量通过路由器时,它们会了解哪些对等体与哪些MAC地址相关联,从而允许它们以更少的跳数、更智能地路由后续流量。当网络更改导致可用路由改变时,这一相同的机制可以帮助每个节点进行自行更正。 与Calico一样,Weave也为Kubernetes集群提供网络策略功能。设置Weave时,网络策略会自动安装和配置,因此除了添加网络规则之外,用户无需进行其他配置。一个其他网络方案都没有、Weave独有的功能,是对整个网络的简单加密。虽然这会增加相当多的网络开销,但Weave可以使用NaCl加密来为sleeve流量自动加密所有路由流量,而对于快速数据路径流量,因为它需要加密内核中的VXLAN流量,Weave会使用IPsec ESP来加密快速数据路径流量。 对于那些寻求功能丰富的网络、同时希望不要增加大量复杂性或管理难度的人来说,Weave是一个很好的选择。它设置起来相对容易,提供了许多内置和自动配置的功能,并且可以在其他解决方案可能出现故障的场景下提供智能路由。网状拓扑结构确实会限制可以合理容纳的网络的大小,不过对于大多数用户来说,这也不是一个大问题。此外,Weave也提供收费的技术支持,可以为企业用户提供故障排除等等技术服务。 https://www.weave.works/oss/net/
3.4 Canal
Canal也是⼀个有趣的选择,原因有很多。 ⾸先,Canal 是⼀个项⽬的名称,它试图将Flannel提供的⽹络层与Calico的⽹络策略功能集成在⼀起。然⽽,当贡献者 完成细节⼯作时却发现,很明显,如果Flannel和Calico这两个项⽬的标准化和灵活性都已各⾃确保了话,那集成也就没 那么⼤必要了。结果,这个官⽅项⽬变得有些“烂尾”了,不过却实现了将两种技术部署在⼀起的预期能⼒。出于这个原 因,即使这个项⽬不复存在,业界还是会习惯性地将Flannel和Calico的组成称为“Canal”。 由于Canal是Flannel和Calico的组合,因此它的优点也在于这两种技术的交叉。⽹络层⽤的是Flannel提供的简单 overlay,可以在许多不同的部署环境中运⾏且⽆需额外的配置。在⽹络策略⽅⾯,Calico强⼤的⽹络规则评估,为基础 ⽹络提供了更多补充,从⽽提供了更多的安全性和控制。 ⼀般来说,如果你喜欢Flannel提供的⽹络模型,但发现Calico的⼀些功能很诱⼈,那么不妨尝试⼀下Canal。从安全⾓ 度来看,定义⽹络策略规则的能⼒是⼀个巨⼤的优势,并且在许多⽅⾯是Calico的杀⼿级功能。能够将该技术应⽤到熟 悉的⽹络层,意味着您可以获得更强⼤的环境,且可以省掉⼤部分的过渡过程。
3.5 flannel对比calico
flannel 原理 对比
从上述的原理可以看出,flannel在进行路由转发的基础上进行了封包解包的操作,这样浪费了CPU的计算资源。下图是从网上找到的各个开源网络组件的性能对比。可以看出无论是带宽还是网络延迟,calico和主机的性能是差不多的。
Kubernetes采用的CNI标准,让Kubernetes生态系统中的网络解决方案百花齐放。更多样的选择,意味着大多数用户将能够找到适合其当前需求和部署环境的CNI插件,同时还可以在环境发生变化时也能找到新的解决方案。
不同企业之间的运营要求差异很大,因此拥有一系列具有不同复杂程度和功能丰富性的成熟解决方案,大大有助于Kubernetes在满足不同用户独特需求的前提下,仍然能够提供一致的用户体验。