本文的学习资源来自Java学习视频教程:Java核心技术(高级)_华东师范大学_中国大学MOOC(慕课) 本文的学习笔记是正确的Java核心技术课程的总结也是对自己学习的总结
文章目录
-
- Java核心技术(高级)
-
-
- 第一章:Maven
-
- 当前主要的Java构建工具
- Maven基本概念:
- Maven安装与配置
- Maven本地仓库配置
- Maven工程结构
- 常见Maven命令:(与项目建设的生命周期有关)
- Maven坐标(gav)
- Maven开发流程
- 第二章:单元测试和JUnit
-
- 1、单元测试
- 2、JUnit :Java单元测试框架
- 第三章:高级文本处理:
-
- 第一节:Java字符编码
- 第二节:Java国际化编程
- 第三节:Java高级字符串处理
- 一、概念
- 二、元字符
- Java正则表达式
- 第四章 处理高级文件
-
- 1、xml简介
- 2、xml解析
- 3、JSON简介及解析
- 4.图形图像及分析
- 5.条形码和二维码的分析
- 6、Docx简介及解析
- 7.表格文件简介及分析
- 8、PDF简介及解析
- 第五章:Java多线程并发编程
-
- 1.多过程和多线程简介
- 2、Java多线程实现
- 3、Java共享多线程信息
- 4、Java多线程生命周期管理
- 5、Java并发框架Executor
- 6、Java并发框架Fork-join
- 7、Java并发数据结构
- 8、Java并发协作控制
- 9、Java执行定期任务
- 第六章 Java网络编程
-
- 1.网络基础知识
- 2、Java UDP编程
- 3、Java TCP编程
- 4、Java HTTP编程
- 5、Java HTTP编程(HttpClient)
- 6、Java NIO编程
- 7、Java AIO编程
- 8、Netty编程
- 9.邮件基础知识
- 10、Java Mail编程
- 第七章 Java数据库编程
-
- 1、数据库和SQL
- 2、JDBC基本操作
- 3、JDBC高级操作
- 4.数据库连接池
- 第八章 Java混合编程
-
- 1、Java调用Java程序(RMI)
- 2、Java调用C程序(JNI)
- 3、Java调用JavaScript程序(Nashorn)
- 4、Java调用Python程序(Jyphon)
- 5、Java调用Web Service
- 6、Java调用命令行
- Java进阶总结
-
- 需要熟悉的内容
-
Java核心技术(高级)
Java核心技术(进阶)内容:应用
- 庞大的第三方库
- 与其他系统/编程语言交互
- 文件、数据库、网络、C、JavaScript、Python
Java先进核心技术的主要内容:
- Java构建工具:Maven
- Java单元测试:Junit
- 处理高级文件
- 多线程并发
- 网络和邮件
- 数据库
- Java与其他语言互动
- Java和java、C、JS、Python等
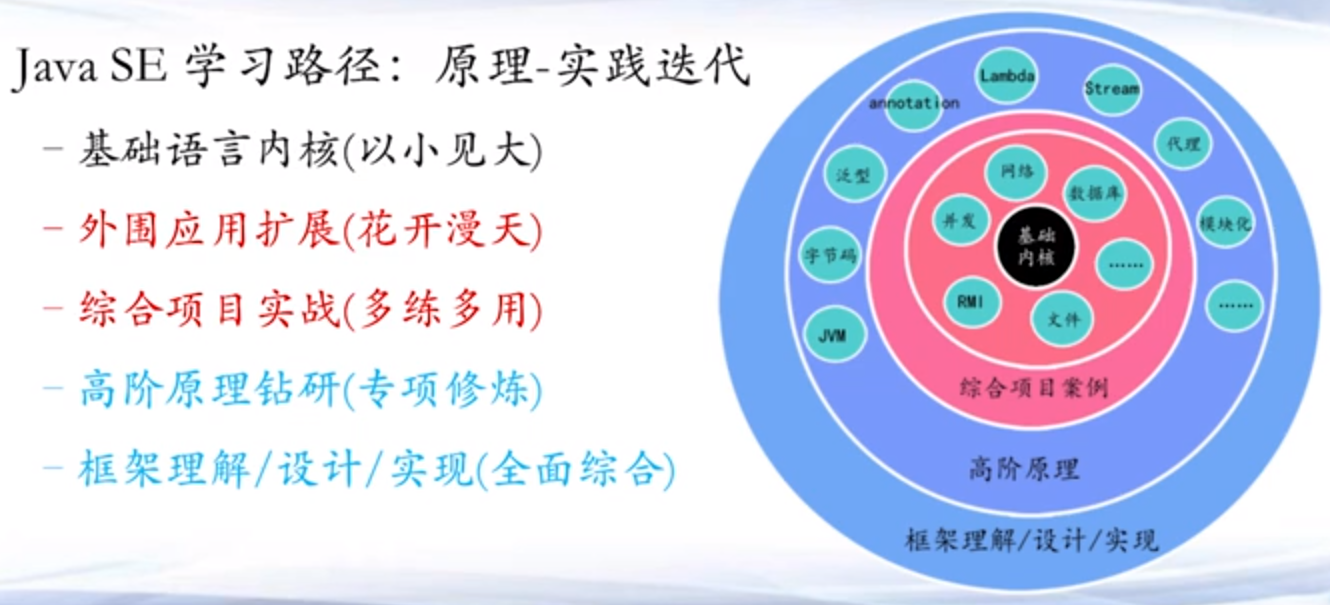
第一章:Maven
当前主要的Java构建工具
- Maven,Gradle,Ivy,Builder,Ant等
Maven基本概念:
- apache组织提供的顶级项目由组织提供Java开发
- 作用:
- 管理项目构建生命周期
- 管理项目中jar()。自动帮程序员筛选和下载第三方库(jar)
- 管理项目基本信息(文件管理、测试报告)
1、项目构建生命周期:
[清理]–>[编译]–>[测试]–>[报告]–>[打包]–>[安装]–>[发布]
[clean]–>[compile]–>[test]–>[report]–>[package]–>[install]–>[publish]
2、项目中jar包管理
[本地仓库]–>[局域网私服仓库]–>[中央仓库]
3、Maven项目信息管理
- api文档
- 测试报告
Maven安装与配置
解压即可
Maven插件结构:
bin
boot 插件
conf 配置文件
lib
IDEA自带Maven位于D:\DevTools\ideaIU-2020.2.3.win\plugins\maven\lib\maven3目录下,
查看版本号:在maven3/bin目录下,调出cmd,输入mvn -v
所以Maven原本是不需要配置的。只是为了在任何路径下都可以使用Maven命令,所以需要配置
- JAVA_HOME
- MAVEN-HOME:Maven安装地址
- [path] %MAVEN-HOME%\bin
Maven本地仓库配置
本地仓库默认位置:
C:\Users\Administrator\.m2\repository
重新设置Maven本地仓库地址
Maven安装路径\conf\setting.xml中定位标签
#53 /path/to/local/repository
重新设置本地仓库位置
D:\DevTools\ideaIU-2020.2.3.win\plugins\maven\repository
阿里云镜像设置
在mirror位置(大约160行左右)添加阿里云镜像
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
Maven工程结构
-
Maven可以管理的工程,必须按照【约定结构】来创建
-
结构
-
src:(Java代码)
-
main文件夹:主要开发 业务程序
-
java(创建Java文件)
Java文件创建package,如 src\main\java\com\bjpowernode\model\Student.java -
resources(存放程序资源文件(配置文件,properties))
-
-
test:主要进行测试 单元测试程序
-
Java(创建测试类)
Java文件创建测试类,如 src\main\java\com\bjpowernode\model\TestMain.java -
resources(存放测试程序资源文件(测试时使用的配置文件))
-
-
-
target文件夹:(编译后class文件,在创建项目时,不需要创建。Maven命令在执行时自动创建target)
目录如图:
-
pom.xml:(核心配置文件:主要用来向Maven讨要jar包)(Project Object Model)
-
eg:记事本开发Maven工程
Student.java
package com.bjpowernode.model;
public class Student{
public void sayHello(){
System.out.print("Hello Maven");
}
}
TestMain.java
package com.bjpowernode.test;
import com.bjpowernode.model.Student;
import org.junit.Test;
public class TestMain{
@Test
public void myTest (){
Student stu=n ew Student();
stu.sayHello();
}
}
包含了项目信息,依赖信息、构建信息
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion> //固定不变的
//这三行是定位package的,简称gav
<groupId>com.bjpowernode</groupId> //域名
<artifactId>Maven_Project</artifactId> //项目名,不能有中文
<version>6.0</version> //版本号
//<package>war</package> //这一行通常为默认jar或war,需要时手动添加
//添加依赖
<dependencies>
//所需的依赖可以到百度Maven Repository,搜索相关包名,获取gav
<!-- https://mvnrepository.com/artifact/junit/junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
常见Maven命令:(与项目构建生命周期相关)
1、mvn clean 删除当前工程中target
2、mvn compile 将当前工程中main文件下的所有java编译为class,输送到target文件中
3、mvn test 运行test文件下所有测试文件
4、mvn package 首先将test文件下所有的java测试类的方法调用执行进行测试,并生成[测试报告]。如果测试没有问题,将main文件下所有class文件打成(jar/war),然后输送到target
5、mvn install 与package命令执行基本一致,将[jar\war]推送到Maven的本地仓库
Maven坐标(gav)
为了方便Maven对jar的定位,在Maven世界中,每一个jar都要由一个独立坐标,相当于ip
artifact:构建
这个独立坐标由三部分组成
- 公司域名反顺序 组织
- 项目名称 产品名称
- 项目版本号 版本
Maven开发流程
- 新建Maven项目
- 在中央仓库查找第三方jar的依赖文本
- 拷贝依赖文本至项目的pom.xml
- 执行Maven,编译/构建整个项目
第二章:单元测试和JUnit
1、单元测试
软件测试分类
- 单元测试VS集成测试
- 白盒测试VS黑盒测试
- 自动测试VS手动测试
- 回归测试:修改旧代码后,重新进行测试以确认修改没有引入新的错误或导致其他代码产生错误
- 压力测试
- 。。。
2、JUnit :Java单元测试框架
目前JUnit包含JUnit3,JUnit4,JUnit5,主流使用JUnit4
每一个测试方法的头部加@Test(注解),这样JUnit会自动执行这些测试方法
eg:Triangle
package com.ouc.test;
import static org.junit.Assert.*;//导入Assert类的所有静态方法,自JDK1.5引入
import com.ouc.model.Triangle;
import org.junit.Assert;
import org.junit.Test;
public class TestTriangle {
@Test
public void test(){
assertEquals(false,new Triangle().JudgeEdges(1,2,3));//静态assert方法
//Assert.assertEquals(false,new Triangle().JudgeEdges(1,2,3));//动态assert方法
}
}
JUnit单元测试一次只能测试一个JUnit test,Maven将test文件夹下测试所有test类
第三章:高级文本处理
第一节:Java字符编码
- UTF-8 兼容ASCII,变长(1-4个字节存储字符),经济,方便传输
- UTF-16 用变长(2-4个字节)来存储所有字符
- UTF-32 用32bits(4个字节)存储所有字符
- Windows上非Unicode的默认编码
- 在简体中文Windows操作系统中,ANSI编码代表GBK编码
- 在繁体中文Windows操作系统中,ANSI编码代表Big5
- ANSI编码文件不能兼容使用
- 源文件编码:采用UTF-8编码
- 程序内部采用UTF-16编码存储所有字符(不是程序员控制)
- 和外界(文本文件)的输入输出尽量采用UTF-8编码
- 不能使用一种编码写入,换另一种编码读取
第二节:Java国际化编程
Java是第一个设计成支持国际化的编程语言
- java.util.ResourceBundle 用于加载一个语言_国家语言包
- java.util.Locale 定义一个语言_国家
Locale(zh_CN,en_US,…)
- 语言,zh,en等
- 国家/地区,CN,US等
- 其他变量(几乎不用)
Locale方法
- getAvailableLocales()返回所有的可用的Locale
- getDefault()返回默认的Locale
语言文件
- 一个Properties文件
- 包含K-V对,每行一个K-V,例如age=20
- 命名规则
- 包名+语言+国家地区.properties,(语言和国家地区可选)
- message.properties
- message_zh.properties
- message_zh_CN.properties
- 存储文件必须是ASCII文件,如果是ASCII以外的文字,必须使用Unicode表示\uxxxx,也可以采用native2ascii.exe(%JAVA_HOME\bin%目录下)进行转码
ResourceBundle类
- ResourceBundle
- 根据Locale要求,加载语言文件(Properties)
- 存储所有的K-V对
- getString(String key)返回所对应的value
- ResourceBundle根据key找value的查找路径
- 包名_当前Locale语言__当前Locale国家地区
- 包名_当前Locale语言
- 包名
eg:
创建txt文件,内容:hello=你好,世界
调用jdk下的native2ascii.exe转码,cmd命令行下输入
native2ascii.exe a.txt message_zh_CN.properties
将message_zh_CN.properties放在main\resources下,
public static void main(String[] args) {
//取得系统默认的国家/语言环境
Locale myLocale = Locale.getDefault();
//myLocale=new Locale("en","US");//强制转化en_US
System.out.println("myLocale = " + myLocale);//zh_CN //en_US
//根据指定语言_国家环境加载资源文件
ResourceBundle bundle = ResourceBundle.getBundle("message", myLocale);
System.out.println("bundle.getString(\"hello\") = " + bundle.getString("hello"));
}
第三节:Java高级字符串处理
(REGEX)(Regular Express)
一、概念
- **检索:**通过正则表达式,从字符串中获取我们想要的部分
- **匹配:**判断给定的字符串是否符合正则表达式的过滤逻辑
就是由普通字符以及特殊字符(称为元字符)组成的文字模式。该模式描述在查找文字主体时待匹配的一个或多个字符串。正则表达式用来描述字符串的特征。
正则表达式是非常复杂的,理解正则表达式能做什么(字符串匹配、字符串提取、字符串替换),掌握常用的正则表达式用法。
-
在正则表达式中有三种类型的括号,[]、{}、()。中括号[]内是需要匹配的字符,大括号{}内是指定匹配字符的数量,小括号()则是用来改变优先级或分组的
-
插入符号"^"表示正则式的开始
-
美元符号"$"表示正则式的结束
eg:Regex obj = new Regex("[a-z]{10}]");//搜索长度为10的a-z的英文字母
二、元字符
. 除\n以外的任意的单个字符 注:有且只有一个
[] 字符组:[]表示在字符组中罗列出来的字符,任意取单个。 eg:a[a-zA-Z王]b -表示范围,-在第一位时只表示一个字符,不表示元字符
以下是通配符:
| 表示“或”的意思 正则表达式尽量减少“|”的使用,“|”越多,越消耗性能
* 表示限定前面的表达式出现0次或者多次
+ 表示一次或多次,至少一次
? 表示出现0次或1次
{} 指定匹配字符的数量 eg:[0-9]{8} [a-z]{4,}
[0-9] \d \D取余
[a-zA-Z0-9_] \w \W取余
\s 表示所有不可见字符
注:要想完全匹配,必须要加^和$
Java的正则表达式
java.util.regex包
- Pattern 正则表达式的编译表示
- compile 编译一个正则表达式为Pattern对象
- matcher 用Pattern对象匹配一个字符串,返回匹配结果
- Matcher
- Index Methods(位置方法) //start(),start(int group),end(),end(int group)
- Search Methods(查找方法) //lookingAt(),find(),find(int start),matches()
- lookingAt()//部分匹配
- matches()//完全匹配
- Replacement Methods(替换方法) //replaceAll(String replacement)
eg
private static final String REGEX = "\\bdog\\b";//\b表示边界
private static final String INPUT = "dog dog dog doggie dogg";
public static void main(String[] args) {
//检查字符串里面有多少个dog
Pattern p = Pattern.compile(REGEX);
Matcher m = p.matcher(INPUT);
int count = 0;
while (m.find()) {
count++;
System.out.println("count = " + count);
System.out.println("m = " + m.start());
System.out.println("m.end() = " + m.end());
}
}
private static final String REGEX = "Foo";
private static final String INPUT = "Foooooooo";
private static Pattern pattern;
private static Matcher matcher;
public static void main(String[] args) {
//Initialize
pattern = Pattern.compile(REGEX);
matcher = pattern.matcher(INPUT);
System.out.println("REGEX = " + REGEX);
System.out.println("INPUT = " + INPUT);
System.out.println("matcher.lookingAt() = " + matcher.lookingAt());//部分匹配
System.out.println("matcher.matches() = " + matcher.matches());//完全匹配
}
private static String REGEX = "a*b";//*表示限定前面的a可以有0或多个
private static String INPUT = "aabfooaabfooabfoobcdd";
private static String REPLACE = "-";
public static void main(String[] args) {
Pattern pattern = Pattern.compile(REGEX);
Matcher matcher = pattern.matcher(INPUT);
StringBuffer stringBuffer = new StringBuffer();
//全部替换
while (matcher.find()) {
matcher.appendReplacement(stringBuffer, REPLACE);
}
//将最后的尾巴字符串附加上
matcher.appendTail(stringBuffer);
System.out.println("stringBuffer.toString() = " + stringBuffer.toString());
}
private static String REGEX="dog";
private static String INPUT="The dog says meow.All dogs say meow.";
private static String REPLACE="cat";
public static void main(String[] args) {
Pattern pattern=Pattern.compile(REGEX);
Matcher matcher=pattern.matcher(INPUT);
INPUT=matcher.replaceAll(REPLACE);//将所有的dog换成cat
System.out.println("INPUT = " + INPUT);
}
- 集合和字符串互转
public static void main(String[] args) {
List<String> names = new LinkedList<>();
names.add("xiaohong");
names.add("xiaoming");
names.add("daming");
//从ArrayList变到字符串
String str1=String.join(",",names);
System.out.println("str1 = " + str1);
//JDK自带的String.join方法只能拼接字符串元素
//使用Apache Commons Lang的StringUtils.join方法可以拼接更多类型的元素
String str2= StringUtils.join(names,",");
System.out.println("str2 = " + str2);
//从字符串转到ArrayList
List<String> names2= Arrays.asList(str1.split(","));
for (String name :
names2) {
System.out.println("name = " + name);
}
//StringUtils可以支持更多数据类型
ArrayList<Integer> ids = new ArrayList<>();
ids.add(1);
ids.add(5);
ids.add(3);
String str3=StringUtils.join(ids,",");
System.out.println("str3 = " + str3);
}
第四章 高级文件处理
1、xml简介
XML:可扩展标记语言
纯文本表示,跨系统/平台/语言
区分大小写
1、文档声明
2、元素=标签
3、属性
4、注释
5、CDATA区、特殊字符<!CDATA[不想解析的内容]>
文档中必须要有一个根标签
<?xml version="1.0" encoding="UTF-8"?>
注:xml必须要有根节点,且只能有一个节点
<student></student>
<student name='xiaoming'></student>
<!--注释-->
< <
> >
" "
' '
- 定义xml文档的结构,DTD(Document Type Definition)的继任者
- 支持数据类型,可扩展,功能更完善、强大
- 扩展样式表语言(eXtensible Stylesheet Language)
- XSL作用于XML,等同于CSS作用于HTML
2、xml解析
- 树结构
- DOM:Document Object Model文档对象模型,擅长(小规模)读/写
- 流结构
- SAX:Simple API for XML 流机制解释器(推模式),擅长读
- Stax:The Streaming API for XML 流机制解释器(拉模式),擅长读
- DocumentBuilder解析类,parse方法
- Node节点主接口,getChildNodes返回一个NodeList
- NodeList节点列表,每个元素是一个Node
- 注意:标签和标签之间的空格也会被上级父节点视为子元素
- Document文档根节点
- Element标签节点元素(每一个标签都是标签节点)
- Text节点(包含在XML元素内的,都算Text节点)
- Attr节点(每个属性节点)
eg:
DOMReader:
//自上而下进行访问
public static void RecursiveTraverse() {
try {
//采用DOM解析XML文件
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db=dbf.newDocumentBuilder();
Document document= db.parse("users.xml");
//获取所有的一级子节点
NodeList usersList=document.getChildNodes();
System.out.println("usersList.getLength() = " + usersList.getLength()); //1
for (int i = 0; i < usersList.getLength(); i++) {
Node users=usersList.item(i); //1 users
NodeList userList=users.getChildNodes();//获取二级子节点user的列表
System.out.println("userList.getLength() = " + userList.getLength());//9
for (int j = 0; j < userList.getLength(); j++) {
Node user=userList.item(j);
if (user.getNodeType()==Node.ELEMENT_NODE){
NodeList metaList=user.getChildNodes();
System.out.println("metaList.getLength() = " + metaList.getLength());//7
for (int k = 0; k < metaList.getLength(); k++) {
//到最后一级文本
Node meta=metaList.item(k);
if (meta.getNodeType()==Node.ELEMENT_NODE){
System.out.println("metaList.item(k).getTextContent() = " + metaList.item(k).getTextContent());
}
}
}
}
}
System.out.println();
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
}
}
//根据名字进行搜索
public static void TraverseBySearch() {
try {
//采用DOM解析XML文件
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
Document document = db.parse("users.xml");
Element rootElement = document.getDocumentElement();
NodeList nodeList = rootElement.getElementsByTagName("name");
if (nodeList != null) {
for (int i = 0; i < nodeList.getLength(); i++) {
Element element = (Element) nodeList.item(i);
System.out.println("element.getTextContent() = " + element.getTextContent());
}
}
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
DOMWriter
public static void main(String[] args) {
try {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
//新创建一个Document节点
Document document = builder.newDocument();
if (document != null) {
Element docx = document.createElement("document");
Element element = document.createElement("element");
element.setAttribute("type", "para");
element.setAttribute("alignment", "left");//element增加2个属性
Element object = document.createElement("object");
object.setAttribute("type", "text");
Element text = document.createElement("text");
text.appendChild(document.createTextNode("abcdefg"));//给text节点赋值
Element bold = document.createElement("bold");
bold.appendChild(document.createTextNode("true"));//给bold节点赋值
object.appendChild(text); //把text节点挂在object下
object.appendChild(bold); //把bold节点挂在object下
element.appendChild(object);
docx.appendChild(element);
document.appendChild(docx); //把docx挂在document下
TransformerFactory transformerFactory = TransformerFactory.newInstance();
Transformer transformer = transformerFactory.newTransformer();
DOMSource source = new DOMSource(document);
//定义目标文件
File file = new File("dom_result.xml");
StreamResult result = new StreamResult(file);
//将xml文件写入到文件中
transformer.transform(source,result);
System.out.println("Write xml file successfully");
}
} catch (ParserConfigurationException | TransformerConfigurationException e) {
e.printStackTrace();
} catch (TransformerException e) {
e.printStackTrace();
}
}
- 采用事件/流模型来解析XML文档,更快速、更轻量
- 有选择的解析和访问,不像DOM加载整个文档,内存要求更低
- SAX对XML文档的解析为一次性读取,不创建/不存储文档对象,很难同时访问文档中的多处数据
- 推模型。当它每发现一个节点就引发一个事件,而我们需要编写这些事件的处理程序。关键类:DefaultHandler
- SAX的5个回调方法
- startDocument 文档开始解析
- endDocument 文档结束解析
- startElement 开始访问元素
- endElement 结束访问元素
- characters 访问元素正文
public class SAXReader {
public static void main(String[] args) throws SAXException, IOException {
XMLReader parser = XMLReaderFactory.createXMLReader();
BoolHandler boolHandler = new BoolHandler();
parser.setContentHandler(boolHandler);
parser.parse("books.xml");
System.out.println("boolHandler = " + boolHandler.getNameList());
}
}
class BoolHandler extends DefaultHandler {
private List<String> nameList;
private boolean title = false;
public List<String> getNameList() {
return nameList;
}
//实现DefaultHandler的5个回调方法
//xml文档加载时
public void startDocument() throws SAXException {
System.out.println("Start parsing document...");
nameList = new ArrayList<String>();
}
//文档解析结束
public void endDocument() throws SAXException {
System.out.println("End");
}
//访问某一个元素
public void startElement(String uri, String localName, String qName, Attributes atts) throws SAXException {
if (qName.equals("title"))
title = true;
}
//结束访问元素
public void endElement(String namespaceURI, String localName, String qName) throws SAXException {
//End of processing current element
if (title) {
title = false;
}
}
//访问元素正文
public void characters(char[] ch, int start, int length) {
if (title) {
String bookTitle = new String(ch, start, length);
System.out.println("bookTitle = " + bookTitle);
nameList.add(bookTitle);
}
}
}
(Streaming API for XML)
- 流模型中的拉模型
- 在遍历文档时,会把感兴趣的部分从读取器中拉出,不需要引发事件,允许我们选择性地处理节点。这大大提高了灵活性,以及整体效率。
- 两套处理API
- 基于指针的API,XMLStreamReader
- 基于迭代器的API,XMLEventReader
eg:
//流模式
public static void readByStream() {
String xmlFile = "books.xml";
XMLInputFactory factory = XMLInputFactory.newFactory();
XMLStreamReader streamReader = null;
try {
streamReader = factory.createXMLStreamReader(new FileReader(xmlFile));
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (XMLStreamException e) {
e.printStackTrace();
}
//基于指针遍历
try {
while (streamReader.hasNext()) {
int event = streamReader.next();
//如果是元素的开始
if (event == XMLStreamConstants.START_ELEMENT) {
//列出所有书籍名称
if ("title".equalsIgnoreCase(streamReader.getLocalName())) {
System.out.println("title: " + streamReader.getElementText());
}
}
}
streamReader.close();
} catch (XMLStreamException e) {
e.printStackTrace();
}
}
//事件模式
public static void readByEvent() {
String xmlFile = "books.xml";
XMLInputFactory factory = XMLInputFactory.newFactory();
boolean titleFlag = false;
try {
//创建基于迭代器的事件读取器对象
XMLEventReader eventReader = factory.createXMLEventReader(new FileReader(xmlFile));
//遍历Event迭代器
while (eventReader.hasNext()) {
XMLEvent event = eventReader.nextEvent();
//如果事件对象是元素的开始
if (event.isStartElement()) {
//转换成开始元素事件对象
StartElement start = event.asStartElement();
//打印元素标签的本地名称
String name = start.getName().getLocalPart();
if (name.equals("title")) {
titleFlag = true;
System.out.println("title:");
}
//取得所有属性
Iterator attrs = start.getAttributes();
while (attrs.hasNext()) {
//打印所有属性信息
Attribute attr = (Attribute) attrs.next();
//System.out.println("attr.getValue() = " + attr.getValue());
}
//如果是正文
if (event.isCharacters()) {
String s = event.asCharacters().getData();
if (null != s && s.trim().length() > 0 && titleFlag) {
System.out.println("s.trim() = " + s.trim());
}
}
//如果事件对象是元素的结束
if (event.isEndElement()) {
EndElement end = event.asEndElement();
String titleName = end.getName().getLocalPart();
if (titleName.equals("title")) {
titleFlag = false;
}
}
}
eventReader.close();
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (XMLStreamException e) {
e.printStackTrace();
}
}
3、JSON简介及解析
-
JavaScript Object Notation,js对象表示法
-
一种轻量级的数据交换格式
-
,名称-值对。如"firstName":“John”
- json对象:{“name”:“John”,“email”:“a@b.com”}
- 数据在键值对中
- 数据由逗号分隔
- 花括号保存对象
-
,json数组
- 方括号保存数组
- [{K:V,K:V,K:V,…},{}]
- 方括号保存数组
- org.json:JSON官方推荐的解析类
- 简单易用,通用性强,但无法完成复杂功能
- GSON:Google出品。基于反射,可以实现JSON对象、JSON字符串和Java对象互转
- Jackson:号称最快的JSON处理器
- JSON生成
- JSON解析
- JSON校验
- 和对象进行互解析
- 具有一个无参的构造函数
- 可以包括多个属性,所有属性都是private
- 每个属性都有相应的Getter/Settrt方法
- Java Bean用于封装数据,又可称为POJO(Plain Old Java Object)
eg:
Person.java Java Bean类
public class Person {
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public List<Integer> getScores() {
return scores;
}
public void setScores(List<Integer> scores) {
this.scores = scores;
}
private String name;
private int age;
private List<Integer> scores;
public Person() {
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
}
books.json
{
"books": [
{
"category": "COOKING",
"title": "Everyday Italian",
"author": "Giada De Laurentiis",
"year": "2005",
"price": 30.00
},
{
"category": "CHILDREN",
"title": "Harry Potter",
"author": "J K. Rowling",
"year": "2005",
"price": 29.99
},
{
"category": "WEB",
"title": "Learning XML",
"author": "Erik T. Ray",
"year": "2003",
"price": 39.95
}
]
}
org.json:
//写JSON文件
public static void testJsonObject() {
//构造对象
Person p = new Person();
p.setName("Tom");
p.setAge(20);
p.setScores(Arrays.asList(60,70,80));
//构造JSONObject对象
JSONObject obj = new JSONObject();
//string
obj.put("name", p.getName());
//int
obj.put("age", p.getAge());
//array
obj.put("scores", p.getScores());
//null
//object.put("null", null);
System.out.println(obj);
System.out.println("name: " + obj.getString("name"));
System.out.println("age: " + obj.getInt("age"));
System.out.println("scores: " + obj.getJSONArray("scores"));
}
//读JSON文件
public static void testJsonFile() {
File file = new File("books.json");
try (FileReader reader = new FileReader(file)) {
//读取文件内容到JsonObject对象中
int fileLen = (int) file.length();
char[] chars = new char[fileLen];
reader.read(chars);
String s = String.valueOf(chars);
JSONObject jsonObject = new JSONObject(s);
//开始解析JSONObject对象
JSONArray books = jsonObject.getJSONArray("books");
List<ArrayList> bookList = new ArrayList<>();
for (Object book : books) {
//获取单个JSONObject对象
JSONObject bookObject = (JSONObject) book;
ArrayList book1=new ArrayList();
book1.add(bookObject.getString("author"));
book1.add(bookObject.getString("year"));
book1.add(bookObject.getString("title"));
book1.add(bookObject.getInt("price"));
book1.add(bookObject.getString("category"));
bookList.add(book1);
}
for (ArrayList book : bookList) {
System.out.println(book.get(0)+","+book.get(2));
}
} catch (Exception e) {
e.printStackTrace();
}
}
GSON:
public static void testJsonObject() {
//构造对象
Person p = new Person();
p.setName("Tom");
p.setAge(20);
p.setScores(Arrays.asList(60,70,80));
//从Java对象到JSON字符串
Gson gson = new Gson();
String s = gson.toJson(p);
System.out.println(s); //{"name":"Tom","age":20,"scores":[60,70,80]}
//从JSON字符串到Java对象
Person p2 = gson.fromJson(s, Person.class);
System.out.println(p2.getName()); //Tom
System.out.println(p2.getAge()); //20
System.out.println(p2.getScores());//[60, 70, 80]
//调用GSON的JsonObject
JsonObject json = gson.toJsonTree(p).getAsJsonObject(); //将整个json解析为一颗树
System.out.println(json.get("name")); //"Tom"
System.out.println(json.get("age")); //20
System.out.println(json.get("scores"));//[60,70,80]
}
public static void testJsonFile() {
Gson gson = new Gson();
File file = new File("books2.json");
try (FileReader reader = new FileReader(file)) {
//从JSON字符串到Java对象
List<Book> books = gson.fromJson(reader, new TypeToken<List<Book>>(){
}.getType());
} catch (Exception e) {
e.printStackTrace();
}
}
- 都是数据交换格式,可读性强,可扩展性高
- 大部分的情况下,JSON更具优势(编码简单,转换方便),而且JSON字符长度一般小于XML,传输效率更高
- XML更加注重标签和顺序,JSON会丢失信息
4、图形图像及解析
- 图形:Graph
- 矢量图,根据几何特性来画的,比如点、直线、弧线等
- 图像:Image
- 由像素点组成
- 格式:jpg,png,bmp,gif,svg,wmf,tiff等
- 图形:Graph
- java.awt包
- Java 2D库:Graphics2D,Line2D,Rectangle2D,Ellipse2D,Arc2D(弧形)
- Color,Stroke(线条)
- 图像
- java.imageio包
- ImageIO,BufferedImage,ImageReader,ImageWriter
- Java原生支持jpg,png,bmg,gif,wbmp
- javax.imageio.ImageIO
- 自动封装多种ImageReader和ImageWriter,读写图像文件
- read读取图片,write写图片
- java.awt.image.BufferedImage,图像在内存中的表示类
- getHeight 获取高度
- getWidth 获取宽度
eg:
readAndWriteImage:
public static void readAndWrite() throws Exception {
BufferedImage image = ImageIO.read(new File("c:/temp/ecnu.jpg"));
System.out.println("Height: " + image.getHeight()); // 高度像素
System.out.println("Width: " + image.getWidth()); // 宽度像素
ImageIO.write(image, "png", new File("c:/temp/ecnu.png"));
}
在已知图像格式,选定了该格式的reader,加载速度更快
// 指定用jpg Reader来加载,速度会加快
Iterator<ImageReader> readers = ImageIO.getImageReadersByFormatName("jpg");
ImageReader reader = (ImageReader) readers.next();
System.out.println(reader.getClass().getName());
ImageInputStream iis = ImageIO.createImageInputStream(new File("c:/temp/ecnu.jpg"));
reader.setInput(iis, true);
System.out.println("Height:" + reader.getHeight(0));
System.out.println("Width:" + reader.getWidth(0));
裁剪图片
/** * cropImage 将原始图片文件切割一个矩形,并输出到目标图片文件 * @param fromPath 原始图片 * @param toPath 目标图片 * @param x 坐标起点x * @param y 坐标起点y * @param width 矩形宽度 * @param height 矩形高度 * @param readImageFormat 原始文件格式 * @param writeImageFormat 目标文件格式 * @throws Exception */
public static void cropImage(String fromPath, String toPath, int x, int y, int width, int height, String readImageFormat,
String writeImageFormat) throws Exception {
FileInputStream fis = null;
ImageInputStream iis = null;
try {
// 读取原始图片文件
fis = new FileInputStream(fromPath);
Iterator<ImageReader> it = ImageIO.getImageReadersByFormatName(readImageFormat);
ImageReader reader = it.next();
iis = ImageIO.createImageInputStream(fis);
reader.setInput(iis, true);
// 定义一个矩形 并放入切割参数中
ImageReadParam param = reader.getDefaultReadParam();
Rectangle rect = new Rectangle(x, y, width, height);
param.setSourceRegion(rect);
//从源文件读取一个矩形大小的图像
BufferedImage bi = reader.read(0, param);
//写入到目标文件
ImageIO.write(bi, writeImageFormat, new File(toPath));
} finally {
fis.close();
iis.close();
}
}
拼接图片
/** * 横向拼接两张图片,并写入到目标文件 * 拼接的本质,就是申请一个大的新空间,然后将原始的图片像素点拷贝到新空间,最后保存 * @param firstPath 第一张图片的路径 * @param secondPath 第二张图片的路径 * @param imageFormat 拼接生成图片的格式 * @param toPath 目标图片的路径 */ public static void combineImagesHorizontally(String firstPath 标签:pds压力变送器原理pds矩形电连接器3051dp2a差压变送器