B 站址:2-4讲 DNA 染色体 DNA复制
分子生物学-朱玉贤第四版笔记-目录
- 1. DNA 和染色体
-
- 1.1. DNA 的化学组成
- 1.2. DNA 表示方法
- 1.3. 真核生物染色体 DNA 序列的特点
- 1.4. 基因组
- 1.5. DNA 结构在真核细胞中
- 1.6. 染色体 chromosome
- 1.7. 染色质和核小体
- 2. DNA 的复制 (DNA Replication)
-
- 2.1. DNA 复制的基本特征
- 2.2. DNA 聚合酶及复制系统
- 2.3. DNA 复制的基本过程
- 2.4. 原核生物 DNA 的复制
- 2.5. 真核生物 DNA 的复制
- 3. 基因组 DNA 序列的变异与修复
-
- 3.1. DNA 复制过程中的变异和修复
- 3.2. DNA 变异与修复
-
- 3.2.1 突变 mutation
- 3.2.2 E.coli DNA 修复系统
- 3.2.3 SNP
- 3.3. DNA 的转座 ★★★
-
- 3.3.1 转座的定义
- 3.3.2 转座模式
- 3.3.3 真核转座子
- 3.4. DNA 应用突变和转座
-
- 3.4.1 突变的应用
- 3.4.2 转座的应用
- 3.4.3 靶向基因编辑
1. DNA 和染色体
1.1. DNA 的化学组成
单核苷酸:-[磷酸酯键]--[糖苷键]-
- base:
- 嘌呤 (Adenine/Guanine):有氨基的二元环(-NH2);G 有氧
- 嘧啶 (Cytosine/Thymine/Uracil):一元环,C 只有一氧,有氨基;T 有甲基-CH3
- 核酸修饰:碱基上的被氧化
- ribose:
- 戊糖 2,3,5 位有羟基-OH,核糖核苷酸 2’是羟基,脱氧核糖核苷酸戊糖 二、无氧(脱氧) 羟基与磷酸形成磷酸酯键。
- DNA 合成方向:5→3’,DNA 链条生成是单核苷酸 5’-磷酸基团向核酸链 3’-OH 发起进攻。
- 磷酸 phosphate
1.2. DNA 表示方法
- 脱氧核苷酸的排列顺序称为 DNA 序列,又叫 DNA 一级结构(如 TCA, 默认方向是 5’→3’)
- DNA 分子大小表示:bp, 碱基 (base 或 kilobase) 数目。
- 生物细胞内 DNA 总量:C 值通常是指一种生物基因组 DNA 每个细胞中的皮克总量 (pg) 数表示。
1.3. 真核生物染色体 DNA 序列的特点
| / | 碱基组成 | 重复次数 | 占 DNA 总量 (%) | 基因类型 |
|---|---|---|---|---|
| 不重复序列 | 750-2000 | 1-几个 | 10-80% | 结构基因 |
| 中度重复序列 | 101-104 | 10-40% | rRNA, tRNA, 组蛋白基因 | |
| 高度重复序列 | 6-100 | 数百万次 | 10-60% | 卫星 DNA |
- (satellite DNA) : 又称随体 DNA。真核细胞 DNA 部分不转录成分,其组成和主体 DNA 因此,可用的密度梯度沉降平衡技术,如氯化锶梯度离心,将其与主体不同 DNA 分离。它通常是高度串联重复的 DNA。
- :DNA 不同的序列携带不同的遗传信息。
- 有些序列编码蛋白或 RNA,称为,不编码称为非功能 DNA(现在发现,)。不同生物的功能 DNA 不同比例的基因组。
- 是 DNA 上的一段编码某种链或 的顺序,还具有调节功能的顺序。编码多肽链和 RNA 的基因称为。
1.4. 基因组
指染色体中的完整性 DNA 序列。
- 基因组可以指整个核 DNA, 也可以用来包含自己 DNA 粒线体基因组或叶绿体基因组等序列细胞器基因组。 和细菌 DNA 类似地,能引起人体免疫反应。
- 基因组的大小:中所有 DNA 的长度。
- 基因数量:基因组中包含的基因数量。
- 基因密度:每 Mb 基因组 DNA 中所包含的平均基因的数量。
- :随着物种复杂度的增加,各种生物的基因总数增加,但基因密度增加 (density) 降低。
指 C 值(基因组的大小)往往与种系的进化复杂性不一致,即基因组的大小与遗传复杂性之间没有必然的联系(目前原因不明),一些较低的生物 C 但是值很大,比如一些两栖物种 C 甚至比哺乳动物还大。
- 真核基因组,一般远大于原核生物的基因组。
- 有大量的真核基因组。。
- 真核基因组 (>90%)是真核生物与细菌与病毒最重要的区别。
- 真核基因组的转录产物是(编码一个基因片段)。原核生物是多顺反子(一个 mRNA 多肽链的分子编码)。
- 真核基因是,含子结构。
- 有大量的真核基因组。(启动子、增强子、沉默子)。
- 真核基因组中有大量的真核基因 :单核苷酸多态性和串联重复序列多态性。
- 有真核基因组 (telomere) 结构。保护线性 DNA 的完整复制、保护染色体末端和决细胞的寿命等功能。
- 域只占人类基因组非常小的部分():30 亿对碱基,个蛋白质基因。基因数目是果蝇的 2 倍,啤酒酵母的 4 倍。
- 其它 的基因:人类基因组绝大部分都(非编码 RNA, ncRNA), 细胞内 ncRNA 的数量是编码 RNA 的上百倍。
- 中约有 24% 为插入编码序列的序列:人类基因。
- 不由编码蛋白质的数目决定,而是被隐藏在它们所输出的 内。
- : 人和黑猩猩的基因差别为 1‰, 来源于非编码 RNA 。 人和鼠的蛋白质编码基因 99%是共同的。 人个体间单倍体基因组的碱基差异 300 万个,其中 出现在中,绝大多数存在于非编码 RNA。
- :rRNAs and tRNAs
- :snRNA 识别剪接位点
- :snoRNA 将尿苷(uridine)修饰变成假尿苷 (pseudo-uridine)
- :miRNAs
- : 作为合成端粒重复序列的模板
1.5. DNA 在真核细胞中的结构
DNA double helix
- DNA 是由两条互相平行的脱氧核苷酸长链盘绕而成的。
- DNA 分子中的交替连接,排在,构成基本骨架,排列在。
- 两条链上的碱基通过氢键相结合,形成碱基对。
- 在 DNA 分子中,嘌呤永远与密啶配对
- 腺嘌呤(A)= 胸腺喀啶(T)
- 鸟嘌呤(G)≡ 胞啶(C)
-
真核生物 DNA 以双螺旋的形式存在 三种结构, 是最常见的 DNA 构象
-
- B-DNA: A-T 丰富的 DNA 片段
- A-DNA(对基因表达有重要意义)
- DNA-RNA(处于转录状态的 DNA)
- RNA-RNA (dsRNA)
-
- Z-DNA 结构:1977 年 Rich 等人用人工合成的 六核酸进行 X-射线晶体衍射分析,观察到一种特殊的左手双螺旋结构,骨架走向呈,称 Z-DNA。
| / | A | B | Z |
|---|---|---|---|
| 外型 | 粗短 | 适中 | 细长 |
| 螺旋方向 | 右手 | 右手 | 左手 |
| 螺旋直径 | 2.55nm | 2.37nm | 1.84nm |
| 碱基直升 | 0.23nm | 0.34nm | 0.38nm |
| 每圈碱基数 | 11 | 10 | 12 |
| 碱基倾角 | 20° | 0° | 7° |
| 大沟 | 很窄很深 | 很宽较深 | 平坦 |
| 小沟 | 很宽、浅 | 窄、深 | 较窄很深 |
- 会形成 DNA 结构 或 DNA 结构
DNA 的三螺旋结构(H-DNA)
- 三链结构:在 Waston-Crick 双碱基配对基础上,加入第三条链配对,形成 +(两个氢键)或 的三螺旋结构。
- DNA 三股螺旋结构(H 型-DNA) DNA 复制、转录、重组的起始位点或调节位点,如。
- 第三股链的存在可能使一些,从而阻遏有关遗传信息的表达。
DNA 的四螺旋结构
- 真核生物 DNA 3’-末端()是,因而自身形成了折叠的四链结构。
DNA 超螺旋结构(superhelix 或 supercoil)
- :盘绕方向与双螺旋方向相同
- :盘绕方向与双螺旋方向相反
- :
- 使 DNA 形成高度致密状态从而得以装中;
- 推动 DNA 结构的转化以满足上的。如负超螺旋分子所受张力会引起互补链分开导致局部变性,利于。
- 研究 时发现,天然状态下该 DNA 以为主,稍被破坏即出现结构,两条链均断开则。在电场作用下,相同分子质量的 超螺旋 DNA 迁移率 > 线性 DNA 迁移率 > 开环的 DNA 迁移率,以此可。
hematoxylin-eosin staining
- 石蜡切片技术里常用的染色法之一。
- 苏木精染液为碱性,主要使细胞核内的与胞质内的着;
- 伊红为酸性染料,主要使细胞质和细胞外中的成分着。
1.6. 染色体 chromosome
-
:在细胞周期的大部分时间里,DNA 以松散的染色质 (chromatin) 形式存在,在细胞分裂期,则形成高度致密的染色体 (chromosome)。
-
- 原核细胞中:DNA 存在于称为拟核 (nucleoid) 的结构区。每个原核细胞一般只有一个染色体,每个染色体含一个双链环状 DNA。
- 真核细胞中:DNA 主要集中在细胞核内,线粒体和叶绿体中均有各自的 DNA。
-
:
- 分子结构相对;
- 能够,使亲子代之间保持连续性;
- 能够指导蛋白质的合成,从而控制整个生命过程;
- 能够产生可遗传的变异。
-
- DNA
- RNA:尚未完成转录而仍与模板 DNA 相连接的;ncRNA 参与中心粒的形成等功能。
- :8 聚体结构。
- 非组蛋白
-
与 DNA 组成染色质(chromatin)的最小单位核小体 (nucleosome)。
-
有 H1、H2A、H2B、H3 及 H4 五种,是染色体的结构蛋白。
-
,位于染色质处;组蛋白进化上极端保守,位于染色质区。
-
。
-
:分布在 ;在 。
-
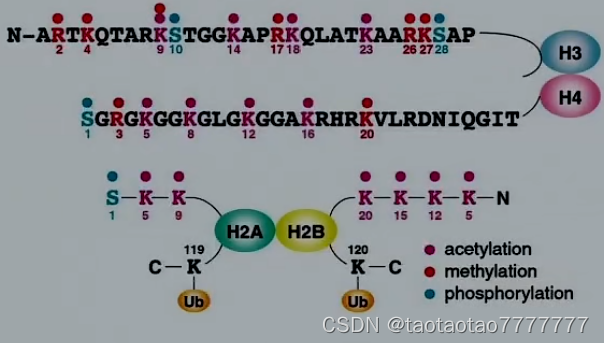
存在较普遍的作用:甲基化、乙酰化、磷酸化、泛素化等。组蛋白 N 端尾巴的主要在 (lys 赖氨酸)和 (Arg 精氨酸)(,带正电) 上。(丝氨酸 Ser,带羟基)会发生。
 - (负电):(天冬氨酸 Asp)、(谷氨酸 Glu) - 20 种氨基酸缩写
- (负电):(天冬氨酸 Asp)、(谷氨酸 Glu) - 20 种氨基酸缩写 -
- 的乙酰化(形成 50 种异构体);
- (H3, H4, H2B)的磷酸化;
- (H3 和 H4)的甲基化修饰;
- 其他修饰:如泛素化和 ADP-核糖基化。
- 四种核心组蛋白携带巨大的量。
- 组蛋白的甲基化修饰方式是的,发生在组蛋白的赖 氨酸和精氨酸残基上: 残基能够发生单、双、三甲基化; 残基能够单、双甲基化,这些不同程度的甲基化极大地增加了组蛋白修饰和调节基因表达的复杂性。
- 由 (histonemethyl transferase, ) 完成。
- 组蛋白的甲基化与和与相关。
- 等调控的位置容易发生修饰。
Histone acetyltransferase () / Histone deacetylase complexes ()
- :加入 CH3-CO-或 Ac-
- HAT/HDAC 催化 H3、H4 特定 残基的乙酰化/去乙酰化修饰,实现乙酰化水平的动态平衡;
- 特定基因部位的组蛋白乙酰化和去乙酰化是以一种非随机的、位置特异的方式进行;
- 乙酰化/去乙酰化修饰和;
- :转录;:转录。
- 转录激活、转录延伸
- DNA 修复、拼接、复制
- 染色体的组装
- 基因沉默
- 某些疾病的形成
- 细胞的信号转导
- 基因组的整体乙酰化
-
磷酸化、腺苷酸化、泛素化、ADP 核糖基化等。
-
各种修饰间也存在着相互的关联。
-
多种修饰方式的组合更为灵活的调控响染色质的结构与功能。这些能被专识别的修饰信息被称为。
-
:
- :加入 (ubiquitin) 蛋白,调控,调控。
- 泛素蛋白连接酶 / 去泛素化酶 Histone ubiquitinase/ deubiquitinase 负责组蛋白 H2A 和 H2B 的。
- 通过,改变组蛋白与 DNA 的相互作用,从而改变染色质的疏松或凝集状态;
- 通过来发挥基因调控作用。
- 调节 DNA 包装和染色质,进而调节基因的表达。
- 组蛋白修饰是的携带者,决定了基因的表达方式是怎样在一代细胞和下一代细胞之间保持的(部分保留)。
- 在肿瘤、免疫、心血管等的发生及其防治中具有十分深远的意义。
- 非组蛋白约为组蛋白总量的 60% - 70%,可能有 20 - 100 种(常见的有 15 - 20 种)
- 主要包括酶类 (RNA 聚合酶)、与细胞分裂有关的蛋白。
- 也可能是染色质的结构部分。
- (High mobility group protein), DNA 结合蛋白,能与 DNA 结合但不牢固,也能与 H1 作用;可能与 DNA 的超螺旋结构有关。相对分子量较低,占非组蛋白的 20%,染色质的 8%; 可能与 DNA 的复制、转录、修复和重组有关。
1.7. 染色质和核小体
- 由 DNA 和组蛋白组成的染色质纤维细丝,是许多核小体连成的念珠状结构。
- 是染色质的基本结构单位,由 200bp DNA 和组蛋白八聚体组成。
- 146bp DNA +组蛋白八聚体 (Histone octamer)→核小体核心 ()+ H1→染色小体 (Chromatosome, 166bp) + linker DNA→核小体 (Nucleosome, ~200 bp of DNA)
:
- 染色质 DNA 的 比自由 DNA ,说明在染色质中 DNA 极可能与蛋白质分子相互作用。
- 在染色质状态下,由 DNA 聚合酶和 RNA 的 DNA 大大于在自由 DNA 中的反应。
- (DNaseI) 对染色质 DNA 的远远于对纯 DNA 的作用。
- 用处理染色质以后进行电泳,便可以得到一系列片段,这些被保留的 均为 基本单位的倍数。
(1) 组蛋白 H1 与核小体之间的接头 DNA 结合,诱导更紧密的 DNA 包裹在核小体周围;(H1 的加入导致形成更紧凑的核小体 DNA) (2) 核小体阵列可以形成更复杂的结构: (zigzag model)。
- 30nm 染色质纤维是由“”为结构单元的结构。
- 30nm 纤维具有 6 个核小体/转,组织成螺线管。
- 组蛋白 和组蛋白 是形成 30nm 纤维所必需的。
- 这种纤维是和的基本成分。
(3) DNA 的进一步压缩形成大的
原核生物基因组的特点
- 原核生物的基因组很小,大多只有,且 DNA 含量少。如大肠杆菌 DNA 的相对分子质量仅为 4.6X106bp, 其完全伸展总长约为 1.3mm, 含 4000 多个基因。
- 原核生物基因主要是,只有很少数基因(如 rRNA 基因)以多拷贝形式存在;
- 整个染色体 DNA 所组成;
- 几乎每个基因序列都与它所编码的蛋白质序列呈对应状态。
原核细胞 DNA 的特点
- :原核 DNA 分子的绝大部分是用来编码蛋白质的,只有很小一部分控制基因表达的序列不转录。这些不转录 DNA 序列通常是控制基因表达的序列。
- :原核生物 DNA 序列中功能相关的 RNA 和蛋白质基因,往往从集在基因组的一个或几个特定部位,形成转录单元,并转录产生含多个 mRNA 的分子,称为。
- :一些细菌和动物病毒存在重叠基因,。
- 细胞外:
- EMSA 凝胶阻滞实验(电泳)
- 足迹实验
- 甲基化干扰试验
- ChIP-seq
- 酵母单杂交技术
- 核酸适配体
- 双偏振干涉技术
- 细胞内:活细胞成像技术(荧光)
2. DNA 的复制 (DNA Replication)
2.1. DNA 复制的基本特点
-
- :,不同颗拉之间存在沉降系数差时,在一定离心力作用下,颗粒各自以一定速度沉降,在密度梯度不同区域上形成区带的方法。
-
- :有特殊的复制起点,不同生物具有不同的复制起点数目和复制子数目
- :一般把生物的复制单位称为
复制子 (replicon),一个复制子只含有一个复制起点。 - 的 DNA 分子都是作为完成复制的。
- 包含,可以同时在多个复制起点上进行复制。
- 复制叉:DNA 分子的解链看起来像一个向一个方向生长的叉子 (fork)
- 复制泡:被复制的区域看起来像气泡
-
- (1963,John Cairns) 将细菌培养在 3H 标记的培养基中,等细胞进入复制中期,温柔地裂解细胞,将细胞裂解液涂在电镜网格上将样品长时间( 2 个月)曝光到 X 胶片。 :大肠杆菌有环形染色质;大肠杆菌有单一的复制起始点;在大肠杆菌中复制和解链是同时发生的。
- (Bidirectional Replication) 无论是原核生物还是真核生物,DNA 的复制主要是方式进行。 复制叉以 DNA 分子上某一特定顺序为起点,向两个方向等速生长前进。
-
- DNA 双螺旋的两条链是反向平行的,因此两个模板的极性不同。 所有已知 DNA 聚合酶的:DNA 的合成方向是从 5’到 3’。
- (semi-discontinous replication) (等速复制)
- 用 3短时间标记后提取 DNA, 得到不少平均长度为 2-3kb DNA 片段。
- 用 进行实验,在的温度下,有大量小片段累积,复制过程中至少有一条链首先合成较短的片段,然后再生成大分子 DNA。
前导链的连续复制和滞后链的不连续复制,称为 。短的半不连续片段被称为冈崎片段。细菌中大约 1000-2000 nt 长,真核生物中人约 200 nt 长。
2.2. DNA 聚合酶以及复制体系
-
:
- dNTPs: dATP, dTTP, dGTP, dCTP (脱氧三磷酸核苷)
- 亲代 DNA template
- DNA polymerase (Kornberg enzyme)
- Mg2+ (optimizes DNA polymerase activity)
-
DNA 合成反应的主要特点
- 催化脱氧核糖的 3’-OH(在最后一个核首酸上)和 dNTP 的 5’-磷酸之间形成磷酸二酯键。
- 该反应的能量来自 dNTP 的三个磷酸基团中两个磷酸的释放。
- DNA 聚合酶在延长过程的每个步骤“找到”正确的互补 dNTP。
- 速率 ≤800 dNTPs/秒;错误率低
- 合成方向是 5’到 3’
2.3. DNA 复制的基本过程
:在复制的起始原点处形成复制叉,复制叉能移动。
- 复制时,双链 DNA 在酶的作用下解链为两股单链分别进行,复制起点呈叉子形状,被称为
复制叉 (Replication fork) -
DNA 解旋酶 (DNA helicase):催化 DNA 双链的过程。单链 DNA 结合蛋白(single strand DNA binding protein, ): 以四聚体形式存在于复制叉处,只,并不能起解链作用。DNA 拓扑异构酶 (DNA topoisomerase): DNA 双链的堆积。引物酶 (primase):是一种 RNA 聚合酶,能作为 DNA 复制的引物。引物是一个短序列(通常是 RNA),它与一条 DNA 链配对,并为 DNA 新链的合成提供 3’-OH 末端()。
- DNA 聚合酶的共同点:
- 都以脱氧三磷酸核苷 dNTP 为底物
- 都需要 Mg2+ 激活
- 聚合时都必须有模板链和具有 3’-OH 末端的引物链
- 链的延伸方向为 5’到 3
- :DNA 聚合酶只能延长依存在的 DNA 链,不能从头合成 DNA 链,需要 3’-OH 末端起始复制。
- :只能加到已经存在的 DNA 或者 RNA 链的 3’端。
- 先导链:连续合成
- 滞后链:先合成冈崎片段,再通过 连接起来。
DNA polymerase Ⅰ具有 5’-3’外切酶活性,3’-5’合成活性。去除 RNA 引物并替换为 DNA 核苷酸(去除的末端由端粒酶合成)。合成速度 20bases/秒,主要作用是切除引物(移去不正常碱基)、编辑校对&改正错误碱基、修复错配碱基。DNA polymerase Ⅲ合成速度 1000bases/秒(速度快=lots of typos 错误多),主要作用是合成 DNA。- :
- DNA 聚合酶
滑动夹 (Sliding DNA clamp):滑动夹由相关 DNA 聚合酶产生的新复制的 DNA,能显著提高 DNA 的持续合成能力。- (RNase H 等 ):在复制完成后切除 RNA 引物。
- (DNA ligase):通过生成 3’5’-磷酸二酯键连接两条 DNA 链。
- :
- 移除几乎所有的 RNA 引物,。
- 去除最后的核苷酸。
- 填补空隙,剩下一个 3’羟基和 5’磷酸基团之间的缺口。
- 修复缺口。
Ter-Tus 终止复合物参与复制的终止:当复制叉迁移遇到 时,Ter-Tus 终止复合物阻止复制叉的迁移。等到相反方向的复制叉到达后在 的作用下,释放子链 DNA。- :
Ⅱ型拓扑异构酶用来分离子代 DNA 分子;对于,Ⅰ型拓扑异构酶催化其中一个子分子的断裂并允许第二个子分子通过断裂。
2.4. 原核生物 DNA 的复制
-
- 有。复制叉的移动速度约 50bp/s, 人类 DNA 中每隔 30000-300000 就有一个复制起始位点。
- 在全部完成复制之前,各个起始点上 DNA 的复制不能再开始。
- DNA 的复制只在 进行。
- 复制子相对较小,为 40-100k bp。
-
- 细菌染色体的复制是作为一个单位从的复制起点开始,双向进行的。
- 大肠杆菌 (E. Coli) 的 oriC 的复制原点:大肠杆菌基因组的复制原点位于天冬酰胺合酶和 ATP 合酶操纵子之间,全长 245 bp, 称为
oriC。
-
(由大肠杆菌 oriC 复制起始点处引发的 DNA 复制过程)
- 大约 20 个
DnaA 蛋白在 ATP 的作用下与 oriC 处的 相结合。 - 在
Hu 蛋白和 ATP 的共同作用下,DnaA 复制起始复合物使 3x13 bp 直接重复序列变形,形成。 DnaB (解链酶)六体分别与单链 DNA 相结合(需要 DnaC 的帮助)进一步解开 DNA 双链。- , 起始 DNA 复制。
- 大约 20 个
-
- 大肠杆菌中主要有 DNA 聚合酶、Ⅳ 和 Ⅴ。
- DNA 聚合酶(coded by
polA) 不是复制大肠杆菌染色体的主要聚合酶:
- 有 3’→5’核酸外切酶活性,保证 DNA 复制的。
- 它的 5’→3’核酸外切酶活性可用来除去岗崎片段 5’端 RNA 引物,同时利用 5’→3’ DNA 合成活性。
- 还参与 DNA 损失的。
- DNA 聚合酶 (coded by
polB) 活性很低,只有 DNA 聚合酶的 5%,也不是复制中的主要酶。生理功能主要是,具有 3’→ 5’核酸外切酶活性。 - DNA 聚合酶(coded by
polC) 是大肠杆菌 DNA 复制中反应的:
- 聚合活性较强,DNA 聚合酶Ⅰ的 15 倍,聚合酶Ⅱ的 300 倍。
- 合成速度:5 万 nt/min。
- 包含 7 种不同的亚单位和 9 个亚基,以的形式发挥生物活性。
- 具有 3’→5’核酸外切酶活性。
-
- :大肠杆菌质粒 DNA 模式
- :属于特定环状 DNA 分子的复制方式(),环状 DNA 可以通过滚环式复制产生多单元单链 DNA,是 在细菌中最通常的一种复制方式;
- 滚环型复制过程:
- 环状双链 DNA 的+链被内切酶切开();
- 以-链为模板,DNA 聚合酶以+链的 3’端作为引物合成新的+链,原来的+链 DNA 分子的 5’端与-链分离;
- +链的 3’端继续延长;
- 引发酶以离开的+链为模板合成 RNA 引物,DNA 聚合酶以+链为模板合成新的-链;
- 通常滚环复制的产物是一多聚物,其中大量单位基因组头尾相连。
- 复制过程的特征:
- 复制是单方向不对称的;
- 产物是, 但可通过互补链的合成转变为双链;
- 子代 DNA 分子可能是共价连接的连环分子;
- 连环分子随后被切成与单个基因组相对应的片段。
- :复制的特殊方式
- 首先在动物中被发现。植物叶绿体基因组也是靠 D 环复制的。
- ,取代了该区域原来互补的 DNA 链,使得两条链的合成高度不对称,一条链上迅速合成出互补链,另一条链则为。
- 两条链的复制都是从两个独立的起点先后起始的;
- 复制的起始是由一条或两条(链)替代环促使的。
- 起始位点是包括的独特 DNA 片段;
- 专一性识别这些短的重复序列;
- 起始位点,能使 DNA 螺旋容易解开。
2.5. 真核生物 DNA 的复制
-
真核生物 DNA 的复制子称为 (, autonomously replicating sequence),长约 150bp,包括数个复制起始必需的。
-
真核生物 DNA 复制的起始需要 (origin recognition complex, ) 参与,ORC 由 6 种蛋白质组成,结合 ARS。
-
- 真核生物 DNA 聚合酶有 15 种以上,在哺乳动物细胞中主要有 DNA 聚合酶,分别称为 DNA 聚合酶 。
- DNA 聚合酶 主要参与。
- DNA 聚合酶 活性水平稳定,主要在 中起作用。
- DNA 聚合酶 主要负责 。
- DNA 聚合酶 与有关,在 DNA 合成过程中核苷切除以及碱基的切除修复中起着重要的作用。
- DNA 聚合酶 在中发挥作用。
- 真核生物中还存在 ζ、η、τ和κ 等几种 DNA 聚合酶,它们承担着的功能,但这些修复酶的忠实性都很低。
- δ 和 ε 具有 3’→5’外切酶活性。
真核生物 DNA 聚合酶的特性比较
| 性质 | α |
β | γ | δ |
ε |
|---|---|---|---|---|---|
| 亚基数 | 4 | 1 | 2 | 2-3 | ≥1 |
| 细胞内分布 | 核内 | 核内 | 线粒体 | 核内 | 核内(?) |
| 功能 | DNA 引物合成 |
损伤修复 | 线粒体 DNA 复制 | 主要 DNA 复制酶 |
DNA 复制(?) |
| 3’→5’外切 | 无 | 无 | 有 | 有 | 有 |
| 5’→3’外切 | 无 | 无 | 无 | 无 | 无 |
3. 基因组 DNA 序列的变异与修复
3.1. DNA 复制过程中的变异与修复
-
(Replication fidelity)
- 对于遗传信息从上一代精确传到下一代很重要。
- 在中 DNA 复制的错配率很低, (proofreading function) 保证了复制的精确性。
- 是指用于纠正蛋白质或核酸合成中的错误的任何机制,其涉及在将各个单元添加到链中之后对其进行详细检查。
- DNA 聚合酶含有 DNA (Polymerizing,E) 和 (proofreading, P)两个不同的位点。
- :
- 当在 DNA 合成期间掺入不正确的碱基时,聚合酶暂停,然后将生长链的 3’末端转移至核酸外切酶位点来去除错误碱基。然后 3’端翻转回聚合酶位点,正确复制该区域。
- 大肠杆菌 DNA 聚合酶具有 3’→5’核酸外切酶活性,因此具有校对活性。
- 在动物细胞中,δ和ε DNA 聚合酶,而不是聚合酶 α, 都具有校对活性。
-
:因为 DNA 聚合酶只能添加到现有 DNA 链的 3’端,所以在去除 RNA 引物后 DNA 聚合酶/连接酶不能填充染色体末端的缺口。如果这个差距没有填补,每轮复制后染色体会变短!
- solution:
- 真核生物在其染色体末端有连续重复非编码序列()(保护帽,细胞分裂限制在 50 次以内)。
- () 与末端端粒重复序列结合并。
- 通过延长染色体来补偿。
- 端粒酶活性的缺失或突变导致染色体缩短和有限的细胞分裂。
- 是人所有染色体末端的重复 DNA 序列
- 它们包含数千个六核苷酸序列
TTAGGG的重复序列 - 在人类中有 46 条染色体,因此有 92 个端粒(每端一个)
- 人类中一条链上重复的富含 G 的序列:(TTAGGG)n
- 重复可以长达数千个碱基对。在人类中,端粒重复平均为 5-15kbp
- ,例如 和 , 结合重复序列并。没有这些蛋白质,端粒受到 DNA 修复途径的作用,导致。
- :
- 保护染色体。
- 将一条染色体与另一条染色体分开。
- 没有端粒,染色体的末端将被“修复”,导致染色体融合和大量的基因组不稳定性。
- 端粒也被认为是调节单个细胞分裂次数的“时钟”。每次 DNA 复制时,端粒序列都会缩短。
- 由与端粒重复序列互补的 RNA 和蛋白质组成
- 端粒酶:端粒酶具有逆转录酶活性,其中的 RNA 与端粒配对,合成端粒 DNA。
- 人端粒酶的两个组成部分:
- 人 RNA 亚基 ()
- 人端粒酶逆转录酶 ()
- :
- 专门的逆转录酶
- 通过添加端粒来防止“缩短末端问题”
- 仅复制其自身携带的一小部分 RNA
- 需要 3’末端作为引物
- 合成以 5’→3’方向进行
- 合成一个重复然后重新定位自己
- 活跃时提供细胞永生
- 端粒酶通过将端粒 DNA 添加到染色体末端起作用,从而补偿通常在细胞分裂时发生的端粒丢失。
- 身体的大多数细胞含有端粒酶,但它,因此细胞在每次分裂时失去端粒并最终死亡。
- 在人类中,端粒酶在,绝大多数癌细胞以及可能的一些干细胞中具。
- 端粒酶与:来自数百个独立实验室的实验证据表明,端粒酶活性几乎存在于所有人类肿瘤中,但不存在于肿瘤附近的组织中因此,临床端粒酶研究目前专注于开发准确诊断癌症的方法和新型抗端粒酶癌症治疗方法。
- 端粒酶与:癌细胞不会衰老,因为它们会产生端粒酶,从而保持端粒的完整性。许多实验表明,端粒与衰老之间存在直接关系,端粒酶具有延长寿命和细胞分裂的能力。
3.2. DNA 变异与修复
3.2.1 突变 mutation
突变:DNA 碱基序列的永久性、可遗传的改变。
导致突变的原因
- 自发性的:未知原因;可能是一个致病因素,但尚未确定;在噬菌体和细菌中以相对恒定的速率进行:每代每个基因组 3-4×10-3。
- 诱导的:物理或化学试剂、尼古丁、紫外光、药物、电离辐射等。
-
- : Purine 嘌呤 or pyrimidine 嘧啶 is replaced by the other. or
- : a purine is replaced by a pyrimidine or vice verse. 嘌呤被嘧啶取代,反之亦然。 or
- :TGT→TGC Cys→Cys 氨基酸不发生改变
- :TGT→TGG Cys→Trp 氨基酸发生改变
- :TGT→ Cys→ 变成终止子
-
- :The elimination or addition of one or more nucleotides in a DNA region. It may cause frameshift (移码突变) producing a non-functional protein.
3.2.2 E.coli DNA 修复系统
-
mismatch repair:修复错配。根据原则找出错配碱基,MutS-MutL 与碱基错配位点的 DNA 双链结合移动,发现甲基化 DNA 后由 MutH 切开。
当错配碱基位于时,在 MutL-MutS、解链酶Ⅱ 、DNA 外切酶Ⅵ 或 RecJ 核酸酶的作用下,从错配碱基 3’下游端开始切除单链 DNA 直到原切口,并在 Pol Ⅲ和 SSB 的作用下合成新的子链片段; 若错配碱基位于,则在 DNA 外切酶Ⅰ或 Ⅹ 的作用下,从错配碱基 5’上游端开始切除单链 DNA 直到原切口,再合成新的子链片段。
-
(碱基、核苷酸切除修复):Base-excision repair / nucleotide-excision repair 切除突变的碱基和核苷酸片段。
DNA 分子中常见的核苷酸非酶促转变反应:(a) 基反应(嘌呤上的氨基被);(b) 反应 (N-β-糖苷键被水解)。
在中受损伤核苷酸3’端的第 位,5’端的第 位磷酸糖苷键分别被 DNA 切割酶切开。 在中,受损伤核苷酸3’端第 位,5’端的第 位磷酸糖苷键分别被 DNA 切割酶切开。
-
recombinant repair:复制后的修复,重新启动停滞的复制叉。
-
direct repair:修复嘧啶二体或甲基化 DNA。
-
: 细胞 DNA 受到损伤或复制系统受到抑制时,细胞为求生存而“生的一种应急措施。诱导 DNA 损伤修复、诱变效应、细胞分裂的抑制以及溶原性细菌释放噬菌体等,导致变异。
3.2.3 SNP
- (, Single Nucleotide Polymorphism) 指基因组 DNA 序列中由于(A,T,C 和 G)而引起的多态性。
- SNP 是基因组中的多态性形式,具有。
- SNP 检测和分析技术成为。
- 一个 SNP 表示在基因组某个位点上一个核苷酸的变化:
- (C↔T,在其互补链上则为 G↔A) 占 SNP 总量的 。嘧啶↔嘧啶,嘌呤↔嘌呤
- (C↔A/G,T↔A/G) 嘧啶↔嘌呤
- SNP 广泛存在于人类基因组中,其发生频率约为 或更高。一个人类个体大约携带 个 SNPs。
根据 SNP 在基因组中的可分为三类: (1) (synonymous cSNP) 即 SNP 所导致的编码序列改变并其所翻译的蛋白质的氨基酸序列,突变碱基与未突变碱基的含义相同; (2) (non-synonymous cSNP) 指碱基序列的改变可使以其为蓝本翻译的蛋白质序列发生,从而影响了蛋白质的功能。是导致生物性状改变的直接原因。 影响基因的多少
最常见的是通过 DNA 测序法获得新的 SNP。 是指利用数据库中已有的 SNP 进行特定人群的序列和发生频率的研究: · 基因芯片技术 . Taqman 技术 · 分子信标(molecular beacons)技术 · 焦磷酸测序法( pyrosequencing)
- 已有超过 个 SNP 被精确定位于各染色体上。将为我们精确定位复杂疾病,如糖尿病,癌症,心脏病,中风,哮喘等易感基因提供重要信息。
- SNP 作为新一代遗传标记在人类疾病研究中显示出极高的潜在价值。已经发现了高血压、哮喘、类风湿关节炎、肺癌、前列腺癌等许多易感基因。
- 通过研究 SNP 与个体对药物敏感或耐受的相关性研究,可能阐明遗传因素对药效的影响,因此可能建立与基因型相关的治疗方案,对病人施行个性化用药。另外,随着 SNP 的研究与药物基因组学的结合,根据特定的基因型来设计药物将成为可能。
3.3. DNA 的转座 ★★★
3.3.1 转座的定义
- DNA 的,或称 (),是由 (transposable element)介导的 遗传物质 现象。
- () 是存在于染色体 DNA 上的基本单位。
3.3.2 转座模式
-
根据转座子 一般分为 插入序列(IS) 和复合型转座子两类;
- 在转座子的有两个反向重复序列(),在靶 DNA 有两个短的正向重复序列()。
- 的各有一个 (IS 不能单独移动,带或者一起转座),每个 IS 序列两侧各有。
- :
转座子组成 功能 转座酶 Transposase 随机剪切目标 DNA 并将转座子末端拼接到目标序列上。转座的其他步骤由宿主酶完成。 Inverted Repeats, IR这些序列直接作用于转座子的末端。注意,由于序列是倒置的,两端序列相同。 筛选标记 Selectable Markers 转座子被认为是通过而进化的。许多转座子携带给宿主带来抗生素耐药性 (antibiotic resistance) 或其他益处的基因。
- :
-
根据转座子 分为 (转座后原序列) 和 (转座后原序列)两大类。