Java 分布式框架面试题集合
1.什么是 ZooKeeper?
答:ZooKeeper 它是一种开源的分布式应用程序协调服务,是一种典型的分布式数据一致性解决方案。设计的目的是包装复杂且容易出错的分布式一致性服务,形成一个高效可靠的系统,并为用户提供一系列简单易用的原子操作。
2.ZooKeeper 提供了哪些功能?
答:ZooKeeper 主要提供以下功能:
- 分布式服务注册和订阅:在分布式环境中,为了确保高可用性,同一应用程序或同一服务的提供商通常会部署多份,以实现平等服务。消费者必须选择一个平等的服务器来执行相关的业务逻辑,更典型的服务注册和订阅,如 Dubbo。
- 分布式配置中心:发布和订阅模型,即所谓的配置中心,顾名思义,发布者将数据发布到 ZooKeeper 在节点上,订阅者可以获取数据,集中管理和动态更新配置信息。
- 命名服务:在分布式系统中,命名服务客户端应用程序可以根据指定名称获取资源、服务地址和提供商。
- 这主要是由于分布式锁: ZooKeeper 确保数据的强一致性。
3.ZooKeeper 有多少种建筑模式?
答:ZooKeeper 通常有三种建筑模式:
- 单机模式:zoo.cfg 中只配置一个 server.id 这是一种单机模式,通常用于测试环境。如果当前主机停机,则取决于当前 ZooKeeper 其他服务器不能正常工作;
- 伪分布式模式在机器上启动不同端口 ZooKeeper,配置到 zoo.cfg 与单机模式相同,该模式一般用于测试环境;
- 分布式模式:多台机器各自配置 zoo.cfg 这种完全分布式的文件将相互添加到服务器列表中。
4.ZooKeeper 有哪些特点?
答: ZooKeeper 特性如下:
- 顺序一致性(Sequential Consistency):同一客户端提交的事务,ZooKeeper 严格按照提交顺序执行;
- 原子性(Atomicity):于 ZooKeeper 集群中提交的事务将全部完成或全部未完成,无部分完成;
- 单系统镜像(Single System Image):连接到客户端 ZooKeeper 集群的任何节点获得相同的数据视图;
- 可靠性(Reliability):一旦事务完成,其状态变化将永久保留,直到其他事务被覆盖;
- 实时性(Timeliness):一旦事务完成,客户端将在有限的时间内获取最新数据。
5.以下关于 ZooKeeper 错误的描述是什么?
A:所有节点都有稳定的存储能力 B:ZooKeeper 任何节点都可以通信(消息发送) & 接收) C:为提高性能,ZooKeeper 允许一部分节点在同一数据中成功写作,另一部分节点写作失败 D:ZooKeeper 只要超过一半的节点在集群运行期间存活,ZooKeeper 能正常服务 答:C 题目解析:ZooKeeper 一部分节点写成功,另一部分节点写失败,不允许同一数据,这与 ZooKeeper一致性原则。
6.ZooKeeper 如何实现分布式锁?
答:ZooKeeper 实现分布式锁的步骤如下:
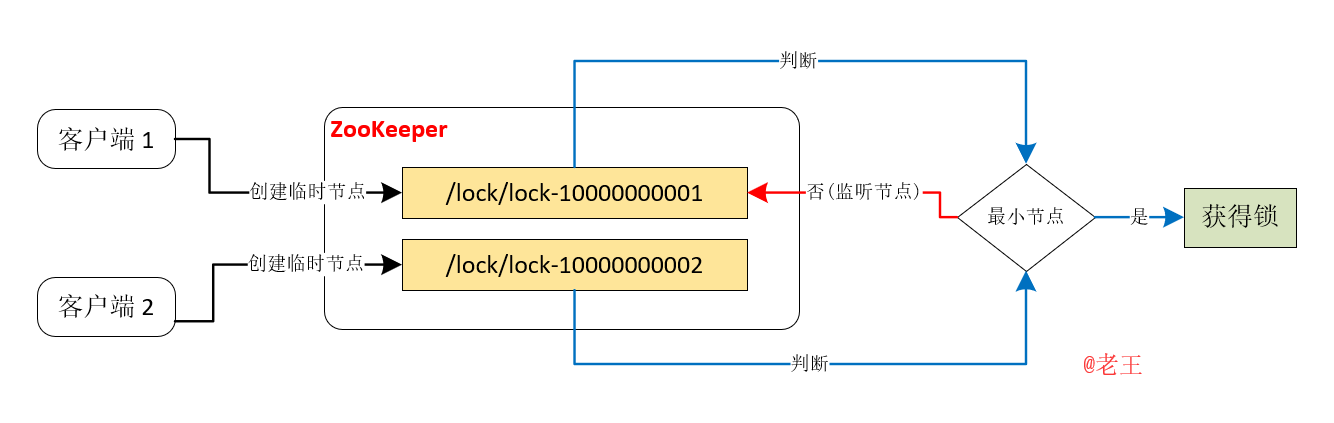
- 客户端连接 ZooKeeper,并在 /lock 第一个客户端对应的子节点是创建临时有序的子节点 /lock/lock-10000000001,第二个为 /lock/lock-以此类推。
- 客户端获取 /lock 下面的子节点列表,判断您创建的子节点是否是当前子节点列表中序列号最小的子节点。如果是,则认为锁定,否则监控只是删除您以前的子节点的消息,并在获得子节点变更通知后重复此步骤,直到锁定;
- 执行业务代码;
- 完成业务流程后,删除相应的子节点释放锁。
整体流程如下图所示:
7.ZooKeeper 如何实现分布式事务?
答:ZooKeeper 分布式事务的实现类似于两个阶段的提交,分为以下几个阶段 4 步:
- 客户端先给 ZooKeeper 节点发送写作请求;
- ZooKeeper 将写请求转发给节点 Leader 节点,Leader 广播要求集群投票,等待确认;
- Leader 收到确认后,统计投票,超过一半的投票将提交;
- 事务提交成功后,ZooKeeper 节点告知客户端。
8.为什么集群中要有主节点?
答:在分布式环境中,一些业务逻辑只需要集群中的一台机器来执行,其他机器可以共享结果,大大降低重复计算,提高性能,这就是主节点存在的意义。
9.Dubbo 是什么?
答:Dubbo 高性能、轻量级开源 Java RPC 该框架提供了三种核心能力:远程调用接口、智能容错和负载平衡,以及自动注册和发现服务。
10.Dubbo 有哪些特点?
答:Dubbo 特性如下:
- 面向接口代理的高性能 RPC 调用:提供基于代理的高性能远程调用能力,以接口为粒度,为开发人员屏蔽远程调用底层细节;
- 智能负载平衡:内置多种负载平衡策略,智能感知下游节点的健康状况,显著减少调用延迟,提高系统吞吐量;
- 自动注册和发现服务:支持各种注册中心服务,实时感知服务实例;
- 高可扩展性:遵循微内核 所有核心能力,如插件的设计原则 Protocol、Transport、Serialization 内置实现和第三方实现被设计为扩展点;
- 运行期流量调度:内置条件、脚本等路由策略,通过配置不同的路由规则,轻松实现灰度发布,同机房优先等功能;
- 可视化服务治理和运维:提供丰富的服务治理和运维工具:随时查询服务元数据、服务健康状况和调用统计,实时发布路由策略,调整配置参数。
11.Dubbo 核心组件有哪些?
答:Dubbo 核心组件如下:
- Provider:服务提供方
- Consumer:服务消费方
- Registry:注册中心的服务注册和发现
- Monitor:调用次数和调用时间主要用于统计服务
- Container:操作容器的服务
12.Dubbo 负载均衡策略有哪些?
答:Dubbo 均衡战略如下:
- 均衡的随机负载(Random LoadBalance):按权重设置随机概率,在一个截面上碰撞的概率高,但调用量越大分布越均匀,而且按概率使用权重后也比较均匀,有利于动态调整提供者权重;
- 平衡轮询负载(RoundRobin LoadBalance):根据公约后的权重设置轮询率,存在供应商积累请求缓慢的问题。例如,第二台机器非常缓慢,但没有悬挂。当请求转移到第二台时,它会卡在那里。随着时间的推移,所有的请求都会卡在第二台上;
- 至少活跃调用数负载平衡(LeastActive LoadBalance):使用最小活动调用数,指调用前后计数差;
- 哈希负载平衡(ConsistentHash LoadBalance):使用哈希值转发,同一参数的请求总是发送给同一供应商。
:
服务水平
<dubbo:service interface=“xxx” loadbalance=“roundrobin” />
客户端服务水平
<dubbo:reference interface=“xxx” loadbalance=“roundrobin” />
服务方法级别
<dubbo:service interface=“xxx”> <dubbo:method name=“xxx” loadbalance=“roundrobin”/> </dubbo:service>
客户端方法级别
<dubbo:reference interface=“xxx”> <dubbo:method name=“xxx” loadbalance=“roundrobin”/> &t;/dubbo:reference>
13.Dubbo 不支持以下哪种协议?
A:dubbo:// B:rmi:// C:redis:// D:restful://
答:D
题目解析:restful 一直编程规范,并不是一种传输协议,也不被 Dubbo 支持。
14.Dubbo 默认使用什么注册中心,还有别的选择吗?
答:推荐使用 ZooKeeper 作为注册中心,还有 Nacos、Redis、Simple 注册中心(普通的 Dubbo 服务)。
15.Dubbo 支持多注册中心吗?
答:Dubbo 支持同一服务向多注册中心同时注册,或者不同服务分别注册到不同的注册中心上去,甚至可以同时引用注册在不同注册中心上的同名服务。
多注册中心注册:
<?xml version="1.0" encoding="UTF-8"?> <dubbo:application name=“world” /> <dubbo:registry id=“hangzhouRegistry” address=“10.20.141.150:9090” /> <dubbo:registry id=“qingdaoRegistry” address=“10.20.141.151:9010” default=“false” /> <dubbo:service interface=“com.alibaba.hello.api.HelloService” version=“1.0.0” ref=“helloService” registry=“hangzhouRegistry,qingdaoRegistry” />
16.Dubbo 支持的连接方式有哪些?
答:Dubbo 支持的主要连接方式有:组播、直连和 ZooKeeper 等注册中心。
,不需要启动任何中心节点,只要广播地址一样,就可以互相发现。
- 提供方启动时广播自己的地址
- 消费方启动时广播订阅请求
- 提供方收到订阅请求时,单播自己的地址给订阅者,如果设置了 unicast=false,则广播给订阅者
- 消费方收到提供方地址时,连接该地址进行 RPC 调用
组播受网络结构限制,只适合小规模应用或开发阶段使用。组播地址段:224.0.0.0 ~ 239.255.255.255
配置
<dubbo:registry address=“multicast://224.5.6.7:1234” />
或
<dubbo:registry protocol=“multicast” address=“224.5.6.7:1234” />
为了减少广播量,Dubbo 缺省使用单播发送提供者地址信息给消费者,如果一个机器上同时启了多个消费者进程,消费者需声明 unicast=false,否则只会有一个消费者能收到消息;当服务者和消费者运行在同一台机器上,消费者同样需要声明 unicast=false,否则消费者无法收到消息,导致 No provider available for the service 异常:
<dubbo:registry address=“multicast://224.5.6.7:1234?unicast=false” />
或
<dubbo:registry protocol=“multicast” address=“224.5.6.7:1234”> <dubbo:parameter key=“unicast” value=“false” /> </dubbo:registry>
,注册中心本身就是一个普通的 Dubbo 服务,可以减少第三方依赖,使整体通讯方式一致。
<dubbo:registry protocol=“zookeeper” address=“N/A” file=“./.dubbo-platform”/>
将 Simple 注册中心暴露成 Dubbo 服务:
<?xml version="1.0" encoding="UTF-8"?> <dubbo:application name=“simple-registry” /> <dubbo:protocol port=“9090” /> <dubbo:service interface=“org.apache.dubbo.registry.RegistryService” ref=“registryService” registry=“N/A” ondisconnect=“disconnect” callbacks=“1000”> <dubbo:method name=“subscribe”><dubbo:argument index=“1” callback=“true” /></dubbo:method> <dubbo:method name=“unsubscribe”><dubbo:argument index=“1” callback=“false” /></dubbo:method> </dubbo:service>
引用 Simple Registry 服务:
<dubbo:registry address=“127.0.0.1:9090” />
或者:
<dubbo:service interface=“org.apache.dubbo.registry.RegistryService” group=“simple” version=“1.0.0” … >
或者:
<dubbo:registry address=“127.0.0.1:9090” group=“simple” version=“1.0.0” />
适用性说明:此 SimpleRegistryService 只是简单实现,不支持集群,可作为自定义注册中心的参考,但不适合直接用于生产环境。
,Zookeeper 是 Apacahe Hadoop 的子项目,是一个树型的目录服务,支持变更推送,适合作为 Dubbo 服务的注册中心,工业强度较高,可用于生产环境,并推荐使用。
流程说明:
- 服务提供者启动时:向 /dubbo/com.foo.BarService/providers 目录下写入自己的 URL 地址
- 服务消费者启动时:订阅 /dubbo/com.foo.BarService/providers 目录下的提供者 URL 地址,并向 /dubbo/com.foo.BarService/consumers 目录下写入自己的 URL 地址
- 监控中心启动时: 订阅 /dubbo/com.foo.BarService 目录下的所有提供者和消费者 URL 地址
支持以下功能:
- 当提供者出现断电等异常停机时,注册中心能自动删除提供者信息
- 当注册中心重启时,能自动恢复注册数据,以及订阅请求
- 当会话过期时,能自动恢复注册数据,以及订阅请求
- 当设置
<dubbo:registry check="false" />时,记录失败注册和订阅请求,后台定时重试 - 可通过
<dubbo:registry username="admin" password="1234" />设置 zookeeper 登录信息 - 可通过
<dubbo:registry group="dubbo" />设置 zookeeper 的根节点,不设置将使用无根树 - 支持
*号通配符<dubbo:reference group="*" version="*" />,可订阅服务的所有分组和所有版本的提供者
在 provider 和 consumer 中增加 zookeeper 客户端 jar 包依赖:
org.apache.zookeeper zookeeper 3.3.3
Dubbo 支持 zkclient 和 curator 两种 Zookeeper 客户端实现:
注意:在 2.7.x 的版本中已经移除了 zkclient 的实现,如果要使用 zkclient 客户端,需要自行拓展。
从 2.2.0 版本开始缺省为 zkclient 实现,以提升 zookeeper 客户端的健状性。zkclient 是 Datameer 开源的一个 Zookeeper 客户端实现。
缺省配置:
<dubbo:registry … client=“zkclient” />
或:
dubbo.registry.client=zkclient
或:
zookeeper://10.20.153.10:2181?client=zkclient
需依赖或直接下载:
com.github.sgroschupf zkclient 0.1
从 2.3.0 版本开始支持可选 curator 实现。Curator 是 Netflix 开源的一个 Zookeeper 客户端实现。
如果需要改为 curator 实现,请配置:
<dubbo:registry … client=“curator” />
或:
dubbo.registry.client=curator
或:
zookeeper://10.20.153.10:2181?client=curator
需依赖或直接下载:
com.netflix.curator curator-framework 1.1.10
Zookeeper 单机配置:
<dubbo:registry address=“zookeeper://10.20.153.10:2181” />
或:
<dubbo:registry protocol=“zookeeper” address=“10.20.153.10:2181” />
Zookeeper 集群配置:
<dubbo:registry address=“zookeeper://10.20.153.10:2181?backup=10.20.153.11:2181,10.20.153.12:2181” />
或:
<dubbo:registry protocol=“zookeeper” address=“10.20.153.10:2181,10.20.153.11:2181,10.20.153.12:2181” />
同一 Zookeeper,分成多组注册中心:
<dubbo:registry id=“chinaRegistry” protocol=“zookeeper” address=“10.20.153.10:2181” group=“china” /> <dubbo:registry id=“intlRegistry” protocol=“zookeeper” address=“10.20.153.10:2181” group=“intl” />
17.什么是服务熔断?
答:在应用系统服务中,当依赖服务因访问压力过大而响应变慢或失败,上游服务为了保护系统整体的可用性,临时切断对下游服务的调用。这种牺牲局部,保全整体的措施就叫做熔断。
18.Dubbo 可以对结果进行缓存吗?支持的缓存类型都有哪些?
答:可以,Dubbo 提供了声明式缓存,用于加速热门数据的访问速度,以减少用户加缓存的工作量。
Dubbo 支持的缓存类型有:
- lru 基于最近最少使用原则删除多余缓存,保持最热的数据被缓存;
- threadlocal 当前线程缓存,比如一个页面渲染,用到很多 portal,每个 portal 都要去查用户信息,通过线程缓存,可以减少这种多余访问;
- jcache 集成,可以桥接各种缓存实现。
配置如下:
<dubbo:reference interface=“com.foo.BarService” cache=“lru” />
或
<dubbo:reference interface=“com.foo.BarService”> <dubbo:method name=“findBar” cache=“lru” /> </dubbo:reference>
19.Dubbo 有几种集群容错模式?
答:Dubbo 集群容错模式如下。
① Failover Cluster
失败自动切换,当出现失败,重试其他服务器。通常用于读操作,但重试会带来更长延迟。可通过 retries="2" 来设置重试次数(不含第一次)。
重试次数配置如下:
<dubbo:service retries=“2” />
或
<dubbo:reference retries=“2” />
或
dubbo:reference <dubbo:method name=“findFoo” retries=“2” /> </dubbo:reference>
② Failfast Cluster
快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录。
③ Failsafe Cluster
失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作。
④ Failback Cluster
失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。
⑤ Forking Cluster
并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过 forks=“2” 来设置最大并行数。
⑥ Broadcast Cluster
广播调用所有提供者,逐个调用,任意一台报错则报错。通常用于通知所有提供者更新缓存或日志等本地资源信息。
设计模式常见面试题汇总
1.说一下设计模式?你都知道哪些?
答:设计模式总共有 23 种,总体来说可以分为三大类:创建型模式( Creational Patterns )、结构型模式( Structural Patterns )和行为型模式( Behavioral Patterns )。
| 创建型模式 | 工厂模式、抽象工厂模式、单例模式、建造者模式、原型模式 | 关注于对象的创建,同时隐藏创建逻辑 |
| 结构型模式 | 适配器模式、过滤器模式、装饰模式、享元模式、代理模式、外观模式、组合模式、桥接模式 | 关注类和对象之间的组合 |
| 行为型模式 | 责任链模式、命令模式、中介者模式、观察者模式、状态模式、策略模式、模板模式、空对象模式、备忘录模式、迭代器模式、解释器模式、访问者模式 | |
| 关注对象之间的通信 |
下面会对常用的设计模式分别做详细的说明。
2.什么是单例模式?
答:单例模式是一种常用的软件设计模式,在应用这个模式时,单例对象的类必须保证只有一个实例存在,整个系统只能使用一个对象实例。
优点:不会频繁地创建和销毁对象,浪费系统资源。
使用场景:IO 、数据库连接、Redis 连接等。
单例模式代码实现:
class Singleton {
private static Singleton instance = new Singleton();
public static Singleton getInstance() {
return instance;
}
}
单例模式调用代码:
public class Lesson7_3 {
public static void main(String[] args) {
Singleton singleton1 = Singleton.getInstance();
Singleton singleton2 = Singleton.getInstance();
System.out.println(singleton1 == singleton2);
}
}
程序的输出结果:true
可以看出以上单例模式是在类加载的时候就创建了,这样会影响程序的启动速度,那如何实现单例模式的延迟加载?在使用时再创建?
单例延迟加载代码:
// 单例模式-延迟加载版
class SingletonLazy {
private static SingletonLazy instance;
public static SingletonLazy getInstance() {
if (instance == null) {
instance = new SingletonLazy();
}
return instance;
}
}
以上为非线程安全的,单例模式如何支持多线程?
使用 synchronized 来保证,单例模式的线程安全代码:
class SingletonLazy {
private static SingletonLazy instance;
public static synchronized SingletonLazy getInstance() {
if (instance == null) {
instance = new SingletonLazy();
}
return instance;
}
}
3.什么是简单工厂模式?
答:简单工厂模式又叫静态工厂方法模式,就是建立一个工厂类,对实现了同一接口的一些类进行实例的创建。比如,一台咖啡机就可以理解为一个工厂模式,你只需要按下想喝的咖啡品类的按钮(摩卡或拿铁),它就会给你生产一杯相应的咖啡,你不需要管它内部的具体实现,只要告诉它你的需求即可。
:
- 工厂类含有必要的判断逻辑,可以决定在什么时候创建哪一个产品类的实例,客户端可以免除直接创建产品对象的责任,而仅仅“消费”产品;简单工厂模式通过这种做法实现了对责任的分割,它提供了专门的工厂类用于创建对象;
- 客户端无须知道所创建的具体产品类的类名,只需要知道具体产品类所对应的参数即可,对于一些复杂的类名,通过简单工厂模式可以减少使用者的记忆量;
- 通过引入配置文件,可以在不修改任何客户端代码的情况下更换和增加新的具体产品类,在一定程度上提高了系统的灵活性。
:
- 不易拓展,一旦添加新的产品类型,就不得不修改工厂的创建逻辑;
- 产品类型较多时,工厂的创建逻辑可能过于复杂,一旦出错可能造成所有产品的创建失败,不利于系统的维护。
简单工厂示意图如下:
简单工厂 :
class Factory {
public static String createProduct(String product) {
String result = null;
switch (product) {
case "Mocca":
result = "摩卡";
break;
case "Latte":
result = "拿铁";
break;
default:
result = "其他";
break;
}
return result;
}
}
4.什么是抽象工厂模式?
答:抽象工厂模式是在简单工厂的基础上将未来可能需要修改的代码抽象出来,通过继承的方式让子类去做决定。
比如,以上面的咖啡工厂为例,某天我的口味突然变了,不想喝咖啡了想喝啤酒,这个时候如果直接修改简单工厂里面的代码,这种做法不但不够优雅,也不符合软件设计的“开闭原则”,因为每次新增品类都要修改原来的代码。这个时候就可以使用抽象工厂类了,抽象工厂里只声明方法,具体的实现交给子类(子工厂)去实现,这个时候再有新增品类的需求,只需要新创建代码即可。
抽象工厂实现代码如下:
public class AbstractFactoryTest {
public static void main(String[] args) {
// 抽象工厂
String result = (new CoffeeFactory()).createProduct("Latte");
System.out.println(result); // output:拿铁
}
}
// 抽象工厂
abstract class AbstractFactory{
public abstract String createProduct(String product);
}
// 啤酒工厂
class BeerFactory extends AbstractFactory{
@Override
public String createProduct(String product) {
String result = null;
switch (product) {
case "Hans":
result = "汉斯";
break;
case "Yanjing":
result = "燕京";
break;
default:
result = "其他啤酒";
break;
}
return result;
}
}
/*
* 咖啡工厂
*/
class CoffeeFactory extends AbstractFactory{
@Override
public String createProduct(String product) {
String result = null;
switch (product) {
case "Mocca":
result = "摩卡";
break;
case "Latte":
result = "拿铁";
break;
default:
result = "其他咖啡";
break;
}
return result;
}
}
5.什么是观察者模式?
观察者模式是定义对象间的一种一对多依赖关系,使得每当一个对象状态发生改变时,其相关依赖对象皆得到通知并被自动更新。观察者模式又叫做发布- 订阅(Publish/Subscribe)模式、模型- 视图(Model/View)模式、源-监听器(Source/Listener)模式或从属者(Dependents)模式。 :
- 观察者模式可以实现表示层和数据逻辑层的分离,并定义了稳定的消息更新传递机制,抽象了更新接口,使得可以有各种各样不同的表示层作为具体观察者角色;
- 观察者模式在观察目标和观察者之间建立一个抽象的耦合;
- 观察者模式支持广播通信;
- 观察者模式符合开闭原则(对拓展开放,对修改关闭)的要求。
:
- 如果一个观察目标对象有很多直接和间接的观察者的话,将所有的观察者都通知到会花费很多时间;
- 如果在观察者和观察目标之间有循环依赖的话,观察目标会触发它们之间进行循环调用,可能导致系统崩溃;
- 观察者模式没有相应的机制让观察者知道所观察的目标对象是怎么发生变化的,而仅仅只是知道观察目标发生了变化。
在观察者模式中有如下角色:
- Subject:抽象主题(抽象被观察者),抽象主题角色把所有观察者对象保存在一个集合里,每个主题都可以有任意数量的观察者,抽象主题提供一个接口,可以增加和删除观察者对象;
- ConcreteSubject:具体主题(具体被观察者),该角色将有关状态存入具体观察者对象,在具体主题的内部状态发生改变时,给所有注册过的观察者发送通知;
- Observer:抽象观察者,是观察者者的抽象类,它定义了一个更新接口,使得在得到主题更改通知时更新自己;
- ConcrereObserver:具体观察者,实现抽象观察者定义的更新接口,以便在得到主题更改通知时更新自身的状态。
观察者模式实现代码如下。
1)定义观察者(消息接收方)
/*
* 观察者(消息接收方)
*/
interface Observer {
public void update(String message);
}
/*
* 具体的观察者(消息接收方)
*/
class ConcrereObserver implements Observer {
private String name;
public ConcrereObserver(String name) {
this.name = name;
}
@Override
public void update(String message) {
System.out.println(name + ":" + message);
}
}
2)定义被观察者(消息发送方)
/*
* 被观察者(消息发布方)
*/
interface Subject {
// 增加订阅者
public void attach(Observer observer);
// 删除订阅者
public void detach(Observer observer);
// 通知订阅者更新消息
public void notify(String message);
}
/*
* 具体被观察者(消息发布方)
*/
class ConcreteSubject implements Subject {
// 订阅者列表(存储信息)
private List<Observer> list = new ArrayList<Observer>();
@Override
public void attach(Observer observer) {
list.add(observer);
}
@Override
public void detach(Observer observer) {
list.remove(observer);
}
@Override
public void notify(String message) {
for (Observer observer : list) {
observer.update(message);
}
}
}
3)代码调用
public class ObserverTest {
public static void main(String[] args) {
// 定义发布者
ConcreteSubject concreteSubject = new ConcreteSubject();
// 定义订阅者
ConcrereObserver concrereObserver = new ConcrereObserver("老王");
ConcrereObserver concrereObserver2 = new ConcrereObserver("Java");
// 添加订阅
concreteSubject.attach(concrereObserver);
concreteSubject.attach(concrereObserver2);
// 发布信息
concreteSubject.notify("更新了");
}
}
程序执行结果如下:
老王:更新了
Java:更新了
6.什么是装饰器模式?
答:装饰器模式是指动态地给一个对象增加一些额外的功能,同时又不改变其结构。
优点:装饰类和被装饰类可以独立发展,不会相互耦合,装饰模式是继承的一个替代模式,装饰模式可以动态扩展一个实现类的功能。
装饰器模式的关键:装饰器中使用了被装饰的对象。
比如,创建一个对象“laowang”,给对象添加不同的装饰,穿上夹克、戴上帽子…,这个执行过程就是装饰者模式,实现代码如下。
1)定义顶层对象,定义行为
interface IPerson {
void show();
}
2)定义装饰器超类
class DecoratorBase implements IPerson{
IPerson iPerson;
public DecoratorBase(IPerson iPerson){
this.iPerson = iPerson;
}
@Override
public void show() {
iPerson.show();
}
}
3)定义具体装饰器
class Jacket extends DecoratorBase {
public Jacket(IPerson iPerson) {
super(iPerson);
}
@Override
public void show() {
// 执行已有功能
iPerson.show();
// 定义新行为
System.out.println("穿上夹克");
}
}
class Hat extends DecoratorBase {
public Hat(IPerson iPerson) {
super(iPerson);
}
@Override
public void show() {
// 执行已有功能
iPerson.show();
// 定义新行为
System.out.println("戴上帽子");
}
}
4)定义具体对象
class LaoWang implements IPerson{
@Override
public void show() {
System.out.println("什么都没穿");
}
}
5)装饰器模式调用
public class DecoratorTest {
public static void main(String[] args) {
LaoWang laoWang = new LaoWang();
Jacket jacket = new Jacket(laoWang);
Hat hat = new Hat(jacket);
hat.show();
}
}
7.什么是模板方法模式?
答:模板方法模式是指定义一个模板结构,将具体内容延迟到子类去实现。
:
- 提高代码复用性:将相同部分的代码放在抽象的父类中,而将不同的代码放入不同的子类中;
- 实现了反向控制:通过一个父类调用其子类的操作,通过对子类的具体实现扩展不同的行为,实现了反向控制并且符合开闭原则。
以给冰箱中放水果为例,比如,我要放一个香蕉:开冰箱门 → 放香蕉 → 关冰箱门;如果我再要放一个苹果:开冰箱门 → 放苹果 → 关冰箱门。可以看出它们之间的行为模式都是一样的,只是存放的水果品类不同而已,这个时候就非常适用模板方法模式来解决这个问题,实现代码如下:
/*
* 添加模板方法
*/
abstract class Refrigerator {
public void open() {
System.out.println("开冰箱门");
}
public abstract void put();
public void close() {
System.out.println("关冰箱门");
}
}
class Banana extends Refrigerator {
@Override
public void put() {
System.out.println("放香蕉");
}
}
class Apple extends Refrigerator {
@Override
public void put() {
System.out.println("放苹果");
}
}
/*
* 调用模板方法
*/
public class TemplateTest {
public static void main(String[] args) {
Refrigerator refrigerator = new Banana();
refrigerator.open();
refrigerator.put();
refrigerator.close();
}
}
程序执行结果:
开冰箱门
放香蕉
关冰箱门
8.什么是代理模式?
代理模式是给某一个对象提供一个代理,并由代理对象控制对原对象的引用。
:
- 代理模式能够协调调用者和被调用者,在一定程度上降低了系统的耦合度;
- 可以灵活地隐藏被代理对象的部分功能和服务,也增加额外的功能和服务。
:
- 由于使用了代理模式,因此程序的性能没有直接调用性能高;
- 使用代理模式提高了代码的复杂度。
举一个生活中的例子:比如买飞机票,由于离飞机场太远,直接去飞机场买票不太现实,这个时候我们就可以上携程 App 上购买飞机票,这个时候携程 App 就相当于是飞机票的代理商。
代理模式实现代码如下:
/*
* 定义售票接口
*/
interface IAirTicket {
void buy();
}
/*
* 定义飞机场售票
*/
class AirTicket implements IAirTicket {
@Override
public void buy() {
System.out.println("买票");
}
}
/*
* 代理售票平台
*/
class ProxyAirTicket implements IAirTicket {
private AirTicket airTicket;
public ProxyAirTicket() {
airTicket = new AirTicket();
}
@Override
public void buy() {
airTicket.buy();
}
}
/*
* 代理模式调用
*/
public class ProxyTest {
public static void main(String[] args) {
IAirTicket airTicket = new ProxyAirTicket();
airTicket.buy();
}
}
9.什么是策略模式?
答:策略模式是指定义一系列算法,将每个算法都封装起来,并且使他们之间可以相互替换。
:遵循了开闭原则,扩展性良好。
:随着策略的增加,对外暴露越来越多。
以生活中的例子来说,比如我们要出去旅游,选择性很多,可以选择骑车、开车、坐飞机、坐火车等,就可以使用策略模式,把每种出行作为一种策略封装起来,后面增加了新的交通方式了,如超级高铁、火箭等,就可以不需要改动原有的类,新增交通方式即可,这样也符合软件开发的开闭原则。 策略模式实现代码如下:
/*
* 声明旅行
*/
interface ITrip {
void going();
}
class Bike implements ITrip {
@Override
public void going() {
System.out.println("骑自行车");
}
}
class Drive implements ITrip {
@Override
public void going() {
System.out.println("开车");
}
}
/*
* 定义出行类
*/
class Trip {
private ITrip trip;
public Trip(ITrip trip) {
this.trip = trip;
}
public void doTrip() {
this.trip.going();
}
}
/*
* 执行方法
*/
public class StrategyTest {
public static void main(String[] args) {
Trip trip = new Trip(new Bike());
trip.doTrip();
}
}
程序执行的结果:
骑自行车
10.什么是适配器模式?
答:适配器模式是将一个类的接口变成客户端所期望的另一种接口,从而使原本因接口不匹配而无法一起工作的两个类能够在一起工作。
:
- 可以让两个没有关联的类一起运行,起着中间转换的作用;
- 灵活性好,不会破坏原有的系统。
:过多地使用适配器,容易使代码结构混乱,如明明看到调用的是 A 接口,内部调用的却是 B 接口的实现。
以生活中的例子来说,比如有一个充电器是 MicroUSB 接口,而手机充电口却是 TypeC 的,这个时候就需要一个把 MicroUSB 转换成 TypeC 的适配器,如下图所示:
适配器实现代码如下:
/*
* 传统的充电线 MicroUSB
*/
interface MicroUSB {
void charger();
}
/*
* TypeC 充电口
*/
interface ITypeC {
void charger();
}
class TypeC implements ITypeC {
@Override
public void charger() {
System.out.println("TypeC 充电");
}
}
/*
* 适配器
*/
class AdapterMicroUSB implements MicroUSB {
private TypeC typeC;
public AdapterMicroUSB(TypeC typeC) {
this.typeC = typeC;
}
@Override
public void charger() {
typeC.charger();
}
}
/*
* 测试调用
*/
public class AdapterTest {
public static void main(String[] args) {
TypeC typeC = new TypeC();
MicroUSB microUSB = new AdapterMicroUSB(typeC);
microUSB.charger();
}
}
程序执行结果:
TypeC 充电
11.JDK 类库常用的设计模式有哪些?
答:JDK 常用的设计模式如下:
1)工厂模式
java.text.DateFormat 工具类,它用于格式化一个本地日期或者时间。
public final static DateFormat getDateInstance();
public final static DateFormat getDateInstance(int style);
public final static DateFormat getDateInstance(int style,Locale locale);
加密类
KeyGenerator keyGenerator = KeyGenerator.getInstance("DESede");
Cipher cipher = Cipher.getInstance("DESede");
2)适配器模式
把其他类适配为集合类
List<Integer> arrayList = java.util.Arrays.asList(new Integer[]{1,2,3});
List<Integer> arrayList = java.util.Arrays.asList(1,2,3);
3)代理模式
如 JDK 本身的动态代理。
interface Animal {
void eat();
}
class Dog implements Animal {
@Override
public void eat() {
System.out.println("The dog is eating");
}
}
class Cat implements Animal {
@Override
public void eat() {
System.out.println("The cat is eating");
}
}
// JDK 代理类
class AnimalProxy implements InvocationHandler {
private Object target; // 代理对象
public Object getInstance(Object target) {
this.target = target;
// 取得代理对象
return Proxy.newProxyInstance(target.getClass().getClassLoader(), target.getClass().getInterfaces(), this);
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("调用前");
Object result = method.invoke(target, args); // 方法调用
System.out.println("调用后");
return result;
}
}
public static void main(String[] args) {
// JDK 动态代理调用
AnimalProxy proxy = new AnimalProxy();
Animal dogProxy = (Animal) proxy.getInstance(new Dog());
dogProxy.eat();
}
4)单例模式
全局只允许有一个实例,比如:
Runtime.getRuntime();
5)装饰器
为一个对象动态的加上一系列的动作,而不需要因为这些动作的不同而产生大量的继承类。
java.io.BufferedInputStream(InputStream);
java.io.DataInputStream(InputStream);
java.io.BufferedOutputStream(OutputStream);
java.util.zip.ZipOutputStream(OutputStream);
java.util.Collections.checkedList(List list, Class type) ;
6)模板方法模式
定义一个操作中算法的骨架,将一些步骤的执行延迟到其子类中。
比如,Arrays.sort() 方法,它要求对象实现 Comparable 接口。
class Person implements Comparable{
private Integer age;
public Person(Integer age){
this.age = age;
}
@Override
public int compareTo(Object o) {
Person person = (Person)o;
return this.age.compareTo(person.age);
}
}
public class SortTest(){
public static void main(String[] args){
Person p1 = new Person(10);
Person p2 = new Person(5);
Person p3 = new Person(15);
Person[] persons = {p1,p2,p3};
//排序
Arrays.sort(persons);
}
}
12.IO 使用了什么设计模式?
答:IO 使用了适配器模式和装饰器模式。
- 适配器模式:由于 InputStream 是字节流不能享受到字符流读取字符那么便捷的功能,借助 InputStreamReader 将其转为 Reader 子类,因而可以拥有便捷操作文本文件方法;
- 装饰器模式:将 InputStream 字节流包装为其他流的过程就是装饰器模式,比如,包装为 FileInputStream、ByteArrayInputStream、PipedInputStream 等。
13.Spring 中都使用了哪些设计模式?
答:Spring 框架使用的设计模式如下。
- 代理模式:在 AOP 中有使用
- 单例模式:bean 默认是单例模式
- 模板方法模式:jdbcTemplate
- 工厂模式:BeanFactory
- 观察者模式:Spring 事件驱动模型就是观察者模式很经典的一个应用,比如,ContextStartedEvent 就是 ApplicationContext 启动后触发的事件
- 适配器模式:Spring MVC 中也是用到了适配器模式适配 Controller
算法常用面试题汇总
1.说一下什么是二分法?使用二分法时需要注意什么?如何用代码实现?
二分法查找(Binary Search)也称折半查找,是指当每次查询时,将数据分为前后两部分,再用中值和待搜索的值进行比较,如果搜索的值大于中值,则使用同样的方式(二分法)向后搜索,反之则向前搜索,直到搜索结束为止。
二分法使用的时候需要注意:二分法只适用于有序的数据,也就是说,数据必须是从小到大,或是从大到小排序的。
public class Lesson7_4 {
public static void main(String[] args) {
// 二分法查找
int[] binaryNums = {1, 6, 15, 18, 27, 50};
int findValue = 27;
int binaryResult = binarySearch(binaryNums, 0, binaryNums.length - 1, findValue);
System.out.println("元素第一次出现的位置(从0开始):" + binaryResult);
}
/**
* 二分查找,返回该值第一次出现的位置(下标从 0 开始)
* @param nums 查询数组
* @param start 开始下标
* @param end 结束下标
* @param findValue 要查找的值
* @return int
*/
private static int binarySearch(int[] nums, int start, int end, int findValue) {
if (start <= end) {
// 中间位置
int middle = (start + end) / 2;
// 中间的值
int middleValue = nums[middle];
if (findValue == middleValue) {
// 等于中值直接返回
return middle;
} else if (findValue < middleValue) {
// 小于中值,在中值之前的数据中查找
return binarySearch(nums, start, middle - 1, findValue);
} else {
// 大于中值,在中值之后的数据中查找
return binarySearch(nums, middle + 1, end, findValue);
}
}
return -1;
}
}
执行结果如下:
元素第一次出现的位置(从0开始):4
2.什么是斐波那契数列?用代码如何实现?
斐波那契数列(Fibonacci Sequence),又称黄金分割数列、因数学家列昂纳多·斐波那契(Leonardoda Fibonacci)以兔子繁殖为例子而引入,故又称为“兔子数列”,指的是这样一个数列:1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233,377,610,987,1597,2584,4181,6765,10946,17711… 在数学上,斐波那契数列以如下被以递推的方法定义:F(1)=1,F(2)=1, F(n)=F(n-1)+F(n-2)(n>=3,n∈N*)在现代物理、准晶体结构、化学等领域,斐波纳契数列都有直接的应用。
斐波那契数列之所以又称黄金分割数列,是因为随着数列项数的增加,前一项与后一项之比越来越逼近黄金分割的数值 0.6180339887…
斐波那契数列指的是这样一个数列:1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233,377,610,987,1597,2584,4181,6765,10946,17711…
:第三项开始(含第三项)它的值等于前两项之和。
斐波那契数列代码实现示例,如下所示:
public class Lesson7_4 {
public static void main(String[] args) {
// 斐波那契数列
int fibonacciIndex = 7;
int fibonacciResult = fibonacci(fibonacciIndex);
System.out.println("下标(从0开始)" + fibonacciIndex + "的值为:" + fibonacciResult);
}
/**
* 斐波那契数列
* @param index 斐波那契数列的下标(从0开始)
* @return int
*/
private static int fibonacci(int index) {
if (index == 0 || index == 1) {
return index;
} else {
return fibonacci(index - 1) + fibonacci(index - 2);
}
}
}
执行结果如下:
下标(从0开始)7的值为:13
3.一般而言,兔子在出生两个月后,就有繁殖能力,一对兔子每个月能生出一对小兔子来。如果所有兔子都不死,那么一年以后可以繁殖多少对兔子?请使用代码实现。
先来分析一下,本题目
- 第一个月:有 1 对小兔子;
- 第二个月:小兔子变成大兔子;
- 第三个月:大兔子下了一对小兔子;
- 第四个月:大兔子又下了一对小兔子,上个月的一对小兔子变成了大兔子;
- …
最后总结的规律如下列表所示:
| 月数 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | … |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 幼仔对数 | 1 | 0 | 1 | 1 | 2 | 3 | 5 | 8 | 13 | 21 | 34 | 55 | … |
| 成兔对数 | 0 | 1 | 1 | 2 | 3 | 5 | 8 | 13 | 21 | 34 | 55 | 89 | |
| 总对数 | 1 | 1 | 2 | 3 | 5 | 8 | 13 | 21 | 34 | 55 | 89 | 144 |
可以看出,兔子每个月的总对数刚好符合斐波那契数列,第 12 个月的时候,总共有 144 对兔子。 实现代码如下:
public class Lesson7_4 {
public static void main(String[] args) {
// 兔子的总对数
int rabbitNumber = fibonacci(12);
System.out.println("第 12 个月兔子的总对数是:" + rabbitNumber);
}
/**
* 斐波那契数列
* @param index 斐波那契数列的下标(从0开始)
* @return int
*/
private static int fibonacci(int index) {
if (index == 0 || index == 1) {
return index;
} else {
return fibonacci(index - 1) + fibonacci(index - 2);
}
}
}
执行结果如下:
第 12 个月兔子的总对数是:144
4.什么是冒泡排序?用代码如何实现?
冒泡排序(Bubble Sort)算法是所有排序算法中最简单、最基础的一个,它的实现思路是通过相邻数据的交换达到排序的目的。
冒泡排序的执行流程是:
- 对数组中相邻的数据,依次进行比较;
- 如果前面的数据大于后面的数据,则把前面的数据交换到后面。经过一轮比较之后,就能把数组中最大的数据排到数组的最后面了;
- 再用同样的方法,把剩下的数据逐个进行比较排序,最后得到就是从小到大排序好的数据。
冒泡排序算法代码实现,如下所示:
public class Lesson7_4 {
public static void main(String[] args) {
// 冒泡排序调用
int[] bubbleNums = {132, 110, 122, 90, 50};
System.out.println("排序前:" + Arrays.toString(bubbleNums));
bubbleSort(bubbleNums);
System.out.println("排序后:" + Arrays.toString(bubbleNums));
}
/**
* 冒泡排序
*/
private static void bubbleSort(int[] nums) {
int temp;
for (int i = 1; i < nums.length; i++) {
for (int j = 0; j < nums.length - i; j++) {
if (nums[j] > nums[j + 1]) {
temp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = temp;
}
}
System.out.print("第" + i + "次排序:");
System.out.println(Arrays.toString(nums));
}
}
}
执行结果如下:
排序前:[132, 110, 122, 90, 50]
第1次排序:[110, 122, 90, 50, 132]
第2次排序:[110, 90, 50, 122, 132]
第3次排序:[90, 50, 110, 122, 132]
第4次排序:[50, 90, 110, 122, 132]
排序后:[50, 90, 110, 122, 132]
5.什么是选择排序?用代码如何实现?
选择排序(Selection Sort)算法也是比较简单的排序算法,其实现思路是每一轮循环找到最小的值,依次排到数组的最前面,这样就实现了数组的有序排列。
比如,下面是一组数据使用选择排序的执行流程:
- 初始化数据:18, 1, 6, 27, 15
- 第一次排序:1, 18, 6, 27, 15
- 第二次排序:1, 6, 18, 27, 15
- 第三次排序:1, 6, 15, 27, 18
- 第四次排序:1, 6, 15, 18, 27
选择排序算法代码实现,如下所示:
public class Lesson7_4 {
public static void main(String[] args) {
// 选择排序调用
int[] selectNums = {18, 1, 6, 27, 15};
System.out.println("排序前:" + Arrays.toString(selectNums));
selectSort(selectNums);
System.out.println("排序后:" + Arrays.toString(selectNums));
}
/**
* 选择排序
*/
private static void selectSort(int[] nums) {
int index;
int temp;
for (int i = 0; i < nums.length - 1; i++) {
index = i;
for (int j = i + 1; j < nums.length; j++) {
if (nums[j] < nums[index]) {
index = j;
}
}
if (index != i) {
temp = nums[i];
nums[i] = nums[index];
nums[index] = temp;
}
System.out.print("第" + i + "次排序:");
System.out.println(Arrays.toString(nums));
}
}
}
执行结果如下:
排序前:[18, 1, 6, 27, 15]
第0次排序:[1, 18, 6, 27, 15]
第1次排序:[1, 6, 18, 27, 15]
第2次排序:[1, 6, 15, 27, 18]
第3次排序:[1, 6, 15, 18, 27]
排序后:[1, 6, 15, 18, 27]
6.什么是插入排序?用代码如何实现?
插入排序(Insertion Sort)算法是指依次把当前循环的元素,通过对比插入到合适位置的排序算法。 比如,下面是一组数据使用插入排序的执行流程:
- 初始化数据:18, 1, 6, 27, 15
- 第一次排序:1, 18, 6, 27, 15
- 第二次排序:1, 6, 18, 27, 15
- 第三次排序:1, 6, 18, 27, 15
- 第四次排序:1, 6, 15, 18, 27
插入排序算法代码实现,如下所示:
public class Lesson7_4 {
public static void main(String[] args) {
// 插入排序调用
int[] insertNums = {18, 1, 6, 27, 15};
System.out.println("排序前:" + Arrays.toString(insertNums));
insertSort(insertNums);
System.out.println("排序后:" + Arrays.toString(insertNums));
}
/**
* 插入排序
*/
private static void insertSort(int[] nums) {
int i, j, k;
for (i = 1; i < nums.length; i++) {
k = nums[i];
j = i - 1;
// 对 i 之前的数据,给当前元素找到合适的位置
while (j >= 0 && k < nums[j]) {
nums[j + 1] = nums[j];
// j-- 继续往前寻找
j--;
}
nums[j + 1] = k;
System.out.print("第" + i + "次排序:");
System.out.println(Arrays.toString(nums));
}
}
}
执行结果如下:
排序前:[18, 1, 6, 27, 15]
第1次排序:[1, 18, 6, 27, 15]
第2次排序:[1, 6, 18, 27, 15]
第3次排序:[1, 6, 18, 27, 15]
第4次排序:[1, 6, 15, 18, 27]
排序后:[1, 6, 15, 18, 27]
7.什么是快速排序?用代码如何实现?
快速排序(Quick Sort)算法和冒泡排序算法类似,都是基于交换排序思想实现的,快速排序算法是对冒泡排序算法的改进,从而具有更高的执行效率。
快速排序是通过多次比较和交换来实现排序的执行流程如下:
- 首先设定一个分界值,通过该分界值把数组分为左右两个部分;
- 将大于等于分界值的元素放到分界值的右边,将小于分界值的元素放到分界值的左边;