目录
- Abstract
- Introduction
- Related Work
- Model
-
- A. Background: GAIL and PPO
-
- 1. 行为克隆(Behavior Cloning)
- 2. GAIL方法
- B. Reinforcement and Imitation Learning Model
-
- 1.Hybrid IL/RL Reward
- 2.Leveraging Physical States in Simulation
-
- (1) Demonstration as a curriculum.
- (2) Learning value functions from states
- (3) Object-centric discriminator
- (4) State prediction auxiliary tasks
- 3.Sim2Real Policy Transfer
- Experiments
-
- A. Environment Setups
- B. Robot Arm Manipulation Tasks
- C. Quantitative Evaluation
- D.Sim2Real Policy Transfer Results
- Discussion
- Conclusion
Abstract
We propose a model-free deep reinforcement learning method that leverages a small amount of demonstration data to assist a reinforcement learning agent. 作者在文章中提出了一种基于自由的深度强化学习方法,帮助一个强化学习智能体(训练)的数据较少。
We apply this approach to robotic manipulation tasks and train end-to-end visuomotor policies that map directly from RGB camera inputs to joint velocities. 作者将该方法应用于机器人捕获和训练端到端的移动视觉策略,主要指从RGB相机输入直接映射到关节移动。
We demonstrate that our approach can solve a wide variety of visuomotor tasks, for which engineering a scripted controller would be laborious. 作者验证了这种方法可以解决大量的移动视觉任务,这对于设计脚本控制器来说非常困难。
In experiments, our reinforcement and imitation agent achieves significantly better performances than agents trained with reinforcement learning or imitation learning alone. 在实验中,加强学习 启发学习组合的性能优于单独强化学习和单独启发学习。
We also illustrate that these policies, trained with large visual and dynamics variations, can achieve preliminary successes in zero-shot sim2real transfer. 我们解释说,这些方法在大量的视觉和动态变化中取得了基本的效果。
Introduction
For robotics, RL in combination with powerful function approximators such as neural networks provides a general framework for designing sophisticated controllers that would be hard to handcraft otherwise. 结合强大的函数近似,如神经网络,强化学习可以提供一个通用的计算框架来设计难以手工设计的控制器。
Nevertheless, end-to-end learning of visuomotor controllers for long-horizon and multi-stage manipulation tasks using model-free RL techniques remains a challenging problem. 使用无模型强化学习技术来处理移动视觉控制器的端到端学习,并在长期、多阶段的操作任务中使用,仍然是一个难题。
Policies for robotics must transform multi-modal and partial observations from noisy sensors, such as cameras, into coordinated activity of many degrees of freedom. 机器人策略必须将噪声传感器的多模态和部分观察到的信息转换为多自由协调运动。
At the same time, realistic tasks often come with contactrich dynamics and vary along multiple dimensions (visual appearance, position, shapes, etc.), posing significant generalization challenges. 同时,在分接触和多维信息,包括视觉外观、位置和形状,通常伴随着现实任务,带来了重大的泛化性能挑战。
Model-based methods can have difficulties handling such complex dynamics and large variations. Directly training model-free methods on real robotics hardware can be daunting due to the high sample complexity. 加强学习的两个分类:基于模型和自由 基于模型可能很难解决这个问题 由于高样本的复杂性,基于自由会更加困难
The difficulty of real-world RL training is compounded by safety considerations as well as the difficulty of accessing information about the state of the environment (e.g. the position of an object) to define a reward function. 现实世界的强化学习训练包括: 1、安全考虑 2.获取环境状态信息(如物体的各种姿势信息)来定义奖励函数的困难
Finally, even in simulation when perfect state information and large amounts of training data are available, exploration can be a significant challenge, especially for on-policy methods. 加强学习中的探索利用也很困难 特别是同一策略的方法
This is partly due to the often high-dimensional and continuous action space, but also due to the difficulty of designing suitable reward functions. 训练困难的原因: 高维连续动作空间; 设计合适的奖励函数;
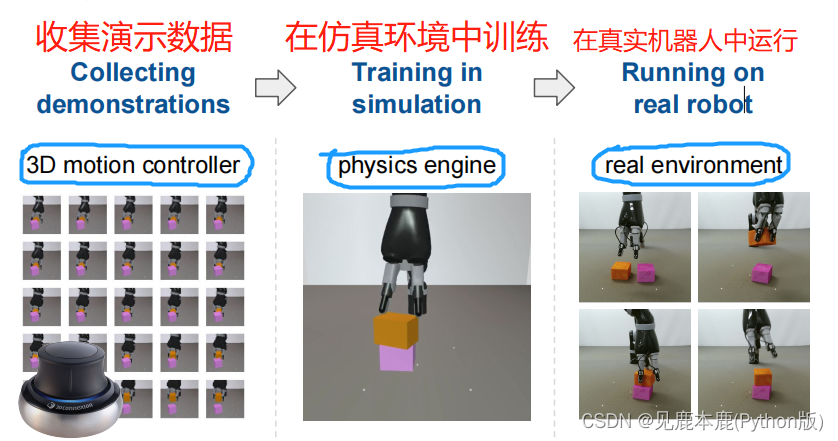
In this paper, we present a model-free deep RL method that can solve a variety of robotic manipulation tasks directly from pixel input. Our key insights are 1) to reduce the difficulty of exploration in continuous domains by leveraging a handful of huan demonstrations; 2) to leverage several new techniques that exploit privileged and task-specific information during training only which can accelerate and stabilize the learning of visuomotor policies in multi-stage tasks; and 3) to improve generalization by increasing the diversity of the training conditions. As a result, the policies work well under significant variations of system dynamics, object appearances, task lengths, etc. 1、的强化学习模型; 2、解决从像素点输入的机器人操作任务; 3、通过来降低来连续领域的探索困难程度; 4、用了一些具有基本的和任务特点的信息的,这样可以加速和稳定多阶段任务中的移动视觉策略; 5、增加来增强泛化性能; 6、在动态系统的重大变化、对象外观任务长度等表现得较好。
The set of tasks includes multi-stage and long-horizon tasks, and they require full 9-DoF joint velocity control directly from pixels. 任务集合包括多阶段和长期的任务。 他们都需要全9自由度的来自像素信息的关节速度控制
Our approach utilizes demonstration data in two ways: first, it uses a hybrid reward that combines the task reward with an imitation reward based on Generative Adversarial Imitation Learning [15]. This aids with exploration while still allowing the final controller to outperform the human demonstrator on the task. Second, it uses demonstration trajectories to construct a curriculum of states along which to initialize the episodes during training. This enables the agent to learn about later stages of the task earlier in training, facilitating the solving of long tasks. 在两个方面使用演示数据: 1、这个模型使用了混合的奖励。一个是,一个是的奖励。这样有助于让控制器既能探索,又能做的比人演示的好。
[15] Jonathan Ho and Stefano Ermon. Generative adversarial imitation learning. In NIPS, pages 4565–4573, 2016.
2、另外一个是使用演示的轨迹来构建一个课程,在课程中进行每个回合的初始化过程。论文认为,这样的课程有助于让智能体提前学习后续的内容,强化解决任务的能力。
Through the use of a physics engine and high-throughput RL algorithms, we can simulate parallel copies of a robot arm to perform millions of complex physical interactions in a contact-rich environment while eliminating the practical concerns of robot safety and system reset. 通过使用一个物理引擎和高性能的强化学习算法 可以并行地训练许多次机械臂 避免机器人安全问题和系统重置带来的问题
Furthermore, we can, during training, exploit privileged and task-specific information about the true system state with several new techniques, including learning policy and value in separate modalities, an object-centric GAIL discriminator, and auxiliary tasks for visual modules. 新技术包括: 1、用学习策略和价值 2、一个以的鉴别器 3、为设计辅助任务
We use the same model and the same algorithm with only small task-specific modifications of the training setup to learn visuomotor controllers for six diverse robot arm manipulation tasks. 我们使用相同的模型和相同的算法,只对训练设置进行了小的特定任务的修改,以学习六种不同的机器人手臂操作任务的视觉运动控制器。
Related Work
Three classes of RL algorithms are currently dominant for continuous control problems: guided policy search methods (GPS; Levine and Koltun [22]), value-based methods such as the deterministic policy gradient (DPG; Silver et al. [45], Lillicrap et al. [26], Heess et al. [12]) or the normalized advantage function (NAF; Gu et al. [10]) algorithm, and trust-region based policy gradient algorithms such as trust region policy optimization (TRPO [42]) and proximal policy optimization (PPO [43]). 在连续环境主流的三种强化学习算法类: 1、——“引导性策略搜索模型”
[22] Sergey Levine and Vladlen Koltun. Guided policy search. In ICML, pages 1–9, 2013.
2、基于价值的方法 ——确定性策略梯度
[45] David Silver, Guy Lever, Nicolas Heess, Thomas Degris, Daan Wierstra, and Martin Riedmiller. Deterministic policy gradient algorithms. In ICML, 2014.
[26] Timothy P Lillicrap, Jonathan J Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. Continuous control with deep reinforcement learning. ICLR, 2016.
Nicolas Heess, Gregory Wayne, David Silver, Tim Lillicrap, Tom Erez, and Yuval Tassa. Learning continuous control policies by stochastic value gradients. In NIPS, pages 2926–2934, 2015.
3、基于置信区的策略梯度算法 ——标准优势函数算法;
[10] Shixiang Gu, Tim Lillicrap, Ilya Sutskever, and Sergey Levine. Continuous deep Q-learning with model-based acceleration. In ICML, 2016.
——置信区策略最优;
[42] John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimization. In ICML, pages 1889–1897, 2015.
——近似策略最优;
[43] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
TRPO [42] and PPO [43] hold appeal due to their robustness to hyperparameter settings as well as their scalability [14] but the lack of sample efficiency makes them unsuitable for training directly on robotics hardware. TRPO和PPO具有较高的吸引力是因为他们的超参数的设定具有鲁棒性以及他们具有可测量性;但是采样有效性比较少(【思考】可能是数据不能充分训练?)使得他们不能直接训练硬件机器人。
The idea of using large-scale data collection for training visuomotor controllers has been the focus of Levine et al. [24] and Pinto and Gupta [33] who train a convolutional network to predict grasp success for diverse sets of objects using a large dataset with 10s or 100s of thousands of grasp attempts collected from multiple robots in a self-supervised setting. 用大规模数据收集来训练移动视觉控制器的想法: 训练一个CNN,用来预测抓取的成功; 采用的是多个机器人在自监督设置下生成的10秒或者100秒的大量抓取试图数据集;
Demonstrations can be used to initialize policies, design cost functions, guide exploration, augment the training data, or a combination of these. 演示数据可以被用来初始化策略、设计损失函数、引导探索和增加训练数据,甚至是这些的结合体
Our method learns end-to-end visuomotor policies without reliance on demonstrator actions. 我们的方法是学习端到端的移动视觉策略,这个移动视觉策略不需要依赖演示者的行为动作。因此不同演示者操作也可以。
Model
The policy takes both an RGB camera observation and a proprioceptive feature vector that describes the joint positions and angular velocities. 一个RGB相机的观测 一个机器人关节信息的向量 采用这样的原因在与实体机器人也这样做,因此不需要进行额外的信息转变
图像经过CNN处理,主观触觉经过MLP处理 提取之后的信息连接好后,传入LSTM模型
A. Background: GAIL and PPO
启发式学习(Imitation Learning):
1. 行为克隆(Behavior Cloning)
假设:人类的演示是一种动作状态对的数据集。 D = { s i , a i } , i = 1 , 2 , 3 ⋯ N D=\lbrace s_{i},a_{i} \rbrace,i=1,2,3 \cdots N D={ si,ai},i=1,2,3⋯N 行为克隆算法是将人类演示的数据集做监督学习问题。 这个算法使用最大似然估计来训练一个参数化的策略 π \pi π。 π θ : S → A \pi_{\theta}:S \rightarrow A πθ:S→A 那么这样的话,最优参数表示如下: θ ∗ = a r g m a x θ ∑ N l o g θ π ( a i ∣ s i ) \theta^{*}=argmax_{\theta} \sum_{N}log_{\theta} \pi(a_{i}|s_{i}) θ∗=argmaxθN∑logθπ(ai∣si) 行为克隆在数据集充分的情况下好用 但是,机器人数据集的收集耗时耗力,因此需要较少量的数据集实现学习
2. GAIL方法
既使用了演示的数据 有允许智能体学习从环境中交互的经验 GAIL使用两个网络: 一个是策略网络: π θ : S → A \pi_{\theta}:S \rightarrow A πθ:S→A 一个是鉴别网络: D ψ : S × A → [ 0 , 1 ] D_{\psi}:S\times A \rightarrow [0,1] Dψ:S×A→[0,1] 使用最大值-最小值目标函数: max θ min ψ E π E [ l o g D ψ ( s , a ) ] + E π θ [ l o g ( 1 − D ψ ( s , a ) ) ] \operatorname{max}_\theta \operatorname{min}_\psi E_{\pi_{E}}[logD_{\psi}(s,a)] + E_{\pi_{\theta}}[log(1-D_{\psi}(s,a))] maxθminψEπE[logDψ(s,a)]+Eπθ[log(1−Dψ(s,a))] π E \pi_{E} πE指的是演示轨迹生成的专家的策略; 目标函数的目标是尽可能让智能体的策略尽可能与专家的策略一致 训练 π θ \pi_{\theta} πθ的方法:用策略梯度的方法最大化一个奖励函数 r g a i l = − l o g ( 1 − D ψ ( s t , a t ) ) r_{gail}=-log(1-D_{\psi}(s_{t},a_{t})) rgail=−log(1−Dψ(st,at)),使用限幅函数限制在最大值是10 GAIL通常是和TRPO结合起来使用 3. TRPO和PPO PPO only relies on first-order gradients and can be easily implemented with recurrent networks in a distributed setting [14]. PPO只需要一阶梯度,可以很简单的在循环神经网络中进行运用
PPO implements an approximate trust region that limits the change in the policy per iteration. PPO采用近似置信区来限制每次迭代的策略的改变
This is achieved via a regularization term based on the Kullback-Leibler (KL) divergence, the strength of which is adjusted dynamically depending on actual change in the policy in past iterations. 这个通过一个基于KL散度的正则化项,这个正则化项依靠在过去策略的迭代中实际的改变来动态的调整
B. Reinforcement and Imitation Learning Model
1.Hybrid IL/RL Reward
Hence, we design the task rewards as sparse piecewise constant functions based on the different stages of the respective tasks. 根据任务的不同阶段,设置分段的常值奖励函数 奖励值的变换,只在任务从一个状态像另一个状态的改变
we provide additional guidance via a hybrid reward function that combines the imitation reward r g a i l r_{gail} rgail with the task reward r t a s k r_{task} rtask. 在任务中增加了混合的奖励函数 结合了启发奖励和任务的奖励 r ( s t , a t ) = λ r g a i l ( s t , a t ) + ( 1 − λ ) r t a s k ( s t , a t ) , λ ∈ [ 0 , 1 ] r(s_{t},a_{t})=\lambda r_{gail}(s_{t},a_{t})+(1-\lambda)r_{task}(s_{t},a_{t}),\lambda \in [0,1] r(st,at)=λrgail(st,at)+(1−λ)rtask(st,at),λ∈[0,1] where the imitation reward encourages the policy to generate trajectories closer to demonstration trajectories, and the task reward encourages the policy to achieve high returns on the task. 启发式奖励——鼓励生成的策略轨迹更接近于人的演示轨迹 任务式奖励——鼓励策略获得更多的回报
设置奖励函数的结果——获得的成绩比单强化学习/单启发式学习都要好
2.Leveraging Physical States in Simulation
The physics simulator we employ for training exposes the full state of the system. 用系统的全状态进行物理仿真
(1) Demonstration as a curriculum.
Previous work indicates that shaping the distribution of start states towards states where the optimal policy tends to visit can greatly improve policy learning [18, 35]. 先前的工作指出:对开始状态到最优策略即将达到的状态之间进行塑造可以很大程度提升策略学习 从演示实验中获得开始状态的分布 对于不同的任务,分成不同个curriculums 初始状态选择策略: ϵ \epsilon ϵ:在环境中随机选取状态 1 − ϵ 1-\epsilon 1−ϵ:在环境中选取演示起点的状态
(2) Learning value functions from states
During training, each PPO worker executes the policy for K steps and uses the discounted sum of rewards and the value as an advantage function estimator A t ∧ = ∑ i = 1 K γ i − 1 r t + i + γ K − 1 V ϕ ( s t + K ) − V ϕ ( s t ) \stackrel{\wedge}{A_{t}} = \sum_{i=1}^{K} \gamma^{i-1}r_{t+i} + \gamma^{K-1} V_{\phi}(s_{t+K}) -V_{\phi}(s_{t}) At∧=i=1∑Kγi−1rt+i+γK−1Vϕ(st+K)−V