文章目录
-
- 可执行代码操作结果
- cv::imread
- cv::namedWindow
- cv::imshow & cv::waitKey
- cv::Mat rows & cols
- cv::Mat type
- cv::Mat depth()
- cv::Mat elemSize() & elemSize1()
- cv::Mat step & step1()
- cv::Scalar
- CV_8UC4
- .at 单通道图像像素遍历
- .ptr 单通道图像像素遍历
- .at 三通道图像像素遍历
- .ptr 单通道图像像素遍历
- 小孔成像的原理
- 图像采集卡
- 线阵相机
- 面阵相机
- CCD 与CMOS 图像传感器
- yuyv和mjpeg视频编码格式
- uvc_cam和usb_cam
- 模拟图像,数字图像,OpenCV表示图像
- 焦距
- 光心
- 基线
- ORB_SLAM2中基线的用法
- ORB_SLAM使用中光心
- 三个通道
- ORB_SLAM里面的用法
- 图像直方图
- 频率
- 滤波器
- 图像的滤波
- 算法是高斯平滑和高斯模糊
- 高斯模糊算法
- 离散傅里叶转换和仿射转换Affine Transformation应用和原理图像处理
- 傅里叶离散变换
- 仿射变换(Affine Transformation)原理及应用
可执行代码操作结果
cv::imread
image = cv::imread("../x.png", -1); 1 = IMREAD_COLOR 默认参数 将图像转换成3通道BGR彩图加载彩图 0 = IMREAD_GRAYSCALE 将图像转换为单通道灰度图像后读取 -1 = IMREAD_UNCHANGED 按图像原样读取 保留第4通道Alpha通道 cv::namedWindow
cv::namedWindow( "name", cv::WINDOW_AUTOSIZE); WINDOW_NORMAL 显示图像后,允许用户随意调整图像窗口大小 WINDOW_AUTOSIZE 不允许用户根据图像大小调整图像大小 cv::imshow & cv::waitKey
imshow( "winname", mat); winname 显示图像窗口的名称,并以字符串的形式赋值 mat 图像矩阵需要显示 cv::waitKey(0); 等待任何按钮退出,不加这句话,窗口会一闪而过,等待6000 ms后窗自动关闭 waitKey(6000); cv::Mat rows & cols
矩阵行数/高为image.rows 矩阵列数/宽为image.cols cv::Mat type
type表示矩阵中元素的类型和矩阵通道的数量 常量是一系列的预定义 命名规则为CV_(位数) (/span>数据类型)+(通道数) U表示Unsigned无符号整数类型, 即其内部元素的值不可以为负数 S表示Signed有符号整数类型, 其值存在负数 F则表示浮点数类型,即矩阵的内部元素值可以为小数(32对应单精度float类型, 64对应双精度double类型) CV_8U -> uchar CV_8S -> char CV_16S -> short CV_16U -> ushort CV_32S -> int CV_32F -> float CV_64F -> double CV_8UC3 = 16 CV_16UC3 = 18 C1-C4表示对应的通道数,即有1-4个通道 CV_8UC1---可以创建---8位无符号的单通道---灰度图片---grayImg #define CV_8UC1 CV_MAKETYPE(CV_8U,1) type 预定义的常量 = 0 CV_8UC3---可以创建---8位无符号的三通道---RGB彩色图像---colorImg #define CV_8UC3 CV_MAKETYPE(CV_8U,3) type 预定义的常量 = 16 CV_8UC4---可以创建---8位无符号的四通道---带透明色Alpha通道的RGB图像 #define CV_8UC4 CV_MAKETYPE(CV_8U,4) type 预定义的常量 = 24 cv::Mat depth()
Mat.depth()得到的是一个0-6的数字,分别代表不同的位数, 0和1都代表8位, 2和3都代表16位, 4和5代表32位, 6代表64位
enum{
CV_8U=0, CV_8S=1, CV_16U=2, CV_16S=3, CV_32S=4, CV_32F=5, CV_64F=6}
cv::Mat elemSize() & elemSize1()
矩阵中像素的个数为image.rows*image.cols
elemSize以8位(一个字节)为单位表示矩阵中每一个像素的字节数
以字节为单位的有效长度的step为eleSize()*cols=48
CV_8UC1, elemSize==1字节
CV_8UC3或CV_8SC3, elemSize==3字节
CV_16UC3或CV_16SC3, elemSize==6字节
单个通道下每个元素的字节数
elemSize加上一个"1"构成了elemSize1这个属性,可认为是元素内1个通道的意思,
表示Mat矩阵中每一个元素单个通道的数据大小, 以字节为单位, eleSize1==elemSize/channels
cv::Mat step & step1()
以字节为单位, step为Mat矩阵中一行像素占用多少个字节, step=elemSize()*cols
step1()以字节为基本单位, Mat矩阵中每一个像素的大小, 累计了所有通道的elemSize1之后的值, 所以有step1==step/elemSize1
cv::Scalar
cv::Scalar(0,0,255)每个像素由三个元素组成即三通道,初始化颜色值为(0,0,255)
CV_8UC4
typedef Vec <uchar, 3> Vec3b
vec3b 表示每个Vec3b对象可以存储3个char(字符型)数据, 比如可以用这样的对象,去存储RGB图像中的
vec4b 表示每个Vec4b对象可以存储4个字符型数据, 可以用这样的类对象去存储4通道RGB+Alpha的图
mat.at<cv::Vec4b>(i, j);
从mat中取出一个像素,像素的类型是Vec4b该类型含义是, 有4个uchar类型的元素
其中rgba[0], rgba[1], rgba[2]代表像素三原色BGR, 即为蓝色Blue, Green绿色, 红色Red, rgba[3]代表像素的Alpha值表示像素透明度
.at 遍历单通道图像像素
行优先
y=ROWS=height
x=COLS=width
通过at方法读取元素需要在后面跟上<数据类型>以坐标的形式给出需要读取的元素坐标(行数,列数)
.at<uchar>(y, x)
.at<double>(y, x)
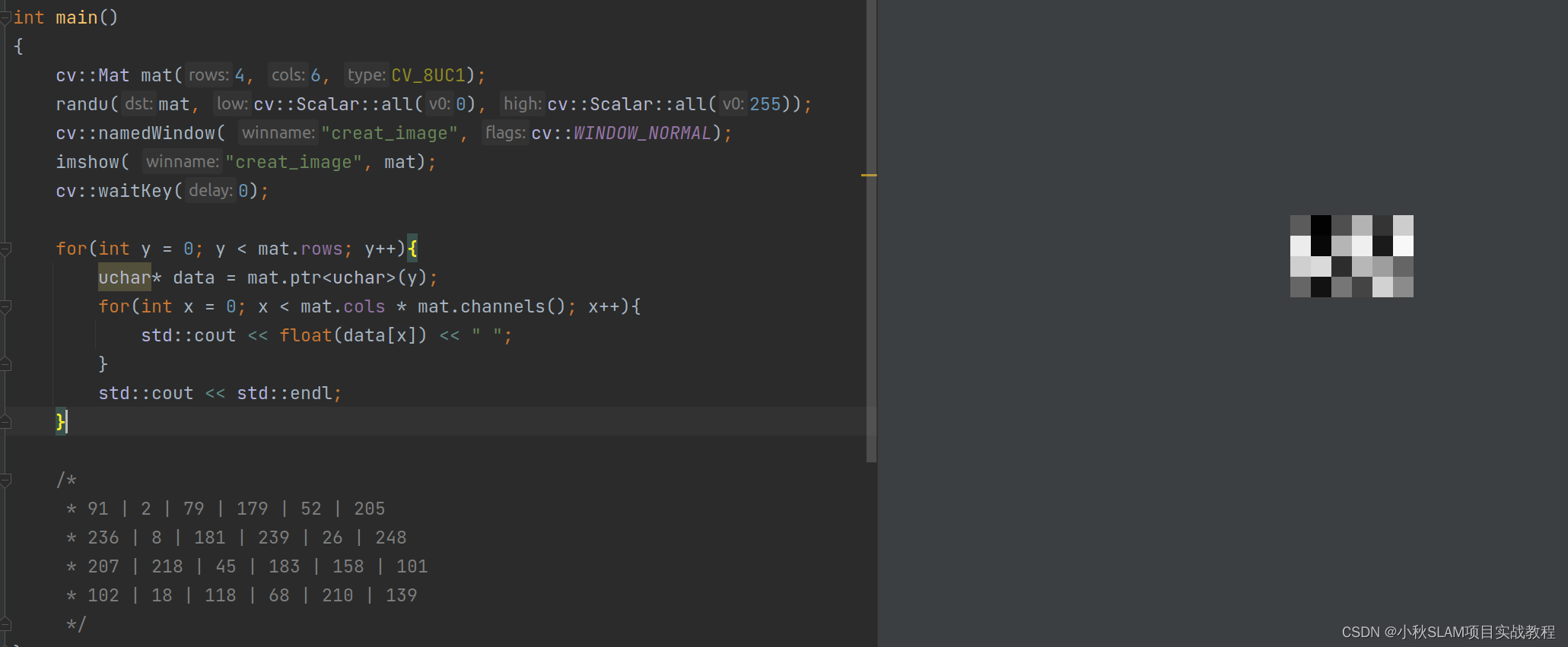
.ptr 遍历单通道图像像素
for(int i = 0; i < image_gray.rows; i++){
uchar* data = image_gray.ptr<uchar>(i);
for(int j = 0; j < image_gray.cols * image_gray.channels(); j++){
std::cout << float(data[j]) << " ";
}
}
float grayscale = float (image_gray.ptr<uchar> ( cvRound ( kp.pt.y ) ) [ cvRound ( kp.pt.x ) ] );
.at 遍历三通道图像像素
OpenCV中定义cv::Vec3b, cv::Vec3s, cv::Vec3w, cv::Vec3d, cv::Vec3f, cv::Vec3i 六种类型表示同一个元素的三个通道数据
数字表示通道的个数, 最后一位是数据类型的缩写, b是uchar类型的缩写, s是short类型的缩写, w是ushort类型的缩写, d是double类型的缩写, f是float类型的缩写, i是int类型的缩写
Vec3b描述RGB颜色
cv::Vec3b color;
color[0]=0;//B分量
color[1]=0;//G分量
color[2]=255;//R分量
for(int y = 0; y < mat.rows; y++){
for(int x = 0; x < mat.cols; x++){
std::cout << "mat.at<cv::Vec3b>(y,x)[0]: " << int(mat.at<cv::Vec3b>(y,x)[0]) << std::endl; //获得蓝色通道b的像素值
std::cout << "mat.at<cv::Vec3b>(y,x)[0]: " << int(mat.at<cv::Vec3b>(y,x)[1]) << std::endl; //获得绿色通道g的像素值
std::cout << "mat.at<cv::Vec3b>(y,x)[0]: " << int(mat.at<cv::Vec3b>(y,x)[2]) << std::endl; //获得红色通道r的像素值
}
}
for(int y = 0; y < image_rgb.rows; y++){
uchar* data = image_rgb.ptr<uchar>(y);
for(int x = 0; x < image_rgb.cols * image_rgb.channels(); x++){
std::cout << float(data[x]) << " " ;
}
std::cout << std::endl;
}
.ptr 遍历单通道图像像素
for (int y = 0; y < mat.rows; y++){
uchar* row_ptr = mat.ptr(y);// 定义一个uchar类型的row_ptr指向图像行的头指针
for (int x = 0; x < mat.cols*mat.channels(); x++){
// 遍历图像每一行所有通道的数据 Mat类矩阵矩阵中每一行中的每个元素都是挨着存放, 每一行中存储的数据数量为列数与通道数的乘积 即代码中指针向后移动cols*channels()-1位
std::cout << "row_ptr[" << x << "]: " << (int)row_ptr[x] << std::endl;
}
}
小孔成像的原理
用一个带有小孔的板遮挡在墙体与物之间,墙体上就会形成物的倒影,我们把这样的现象叫小孔成像。 前后移动中间的板,墙体上像的大小也会随之发生变化这种现象说明了光沿直线传播的性质。现在的一些照相机和摄影机就是利用了小孔成像的原理。 镜头是小孔,景物通过小孔进入暗室留在胶片上。镜头是小孔大多数安装凸透镜以保证光线成像距离,景物通过小孔进入暗室,像被一些特殊的化学物质如显影剂等留在胶片上数码相机、摄影机等则是把像通过一些感光元件存储在存储卡内。
图像采集卡
图像采集卡功能是将图像信号采集到电脑中,以数据文件的形式保存在硬盘上。它是我们进行图像处理必不可少的硬件设备,通过它我们就可以把摄像机拍摄的视频信号从摄像带上转存到计算机中。
图像采集卡是图像采集部分和图像处理部分的接口。图象经过采样、量化以后转换为数字图象并输入、存储到帧存储器的过程,叫做采集,图像采集卡还提供数字I/O的功能。
-
图像传输格式 格式是视频编辑最重要的一种参数,图像采集卡需要支持系统中摄像机所采用的输出信号格式。大多数摄像机采用RS422或EIA644(LVDS)作为输出信号格式。在数字相机中,IEEE1394,USB2.0和CameraLink几种图像传输形式则得到了广泛应用。
-
图像格式 黑白图像:通常情况下,图像灰度等级可分为256级,即以8位表示。在对图像灰度有更精确要求时,可用10位,12位等来表示。 彩色图像:彩色图像可由RGB(YUV)3种色彩组合而成,根据其亮度级别的不同有8-8-8,10-10-10等格式。
-
传输通道数 当摄像机以较高速率拍摄高分辨率图像时,会产生很高的输出速率,这一般需要多路信号同时输出,图像采集卡应能支持多路输入。 一般情况下,有1路,2路,4路,8路输入等。随出现着科技的不断发展和行业的不断需求,路数更多的采集卡也出现在市面上。
-
分辨率 采集卡能支持的最大点阵反映了其分辨率的性能。一般采集卡能支持768576点阵,而性能优异的采集卡其支持的最大点阵可达64K64K。单行最大点数和单帧最大行数也可反映采集卡的分辨率性能。同三维推出的采集卡能达到1920x1080分辨率。
-
采样频率 采样频率反映了采集卡处理图像的速度和能力。在进行高度图像采集时,需要注意采集卡的采样频率是否满足要求。高档的采集卡其采样频率可达65MHZ。
-
传输速率 主流图像采集卡与主板间都采用PCI接口,其理论传输速度为132MB/S。 采集,视频/图象经过采样、量化以后转换为数字图象并输入、存储到帧存储器的过程。由于图像信号的传输需要很高的传输速度,通用的传输接口不能满足要求,因此需要图像采集卡。
- 视野(FOV)或现场是相机及光学系统“看”到的真实世界的具体部分。
- CCD芯片将光能转化为电能。
- 相机将此信息以模拟信号的格式输出至图像采集卡。
- AD –转换器将模拟信号转换成 8 位(或多位)的数字信号。每个象素独立地把光强以灰度值(Gray level)的形式表达。
- 这些光强值从CCD芯片的矩阵中被存储在内存的矩阵数据结构中。
- 帧图像大小(Image Size):W×H(长×宽)
- 颜色深度∶d(比特数)—希望采集到的图象颜色(8Bit灰度图象还是16/24/32Bit真彩色)
- 帧 速∶f—标准PAL制就是25帧。
- 数 据 量∶Q(MB)
- 采 样 率∶A(MB)
- 计算公式∶ Q=W×H×f×d/8
- 判断标准∶如果A>Q×1.2,则该采集卡能够胜任采集工作。
线阵相机
线阵CCD工业相机主要应用于工业、医疗、科研与安全领域的图象处理。在机器视觉领域中,线阵工业相机是一类特殊的视觉机器。与面阵工业相机相比,它的传感器只有一行感光元素,因此使高扫描频率和高分辨率成为可能。线阵工业相机的典型应用领域是检测连续的材料,例如金属、塑料、纸和纤维等。被检测的物体通常匀速运动,利用一台或多台工业相机对其逐行连续扫描,以达到对其整个表面均匀检测。可以对其图象一行一行进行处理,或者对由多行组成的面阵图象进行处理。另外线阵工业相机非常适合测量场合,这要归功于传感器的高分辨率,它可以准确测量到微米。
-
线阵工业相机,机顾名思义是呈“线”状的。虽然也是二维图象,但极长,几K的长度,而宽度却只有几个象素的而已。一般上只在两种情况下使用这种相机:一、被测视野为细长的带状,多用于滚筒上检测的问题。二、需要极大的视野或极高的精度。
-
需要极大的视野或极高的精度的情况下,需要用激发装置多次激发相机,进行多次拍照,再将所拍下的多幅“条”形图象,合并成一张巨大的图。因此,用线阵型工业相机,必须用可以支持线阵型工业相机的采集卡。线阵型工业相机价格贵,而且在大的视野或高的精度检测情况下,其检测速度也慢--一般工业相机的图象是400K~1M,而合并后的图象有几个M这么大,速度自然就慢了。
面阵相机
相机像素是指这个相机总共有多少个感光晶片,通常用万个为单位表示,以矩阵排列,例如3百万像素、2百万像素、百万像素、40万像素。百万像素工业相机的像素矩阵为WH=10001000。
工业相机分辨率,指一个像素表示实际物体的大小,um*um表示。数值越小,分辨率越高 。
FOV是指相机实际拍摄的面积,以毫米×毫米表示。FOV是由像素多少和分辨率决定的。相同的相机,分辨率越大,它的FOV就越小。例如1K1K的相机,分辨率为20um,则他的FOV=1K20×1k20=20mm×20mm,如果用30um的分辨率,他 FOV=1K30×1k*30=30mm×30mm。
在图像中,表现图像细节不是由像素多少决定的,而是由分辨率决定的。分辨率是由选择的镜头焦距决定的,同一种相机,选用不同焦距的镜头,分辨率就不同。如果采用20um分辨率,对于1mm*0.5mm的零件,它总共占用像素1/0.02×0.5/0.02=50×25个像素,如果采用30um的分辨率,表示同一个元件,则有1/0.03×0.5/0.03=33×17个像素,显然20um的分辨率表现图像细节方面好过30um的分辨率。
既然像素的多少不决定图像的分辨率(清晰度),那么大像素工业相机有何好处呢?答案只有一个:减少拍摄次数,提高测试速度。
1个是1百万像素,另1个是3百万像素,清晰度相同(分辨率均为20um),第1个相机的FOV是20mm×20mm=400平方mm,第二个相机的FOV是1200平方mm,拍摄同一个PCB,假设第1个相机要拍摄30个图像,第2个相机则只需拍摄10个图像就可以了。
对于面阵CCD来说,应用面较广,如面积、形状、尺寸、位置,甚至温度等的测量。面阵CCD的优点是可以获取二维图像信息,测量图像直观。缺点是像元总数多,而每行的像元数一般较线阵少,帧幅率受到限制,而线阵CCD的优点是一维像元数可以做得很多,而总像元数角较面阵CCD工业相机少,而且像元尺寸比较灵活,帧幅数高,特别适用于一维动态目标的测量。以线阵CCD在线测量线径为例,就在不少论文中有所介绍,但在涉及到图像处理时都是基于理想的条件下,而从实际工程应用的角度来讲,线阵CCD图像处理算法还是相当复杂的。
由于生产技术的制约,单个面阵CCD的面积很难达到一般工业测量对视场的需求。线阵CCD的优点是分辨力高,价格低廉,如TCD1501C型线阵CCD,光敏像元数目为5000,像元尺寸为7μm×7μm×7μm(相邻像元中心距)该线阵CCD一维成像长度35mm,可满足大多数测量视场的要求,但要用线阵CCD获取二维图像,必须配以扫描运动,而且为了能确定图像每一像素点在被测件上的对应位置,还必须配以光栅等器件以记录线阵CCD每一扫描行的坐标。一般看来,这两方面的要求导致用线阵CCD获取图像有以下不足:图像获取时间长,测量效率低;由于扫描运动及相应的位置反馈环节的存在,增加了系统复杂性和成本;图像精度可能受扫描运动精度的影响而降低,最终影响测量精度。
CCD 与CMOS 图像传感器
CCD 与CMOS 图像传感器光电转换的原理相同
CMOS:响应快,功耗低,噪点高,不均匀,画质受噪声影响多,ISO较小 CCD:响应慢,功耗高,噪点低,均匀,画质高,ISO较高
随着CMOS图像传感器的技术日趋进步,同时具有成像速度快,功耗少,成本低的优势,所以现在市面上的工业相机大部分使用的都是CMOS的图像传感器。
yuyv和mjpeg视频编码格式
免驱摄像头一般有两种传输格式,YUY2和MJPG,前者是无压缩图像格式的视频,系统资源占用少(因为不用解码),不需要解码器,缺点是帧率稍慢(受限于USB分配的带宽),后者是相当于JPEG图像压缩格式,优点是帧率高(视频开启快,曝光快),缺点是影像有马赛克,并且需要解码器,会占用PC系统资源。
uvc_cam和usb_cam
https://github.com/ericperko/uvc_cam
sudo apt-get install ros-kinetic-uvc-camera
rosrun uvc_camera uvc_camera_node
rviz
uvc-camera图像采集视频像素格式是mjpeg usb_cam图像采集默认视频像素格式是mjpeg 笔记本自带摄像头图像采集视频像素格式是yuyv
https://github.com/ros-drivers/usb_cam
sudo apt-get install ros-kinetic-usb-cam
插入摄像头判断设备
cd /dev &&find . -name "video*"
roslaunch usb_cam usb_cam-test.launch
模拟图像、数字图像、OpenCV表示图像
OpenCV 基于 C 语言接口而建,采用名为 IplImage 的C语言结构体在内存(memory)中存放图像, IplImage 和 CvMat 都是 C 语言的结构,IplImage 由 cvMat 派生,cvMat 由 CvArr 派生。使用这两个结构的问题是内存需要手动管理,开发者必须清楚的知道何时需要申请内存,何时需要释放内存。新版本 OpenCV 中引入 Mat 类能够自动管理内存。
Mat 是一个类,由两个数据部分组成:matrix header 矩阵头(包含矩阵尺寸,存储方法,存储地址等信息)和一个指向存储所有像素值的矩阵(根据所选存储方法的不同矩阵可以是不同的维数)的指针。矩阵头的尺寸是常数值,但矩阵本身的尺寸会依图像的不同而不同,通常比矩阵头的尺寸大数个数量级。因此,当在程序中传递图像并创建拷贝时,大的开销是由矩阵造成的,而不是信息头。 需要注意的是, copy 这样的操作只是 copy 了矩阵的 matrix header 和那个指针,而不是矩阵的本身,也就意味着两个矩阵的数据指针指向的是同一个地址,需要开发者格外注意。 如果想建立互不影响的Mat,是真正的复制操作,需要使用函数 clone() 或者 copyTo() 。Mat是一个多维的密集数据数组,可以用来处理向量和矩阵、图像、直方图等等常见的多维数据。OpenCV 访问图像中的像素需要先行,后列,先 Y 轴后 X 轴。
opencv中Mat的数据定义为指向uchar 的指针,而构造函数又提供了许多其他类型。
其实数据在内存中是一维存储的,而图像基本结构是二维的,3D图像还会是三维的;同时彩色图像还有多个channel(通道);为了便于编程使用,opencv对一维数据进行矩阵的抽象封装,这个就是Mat类;Mat是一个基础类,封装了构造函数,重载运算符和基础的运算函数(很多类似于matlab的函数);Mat_ 类就是利用模板类型继承于Mat,所以opencv是有模板类型的就是Mat_ 。不管是什么类型Mat类中的data成员是一个 unsigned char *,指向数据的第一个字节(同时还定义了datastart,dataend等,参看源代码),当你使用高级类型getMat().data函数获得该对象的数据时,可以通过强制转换访问来获得你的数据类型比如我想看float类型图像的第[3,5]像素点的值,可以:((float )data)[5width+3]来访问,这样的访问比较原始。一般opencv core里面提供的算法是输入是InputArray和OutputArray;这两个和Mat有很大的关系,void * 就是指向Mat对象,同时加入了一些flag来判断Mat的类型比如是不是img等。
通过一定的速率对图像进行周期性的扫描,把图像上不同亮度的点变成不同大小的电信号,然后传送出去的方法就是图像模拟传输。模拟图像是通过某种物理量的强弱变化来表现图像上各点的颜色 信息,画稿、电视上的图像、相片、印刷品图像都是模拟图像。
对于一幅图像,我们可以将其放入坐标系中,这里取图像左上定点为坐标原点,x 轴向右,和笛卡尔坐标系x轴相同;y 轴向下,和笛卡尔坐标系y轴相反。这样我们可将一幅图像定义为一个二维函数 f(x,y),图像中的每个像素就可以用 (x,y) 坐标表示,而在任何一对空间坐标 (x,y) 处的幅值 f 称为图像在该点的强度或灰度,当 x,y 和灰度值 f 是有限离散数值时,便称该图像为数字图像。
当图片尺寸以为单位时,每一厘米等于28像素,比如1515厘米长度的图片,等于420420像素的长度。 一个像素所能表达的不同颜色数取决于比特每像素(BPP)。 灰度图像:8bpp=2的8次方=256色, 高彩色:16bpp=2的16次方=65536色,真彩色:24bpps=2的24次方=16777216色。
或强度值是由入射分量和反射分量决定的,入射分量i(x,y) 的性质取决于照射源,而反射分量r(x, y) 的性质取决于成像物体的特性,对于不同的照射源和成像物体则会有不同的取值。
图像总像素的多少,称为图像分辨率,由于图像通常用矩阵表示,所以分辨率常用,mn表示,注意:n表示行数(代表一列包含的像素),m表示列数(代表一行包含的像素)。如640480,表示图像的长和宽分别为640和480,总像素为640480=307200(相机中所说的30万分辨率),800600,表示图像的长和宽分别为800和600,总像素为800*600=480000(相机中所说的50万分辨率)。
数字图像f(x,y)主要有三种表示方式 ● 画为三维表面图像,如下图(a) ● 可视化灰度阵列图像,如下图(b) ● 二维数值阵列图像,如下图(c )
通俗理解便是图像的明暗程度,数字图像 f(x,y) = i(x,y) r(x, y) ,如果灰度值在[0,255]之间,则 f 值越接近0亮度越低,f 值越接近255亮度越高。而且我们也要把亮度和对比度区分开来,正如上述提的对比度指的是最高和最低灰度级之间的灰度差。
光心在物理成像平面前方,成的像是倒立的所以为了计算方便,我们把物理成像平面移动到了光心的前面,物理成像平面在焦点所在的平面
焦距
focal lenth 焦距是指从镜片映射中心到可呈清晰像的像平面的距离。 焦距的大小决定着视角的大小,焦距数值小,视角大,所观察的范围也大;焦距数值大,视角小,观察范围小。根据焦距能否调节,可分为定焦镜头和变焦镜头两大类。焦距长度是指从透镜的光心到焦点的距离。
焦距,是光学系统中衡量光的聚集或发散的度量方式,指平行光入射时从透镜光心到光聚集之焦点的距离。亦是照相机中,从镜片中心到底片或CCD等成像平面的距离。
焦距是指镜头中心到焦点的距离,用凸透镜照太阳,会出现一个点,那个就是焦点,然后那个点到凸透镜的距离就是焦距,focal length 焦距,即焦长,是平行光入射时,从透镜光心到光线聚集之焦点的距离。在相机中,焦距是从镜片中心到底片或是CCD等成像平面的距离。 焦距越大,镜头角度越小。焦距越小,镜头角度越大。
光心
世界坐标系的原点是左摄像头凸透镜的光心。f和d的单位是像素,那这个像素到底表示什么,它与毫米之间又是怎样换算的? 这个问题也与针孔模型相关。在针孔模型中,光线穿过针孔(也就是凸透镜中心)在焦距处上成像,因此,图3的像平面就是摄像头的CCD传感器的表面。每个CCD传感器都有一定的尺寸,也有一定的分辨率,这个就确定了毫米与像素点之间的转换关系。举个例子,CCD的尺寸是8mm X 6mm,分辨率是640X480,那么毫米与像素点之间的转换关系就是80pixel/mm。
理解这里有助于理解ORB_SLAM2的代码。
基线
ORB_SLAM2中基线的用法
// Check first that baseline is not too short
// 邻接的关键帧光心在世界坐标系中的坐标
cv::Mat Ow2 = pKF2->GetCameraCenter();
// 基线向量,两个关键帧间的相机位移
cv::Mat vBaseline = Ow2-Ow1;
// 基线长度
const float baseline = cv::norm(vBaseline);
ORB_SLAM2中光心的用法
计算该地图点的法线方向,也就是朝向等信息。能观测到该地图点的所有关键帧,对该点的观测方向归一化为单位向量,然后进行求和得到该地图点的朝向,初始值为0向量,累加为归一化向量,最后除以总数n。
cv::Mat normal = cv::Mat::zeros(3,1,CV_32F);
int n=0;
for(map<KeyFrame*,size_t>::iterator mit=observations.begin(), mend=observations.end(); mit!=mend; mit++){
KeyFrame* pKF = mit->first;
cv::Mat Owi = pKF->GetCameraCenter();
cv::Mat normali = mWorldPos - Owi;
normal = normal + normali/cv::norm(normali);
n++;
}
我们看到的图像是显卡帮我们渲染的的,多通道的图像(Mat类矩阵表示)是一个类似于三维的数据结构,而计算机的存储空间是一个二维空间,因此(Mat类矩阵)在计算机存储时是将三维数据变成二维数据,先存储第一个元素每个通道的数据,之后再存储第二个元素每个通道的数据。每一行的元素都按照这种方式进行存储,因此如果我们找到了每个元素的起始位置,便可以找到这个元素中每个通道的数据。
OpenCV中以BGR形式存储的彩色图片,每一个小格子代表一个像素
将彩色图片拆分成三个颜色通道存储的形式 图片数据的存储形式
三个通道
图中红点的坐标是(2,1) 还是 (1,2)答案是(2,1)
(2,1)表示的是红点的坐标,就是红点的 x 坐标是 2, y 坐标是 1。 (1,2)表示的是红点的行和列,就是红点的行是1,列是2,也就是红点在第 1 行,第 2 列。
ORB_SLAM2里面的的用法
图像直方图
灰度直方图(histogram)是灰度级分布的函数,它表示图象中具有每种灰度级的象素的个数,反映图象中每种灰度出现的频率。灰度直方图的横坐标是灰度级,纵坐标是该灰度级出现的频率,是图象的最基本的统计特征。
生成图像灰度直方图的一般步骤 1、统计各个灰度值的像素个数; 2、根据统计表画出直方图
灰度直方图的性质 1、只反映该图像中不同灰度值出现的次数(或频率),而不能反映某一灰度值像素所在的位置; 2、任何一张图像能唯一地确定一个与它对应的直方图,而一个直方图可以有多个不同的图像; 3、如果一张图片被剪裁成多张图片,各个子图的直方图之和就是这个全图的直方图。
直方图的用途 直方图有很多的用途,比如阀值分割,图像增强,还常常用于医疗影像。帮助理解词袋模型。 在暗图像中,直方图的分布都集中在灰度级的低(暗)端; 亮图像直方图的分布集中在灰度级的高端;低对比度图像具有较窄的直方图,且都集中在灰度级的中部;而高对比度的图像直方图的分量覆盖了很宽的灰度范围,且像素分布也相对均匀,此时图片的效果也相对很不错。于是我们可以得出结论:若一幅图像的像素倾向于占据整个可能的灰度级并且分布均匀,则该图像有较高的对比度并且图像展示效果会相对好,于是便引出图像直方图均衡化,对图像会有很强的增强效果
为了产生一幅数字图像,我们需要把连续的感知数据转化为数字形式,便是:取样和量化。取样和量化目的便是为了将连续的感知数据离散化,而且图像的质量在很大程度上也取决于取样和量化中所用的样本数和灰度级,图像的采样是把空域上或时域上连续的图像(模拟图像)转换成离散采样点(像素)集合(数字图像)的操作。采样越细,像素越小,越能精细地表现图像。
量化是把像素的灰度(浓淡)变换成离散的整数