MG-BERT:利用无监督原子表征学习预测分子性质
MG-BERT: leveraging unsupervised atomic representation learning for molecular property prediction
本文的第一作者是张小琛博士和吴诚坤研究员。主要合作伙伴来自深厚的AIDD曹东生教授和侯廷军教授
摘要
动机:
准确有效地预测分子性质是药物设计和发现过程中的基本问题之一。传统的基于特征工程的方法需要在特征设计和选择过程中有丰富的专业知识。AI数据驱动驱动的发展,数据驱动方法在各个领域都表现出了基于特征工程的方法无与伦比的优势。现有的AI在预测分子性质时,用模型,
泛化能力一般来说,学习到的模型预测未知数据的能力。
结果:
本研究提出了 分子图BERT (MG-BERT)该模型将图神经网络(GNNs)将局部信息传输机制整合到强大中BERT从分子图中学习很方便。此外,还提出了一种有效的自我监督学习策略—掩模原子预测MG-BERT模型预训练在大量未标记的数据上挖掘分子中的上下文信息。我们发现MG-BERT预训练后,模型可以生成上下文相关的原子表示,并将所学知识转移到各种分子特性的预测中。实验结果表明,预训练MG-BERT在所有11个模型中,经过少量额外的微调ADMET数据集的性能总是优于目前最先进的方法。
图解摘要
关键词:分子性质预测;分子图 Bert ;原子说;深度学习;自我监督学习;
介绍
药物发现是一个高风险、耗时、资源密集的过程,通常需要10-15年和数十亿美元。为了提高药物发现的效率,人们为计算工具和生物信息学方法的发展付出了相当大的努力。在这些方法中,用于准确预测分子特性的计算模型对药物发现过程有更显著和直接的影响,因为它们可以减少对耗时和劳动密集型实验的过度依赖,大大降低支出和时间成本。在此背景下,高精度分子特性预测模型已成为药物发现过程中多个阶段不可缺少的工具,涵盖命中识别、先导优化ADMET(吸收、分布、代谢、排泄和毒性)特性评估等。
输入分子对预测分子性质至关重要。传统的方法在很大程度上依赖于特征工程,即专家制定一套规则,将分子的相关结构信息或物理化学属性编码成固定长度的向量。
分子指纹和分子描述符是两种典型的分子特征。
分子指纹
分子指纹主要用于记录分子亚结构的信息。例如,扩展连接指纹(ECFPs)在达到特定直径之前,为每个非氢原子指定一个初始特征,并迭代组合相邻原子的特征。
分子描述符
或者,描述符由专家根据其专业观点和特征工程实践选择的一系列物理和化学性质和结构信息组成。指纹通常不能优化特定的预测任务特定的预测任务。分子描述符可以减少不相关的特征,并在一定程度上提高性能。然而,设计过程琐碎、耗时,容易出错。
总结
因此,分子指纹和描述符的可扩展性和通用性都很低
近年来,深入学习(DL)计算机视觉等如计算机视觉(CV),自然语言处理(NLP)等,DL 背后的基本原则是设计一个合适的深度神经网络 (DNN) 并在大量原始数据原始数据训练,以自动学习,而不是依赖于手工设计的特点。
DL它在分子性质预测中的应用受到各个领域成功应用的启发。许多关于分子特性预测的研究都试图dnn直接应用于低水平分子表示,如序列SMILES字符串或分子图(简化分子输入线输入规范)。SMILES字符串通过一行ASCII字符串描述分子的组成和化学结构。作为一种文本,一些合适的文本处理算法,如CNN、LSTM和Transformer,可直接用于构建预测模型。然而,这些算法需要从复杂性中学习smile分子的有用特征在语法中的分析大大增加了学习和推广的难度。值得注意的是,基于自动编码器等模型的无监督方法已被应用于smile,从大量未标记的数据中学习有用的表示。这种模型通常包括两个神经网络:编码器和解码器。
编码器
编码器网络将输入序列(具有离散值的变长SMILES将序列转换为固定尺寸连续向量(潜在表示)。解码器网络将潜在表示作为输入,并将其转换为输入序列。这些模型可以在连续向量空间中嵌入大量未标记的数据。潜在表示可用于下游预测任务。
然而,基于SMILES恢复的分子表示对于一般预测任务可能不是最优的,不能进一步优化。新兴的GNNs可以直接从图数据中学习,这可能是分子性质预测的一大优势。
具体来说,GNNs首先,根据连接关系将分子表示为二维(2)D)或者根据原子距离矩阵将分子表示为三维(3)D)图。然后根据原子类型、价电子数、键数等原子特征将原子嵌入向量。之后,每个原子的向量通过收集周围原子的信息迭代更新。最后,通过特定的读出机制,将所有原子的向量生成图级向量,并发送到全连接神经网络进行预测。如有必要,原子键的信息也可以合并。然而,由于拟合和平滑问题的限制,目前GNNs通常太浅(通常是2) ~ 三层)削弱了其提取深层模式的能力。
DL模型在分子性质预测中面临的共同挑战是缺乏标记数据。众所周知,DL模型通常需要大量的标记数据来实现更高的有效性和通用性。例如,在图像分类任务中,人们通常会收集数百万张图像进行训练DL模型。不幸的是,获得如此多的分子特性数据是不现实的,尤其是ADMET端点数据通常需要大量耗时、费力和昂贵的实验。这种困境DL模型经常出现拟合,极大地损害了其泛化能力。
在其他领域,标签数据的稀缺性促进了自我监督或半监督学习方法的发展。新提出的自然语言处理领域BERT该模型可以使用大量未标记的文本进行预训练,大大提高了各种下游任务的性能。BERT模型的成功可以归因于对被屏蔽标记的预测,该模型学习根据同一句子中其他可见单词来预测被屏蔽或污染的单词。在此过程中,驱动模型挖掘句子中的上下文信息。这种上下文信息可以给下游任务带来好处,大大提高其预测性能。受BERT提出了模型的灵感smile -BERT模型,将BERT直接应用于模型SMILES字符串。尽管smile - BERT模型由于在smile字符串中有辅助字符,缺乏可解释性。此外,smile复杂的字符串语法也增加了模型学习的难度。
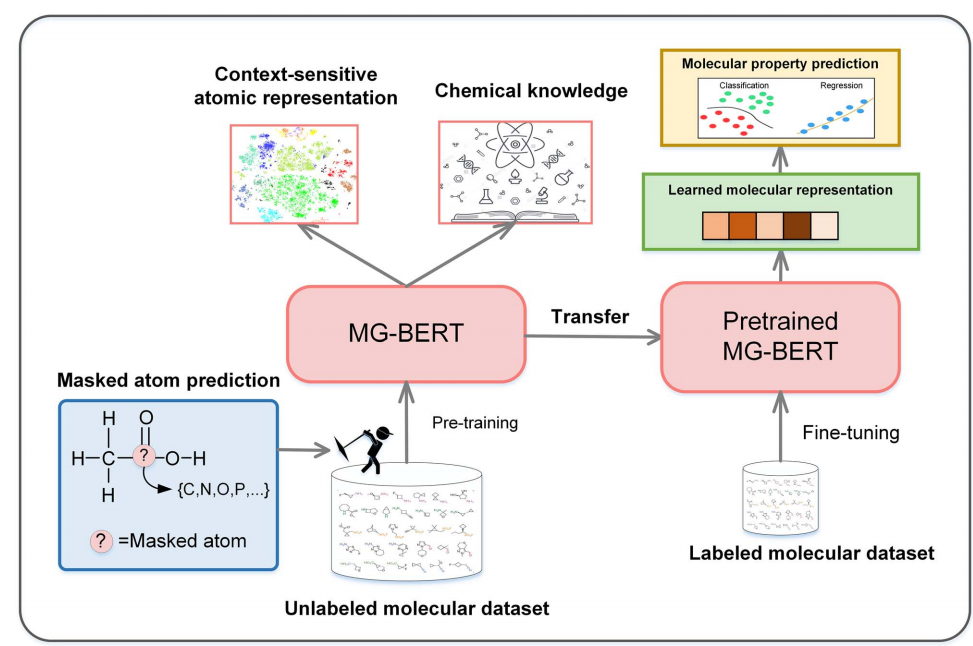
解决这些问题,我们提出了一种新的分子图BERT (MG-BERT)模型,将GNNs局部信息传输机制整合到强大中BERT模型中。所提出的MG-BERT模型可以克服普通GNNs为生成分子表示提供足够的深度特征提取能力。进一步提出了自动挖掘分子中上下文信息的有效策略。实验结果表明,MG-BERT该模型可以通过预训练生成上下文相关的原子,大大提高了11个实际任务的分子性质预测任务的性能MG-BERT模型的性能总是优于现有的先进模型。此外,MG-BERT也可以学习关注与目标性质相关的原子结构和原子结构,为分子的分析和优化提供有价值的线索。
方法
数据集集合
本文提出的MG-BERT模型的训练过程分为预训练和微调两个阶段。
在预训练阶段,需要使用大量未标记的分子来挖掘分子中的上下文信息。 ChEMBL在数据库中选择 170 一万种化合物作为预训练数据。为验证预训练模型,在实验中随机保留 10% 用于预训练评估。训练集中最终包括 153 万个数据。
在微调阶段,对预训练模型进行进一步训练,用于特定的分子特性预测。从 ADMETlab 和 MoleculeNet 收集16个数据集(8 用于回归,8 用于分类的个)涵盖关键 ADMET 训练和评估各种常见的分子特征和性质 MG-BERT。这 16 详细信息见表1。这些数据集中的所有分子都是 SMILES 存储字符串格式。数据集按 8:1:1 比例分为训练数据集、验证数据集和测试数据集。 SMILES 分层抽样的长度使数据集拆分更加均匀。
模型架构
原始BERT模型由三个组件组成:一个embedding层,几个Transformer与任务相关的编码器层和输出层。在embedding层,输入词token通过一个embedding在连续的向量空间中嵌入矩阵。由于 Transformer 该模型不能自动学习位置信息,因此需要在嵌入层中的每个嵌入向量中添加一个预定义的位置编码向量。在 Transformer 编码层,每个单词 token 相互交换信息通过全局注意机制。embedding层和 Transformer 分享预训练和微调阶段。最后一层通常是一个完全连接的神经网络,进一步处理Transformer输出层并执行特定的分类或回归任务。,分别称为预训练头和预测头。我们在补充部分提供了MG-BERT模型介绍BERT模型的细节更多BERT描述了原始文献。
与原的非结构化 NLP BERT 模型不同,MG-BERT 根据分子图的特点做了一些修改。在嵌入层中,**单词标记被原子类型标记替换。由于分子中的原子没有顺序相关,因此无需分配位置信息。**在自然语言句子中,一个词可能与任何其他词相关,因此需要全局关注。然而,在分子中,原子主要与其相邻的原子相关联,这些原子通过键连接。为了有效地实现这种感应偏置 ,。这种本地消息传递机制使 MG-BERT 成为 GNN 的新变体。值得注意的是,MG-BERT 可以通过残差连接克服过平滑问题,并且具有足够的能力来提取分子图中的深层模式。具体见图1,我们利用分子相邻矩阵来控制分子间的信息交换
图一描述:MG-BERT的整体预训练和微调程序。MG-BERT模型使用基于键的局部注意,其中每个token只能与由化学键连接的token交换信息。除了输出层,预训练和微调都使用相同的架构。在微调阶段,使用[GLOBAL]表示的超级节点提取全局信息,执行相关预测任务。可见矩阵用于调节Transformer层中的注意矩阵,以控制信息交换。
为了获得图级表示,便于后续微调阶段的预测任务,我们为每个分子添加了一个连接所有原子的超级节点。一方面,该超级节点可以与其他节点进行信息交换,在一定程度上很好地解决了长距离依赖问题。另一方面,这种超级节点输出可以被视为最终的分子表示,并用于解决下游的分类或回归任务。
预训练策略
BERT利用两个学习任务对模型进行预处理,包括蒙面语言模型(MLM)任务和下一个句子预测(NSP)任务。MLM任务是一个填空任务,其中模型使用掩码标记周围的上下文单词来预测掩码单词应该是什么。NSP的任务是确定两个句子是否连续。由于分子缺乏像句子这样持续的关系,我们只使用蒙面原子预测任务来预先训练我们的模型。
我们提出的预训练策略与BERT非常相似。首先,随机选择一个分子中15%的原子,对于原子很少的分子,至少选择一个原子。对于每个选择的原子,有80%的概率被[MASK]标记替换,有10%的概率被其他原子随机替换,还有10%的概率保持不变。利用原始分子作为目标来训练模型,并且只在被掩盖的原子上计算损失
输入表示
为了在分子图中表示和操作原子,我们需要将所有的原子类型添加到字典中。然而,分子中出现的原子类型的数量是非常有限的。经过统计分析,字典中收录了13种常见的原子类型,其他很少遇到的原子类型则统一用[UNK]表示。为了获得图形级表示,我们向每个分子图添加了一个超级节点。这个超级节点用[GLOBAL]表示。此外,在预训练阶段需要使用[MASK]令牌来表示被屏蔽的原子。因此,我们的词典包括以下标记:[H], [C], [N], [O], [F], [S], [Cl], [P], [Br], [B],[I],[Si],[Se], [UNK],[MASK],[GLOBAL]。
模型的训练和评估
预训练阶段
在预处理阶段,利用RDKit将每个分子根据组成原子及其连接关系转化为二维无向图。然后在每个分子图上添加一个连接所有节点的超级节点。然后,根据预训练策略,随机选取特定的原子进行掩蔽。最后,将分子图发送到MG-BERT模型中,以预测被掩原子的类型。对于一些只有几个原子的分子,我们保证至少选择一个原子来掩蔽。采用标准批量梯度下降算法和Adam优化器对模型进行训练。learning rate设置为1e−4,batch_size设置为256。这个模型经过了10个epoch的预先训练。
为了评价预训练效果,采用预训练掩蔽策略对测试集中的分子进行掩蔽,然后计算恢复率作为评价指标
微调阶段
预训练结束后,去除预训练头。在超级节点对应的Transformer编码器层的输出中增加了一个两层任务相关的全连接神经网络。采用dropout策略来最小化过拟合。需要注意的是,dropout率对最终预测的影响很大,需要根据具体任务进行优化。根据我们的实证结果,辍学率的推荐范围是[0.0,0.5]。使用Adam优化器作为微调优化器,对每个任务进行有限超参数扫描,批量大小{16,32,64}中选择,学习率从{1e-5,5e-5,1e-4}中选择。
回归模型采用R2进行评估,分类模型ROC-AUC进行评估。为了避免过拟合,我们提前停止训练,并将最大epoch设置为100。为了减少随机误差,对每个数据集进行10次训练,并进行随机数据集拆分,将计算出的平均值和标准差作为最终性能报告。
结果与讨论
MG-BERT模型结构的选择
为了确定MG-BERT模型用于分子性质预测任务的更好结构,我们设计并比较了三种模型结构。表2中列出了具体参数。以训练恢复精度和平均微调性能作为评价指标。如表2所示,由于层数太少,小型MG-BERT模型不如其他两个模型。可见,模型太大容易过拟合,太小导致欠拟合。
表2描述:MG-BERT三种结构的参数和性能
预训练确实很有效
为了验证预训练的有效性,我们比较了在相同超参数设置下预训练和非预训练MG-BERT模型在分子性质预测方面的表现。从表3所示的比较结果可以看出,经过预处理的MG-BERT模型在所有数据集上的表现都比未经过预处理的MG-BERT模型好2%以上,充分证明了预处理策略的有效性和预处理模型良好的泛化能力。 对于Caco2、FDAMDD等小数据集,预测性能提高了7%以上,说明预训练策略可以更有效地提高小数据集的预测性能。这些结果表明,MG-BERT模型确实可以通过提供一个非琐碎的神经网络初始化来学习有用的知识,并将学到的知识转移到下游的任务中。
表3:MG-BERT模型在不同设置下的性能比较(R2;的ROC-AUC)(结果为百分比数)
在表3中,经过预处理的MG-BERT模型在所有数据集上的表现都比未经过预处理的MG-BERT模型好2%以上,这清楚地说明了预处理策略的有效性和预处理模型的良好泛化能力。对于Caco2、FDAMDD等小数据集,预测性能提高了7%以上,说明预训练策略可以更有效地提高小数据集的预测性能。这些结果表明,MG-BERT模型确实可以通过提供一个非琐碎的神经网络初始化来学习有用的知识,并将学到的知识转移到下游的任务中。
氢原子对预训练精度和预测任务的影响
在大多数过去的分子特性预测模型中,氢原子通常被忽略。在本研究中,我们通过对照实验来探讨我们的MG-BERT模型是否需要氢原子。在MG-BERT模型相同的超参数设置下,建立了基于无氢原子分子图的无氢模型。
如图2所示,含氢MGBERT模型的预训练精度可以达到98.31%,而无氢模型的预训练精度只能达到92.25%。从表3所示的微调结果可以看出,含氢MGBERT模型的性能明显优于无氢模型。特别是在一些回归任务中,含氢模型比无氢模型性能好4%以上。
其背后的逻辑是MG-BERT只利用分子的组成和连接信息。在这种情况下,氢原子可以帮助确定其他类型原子的化学键数。在掩膜原子恢复任务中,键的数量对确定掩膜原子的类型至关重要。因此,无氢MG-BERT模型显示掩蔽原子回收率显著降低。此外,氢原子的缺失还会影响预训练阶段的上下文信息挖掘过程,从而削弱预训练模型的泛化能力。此外,如果氢原子被移去,有些分子就变得难以分辨。如图3所示,除去氢原子后,苯和环己烷可以转化为同一张图。然而,如果保留氢原子,它们将被转换成两个不同的图形。这样,氢原子的缺失对微调模型的性能有很大的影响。
与其他机器学习方法的比较
基于不同的分子表示,我们选择了一些最先进的模型作为基准,综合评估我们提出的MG-BERT模型。
- 第一个是XGBoost基于ECFP4指纹的模型(ECFP4- xgboost)。这种组合是分子特性预测任务的经典范例。
- 第二种和第三种是最具代表性和最广泛使用的两种GNNs:图注意网络(GAT)和图卷积网络(GCN)。
- 第四种是基于连续和数据驱动的描述符(CDDD),它由一个固定的基于RNN的编码器组成,该编码器已经预先训练了大量未标记的Smiles字符串和一个完全连接的神经网络。
- 我们还包括了SMILESBERT模型,它直接使用原始BERT模型来处理SMILES字符串。
预测结果见表4和图4。除ROC-AUC和R2外,我们还利用精度和均方根误差(RMSE)进行评估,如表S1所示。
模型表现:
ECFP4-XGBoost模型的性能在不同的数据集上有很大的差异。这很可能是因为ECFP4是一种固定长度的分子表示,导致它所表示的信息在特定任务中可能工作得很好,也可能工作得不好。
包括GAT和GCN在内的GNN模型在标记数据足够的情况下表现良好。然而,当标记的数据较少时,它们的性能就会变得很差,甚至比基于分子指纹的模型还要差。
然而,CDDD模型的分子表征是通过SMILES编码和解码任务获得的,无法针对具体任务进一步优化。
相比之下,SMILE- BERT模型和我们的MG-BERT模型也可以在预训练阶段学习到丰富的上下文敏感信息,并可以针对特定任务进一步优化。SMILES-BERT模型略落后于MG-BERT模型。这可能是由于SMILE字符串的学习要比分子图复杂得多,这意味着smile - bert模型必须解析隐藏在smile字符串复杂语法中的分子信息。MG-BERT模型可以直接从分子图中学习,分子图是分子的自然表示。
总体提高28.1(分类任务提高7.02%,回归任务提高21.28%)。
值得注意的是,对于PPB数据集,MG-BERT模型的改进幅度超过6%。根据配对t检验(P≤0.001),我们的模型相对于基线的改进具有统计学意义(95%置信区间,CI)。这些结果令人信服地强调了MG-BERT在药物设计中成为分子特性预测任务的一个很好的选择的潜力。
我们提出的MG-BERT模型优于其他方法
表4:之前提出的模型和自己提出的模型性能比较。(R2,ROC-AUC)
图4:MG-BERT和最先进的模型在(A)回归任务和(B)分类任务方面的性能比较
用t-SNE分析预训练MG-BERT模型的原子表示
为了分析MG-BERT模型在预训练阶段学到的东西,我们将预训练模型生成的原子表示可视化,并试图找到一些有趣的模式。具体来说,从微调数据集中随机选取1000个分子(包括约22000个原子),不加掩蔽地输入预先训练好的模型,并收集Transformer编码器层的输出。这样,每个原子得到256维的矢量,总共得到约22000个矢量。经典的降维方法t-SNE将这些高维向量可视化。如图5所示,可以很容易地区分不同类型的原子,这说明生成的表示包含原子类型的信息。
图五:TSNE降维,不同的颜色表示不同的原子。为了更好地显示,在t-SNE之前忽略氢原子。
进一步的观察表明,同一类型的原子可以分为几个不同的组。似乎生成的原子表示包含比原子类型更丰富的信息。这一发现启发我们根据原子周围的环境定义一些原子类别,并根据它们的类别可视化原子。类别主要由一阶邻域的可能种类来定义(表5)。
虽然是相同的原子,但是周围的环境不同,在图中也是不同的组,可以视为不同类型的原子。
表五:原子的符号和定义类别
如图6所示,原子根据它们的类别聚集在一起。这些结果表明,为每个原子生成的原子表示包含其一阶邻域的信息。值得注意的是,苯环中的碳原子与其他环境中的碳原子是不同的,这表明预处理模型可以捕获高阶邻域信息。为了进一步分析,我们随机选取了一个复杂的分子,并在图6中标记了其原子的位置。
图6:按原子类别着色的原子嵌入向量的t-SNE图。在主图中,标记了所显示分子的原子的位置。在放大的图中,原子及其对应的位置用相同的颜色标记。放大图中,所有有颜色的原子都在一个苯环上,并与羰基相连。
可以发现,当苯环上的原子具有相似的分支环境时,它们会趋向于相互靠近。我们进一步进行了局部放大,以确定在一个小区域内原子的环境是否一致。在 放大的图中,我们随机标记了一些原子,并显示了它们对应的分子。可以发现,所有这些原子都在一个苯环上,并与一个羰基相连。这些结果证明了我们的预训练模型一定能够在一定程度上捕获高阶邻域信息。
以上结果充分证明,生成的原子表示可以成功捕获一阶甚至高阶邻域信息。这样,学习到的原子表示法就可以被视为分子子结构的表示法,这对后续工作非常有益。
MG-BERT注意力分析
了解分子结构与分子性质之间的关系有利于分子分析和优化,MG-BERT为揭示这些关系提供了一种自然的途径。MG-BERT利用注意机制聚集来自所有原子表示的信息,形成分子表示。这样,注意权重代表了每个原子表示在最终分子表示中的贡献,可以看作是对目标性质的相关度量。需要注意的是,每个原子表示还聚合了来自它相邻原子的信息,因此注意权重不仅是针对单个原子的,而且在某种程度上它的相邻原子也共享。
为了验证我们的模型是否能够合理分配注意权重,我们随机选取一些分子,并根据具体任务将其注意权重可视化。logD和Ames预测任务中几个分子的结果如图7所示。
- logD的性质与分子的亲脂性有关。从图7A可以看出,人们对极性基团的关注更多,而极性基团在决定分子的亲脂性方面起着重要的作用。
- Ames的任务是确定一个分子是否属于诱变剂。图7B显示,注意力主要分布在酰氯、亚硝胺和叠氮化物基团上,这些基团已被证明是致突变的结构警报[48]。
这些结果表明MG-BERT可以根据特定的任务合理分配注意力权重,这对于药物化学家探索亚结构与分子性质之间的关系具有重要意义。
图7:(A) logD预测任务和(B) Ames预测任务中某些分子超节点的注意权重可视化。颜色越深表示关注权重越大。为了方便,氢原子的注意力重心转移到相邻的原子上。
结论
在这项研究中,作者提出了一种称为 MG-BERT 的新型半监督学习方法,以缓解分子特性预测中的数据稀缺问题。提出的 MG-BERT 模型根据分子图的特点对原始 BERT 模型进行了修改。MG-BERT 通过掩码原子恢复任务利用大量未标记的分子数据来挖掘分子图中的上下文信息,以进行有效的原子和分子表示学习。预训练后,MG-BERT 可以很容易地在小标记数据集上进行微调,极大的提升了预测性能。
在实验中,MG-BERT 模型在 11 个有代表性的 ADMET 任务上始终优于baseline模型,充分证明了方法的有效性。**此外,作者对预训练模型中的原子表示进行了可视化,发现生成的原子表示可以在一定程度上完全捕获一阶邻域信息甚至高阶邻域信息。通过这一方式,作者可以有效地解释了为什么预训练对下游任务有益。**虽然 DL 模型具有很强的学习和预测能力,但它们的可解释性一般很差并被称为黑盒模型。MG-BERT 提供了一种通过注意力机制测量原子或子结构与目标属性之间相关性的自然方法。这些特征使 MG-BERT 成为解决分子性质预测和分子优化挑战的有效且可解释的计算工具。
编者按:目前在图上做预训练的工作还不太多,通过BERT和图结构来预训练模型,在技术上和通过自注意力机制做GAT预训练类似,但是BERT的残差链接可以将模型堆叠的更深增加了模型的能力,文中的模型训练时只做了原子MASK,或许MASK边,甚至通过其他的对比学习方式来预训练模型也会有一定的意义。
-
MG-BERT将gnn的本地消息传递机制集成到强大的BERT中。MG-BERT作为gnn的一种新变体,能够克服超平滑问题,具有足够的能力提取分子图中的深层模式。
-
MG-BERT可以利用大量的未标记分子通过掩膜原子恢复任务挖掘分子图中的上下文信息,并将学到的知识转移到分子性质预测中。
-
MG-BERT模型在分子性能预测方面优于目前最先进的模型,无需任何手工制作的特征,并根据与目标性能的相关性合理地分配原子或子结构的注意权重,从而提供解释性。