第08讲:如何划分示例应用微服务
在第 07 在介绍了领域驱动设计的基本概念后,本课时将介绍如何将领域驱动设计应用于微服务划分。
微服务划分
在微服务架构应用的设计和实现中,如果要找出最重要的一个任务,那必定是非莫属。微服务架构的核心是多个互相协作的微服务组成的分布式系统,只有在完成微服务的划分之后,才能明确每个微服务的职责,以及确定微服务之间的交互方式,然后再进行每个微服务的 API 最后是每个微服务的具体实现、测试和部署。
从以上流程可以看出,微服务划分是整个链条设计和实现的第一环。链条中每个环节的变化都会影响后一个环节。作为第一环的微服务划分,如果发生变化,会影响后一个环节。你最不想看到的是,在实现微服务的过程中,发现某些功能应该迁移到其他微服务中。如果发生这种情况,会导致相关的微服务 API 和实现都需要修改。
当然,在实际开发中,完全避免微服务划分的变化是不现实的。在微服务划分阶段,花费足够的精力进行分析,收入绝对巨大。
上下文定义了微服务和定义
在第 07 在课堂上,我们介绍了领域驱动设计中定义的上下文的概念。如果将领域驱动设计的理念应用于微服务架构,微服务可以与定义的上下文逐一对应。
这将微服务划分转化为领域驱动设计中定义的上下文划分。如果你对领域驱动设计有深入的了解,那将是一个优势;如果没有,第一 07 课时的内容可以让你快速入门。
以本专栏示例应用为例。
示例应用的微服务划分
第 06 介绍了示例应用的用户场景,基于这些场景,可以确定应用领域。在实际应用开发中,领域专家和业务人员通常需要参与。通过与业务人员的沟通,我们可以更清楚地了解这个领域。在示例应用方面,由于应用领域更贴近生活,也为了简化相关介绍, 由我们自己进行领域分析。然而,有一个缺点,即开发人员的领域分析可能无法反映真正的业务流程。但是,对于示例应用来说,这已经足够好了。
领域驱动设计以领域为核心,分为领域和。
帮助我们思考业务水平是核心领域所依赖的部分,包括核心领域和所需的其他子领域。核心领域必须从零开始创建,因为这是我们将要开发的软件系统的核心内容;其他子领域可能已经存在或需要从零开始创建。问题空间的核心问题是如何识别和划分子领域。
它由一个或多个定义的上下文组成,以及上下文中的模型。理想情况下,上下文和子领域之间存在一对应的关系。这样,就可以从业务层面进行划分,然后在实现层面上采用相同的划分方法,从而实现问题空间决空间的完美整合。在实践中,定义上下文和子领域之间不太可能有一对应的关系。在实现软件系统时,通常需要与现有的遗留系统和外部系统集成,这些系统有自己的定义。实际上,更现实的情况是,多个定义的上下文属于同一个子领域,或者一个定义的上下文对应于多个子领域。
领域驱动设计的理念是从领域出发,先划分子领域,然后从子领域抽象定义的上下文和模型,每个定义的上下文对应一个微服务。
核心领域
核心领域是软件系统的价值,也是设计的起点。在软件系统开始之前,你应该清楚地了解软件系统的核心价值。如果没有,你首先需要考虑软件系统的卖点。不同的软件系统有不同的核心领域。作为出租车应用,其核心领域是如何让乘客快速、舒适、安全出行,这也是滴滴出租车和优步出租车应用的核心领域。对于快乐旅游应用作为一个例子,这样的核心领域的应用简化了核心领域,只关注如何让乘客快速旅游。
我们需要给核心领域一个合适的名字。快乐旅行的核心领域是如何快速匹配需要叫车的乘客和提供旅行服务的司机。用户创建行程后,系统将其发送给可用的司机。当司机接收行程时,系统选择司机发送行程。核心领域的重点是分配行程,因此命名为。
领域中的概念
然后列出了该领域的概念。这是一个头脑风暴的过程,可以在白板上进行,一个接一个地列出所有想到的相关概念,概念是一个术语,最早的概念是旅程,表示从一个起点到终点的旅程。从行程开始,可以引出乘客和司机的概念,乘客是行程的发起者,司机是行程的完成者,每次行程都有起点和终点,相应的概念是地址。司机使用私家车来完成行程,所以车辆是另一个概念。
我们根据概念找到其他子领域,旅行的概念属于核心领域。司机和乘客应该属于各种独立的子领域,然后分别管理,这就产生了和两个子领域。地址的概念属于子领域;车辆的概念属于司机管理子领域。
在通过该领域的概念划分子领域后,我们将继续从该领域的操作中找到新的子领域。用户场景中提到的行程需要验证,该操作有相应的子领域。行程完成后,乘客需要付款,这个操作有相应的子领域。
下图显示了示例应用中的子领域。
 

定义上下文
在确定了核心领域和其他子领域后,下一步可以从问题空间转移到解决方案空间。首先,将子领域映射成定义的上下文,定义的上下文与子领域的名称相同;然后模定义的上下文。建模的主要任务是具体化相关概念。
行程派发
行程分配模型中的重要实体不仅是行程,也是行程聚合的根源。行程有其起始和结束位置,以值对象地址表示。行程由乘客启动,因此行程实体需要乘客引用。当系统选择司机接受行程时,行程实体会引用司机。在整个生命周期中,行程可能处于不同的状态。有一个属性和相应的列举类型来描述行程的状态。
下图显示了模型中的实体和值对象。

乘客管理
乘客管理模式中的重要实体是乘客,也是乘客聚合的根源。乘客实体的属性包括姓名、Email 地址、联系电话等,乘客实体有已保存的地址列表,地址为实体。
下图显示了模型中的实体。

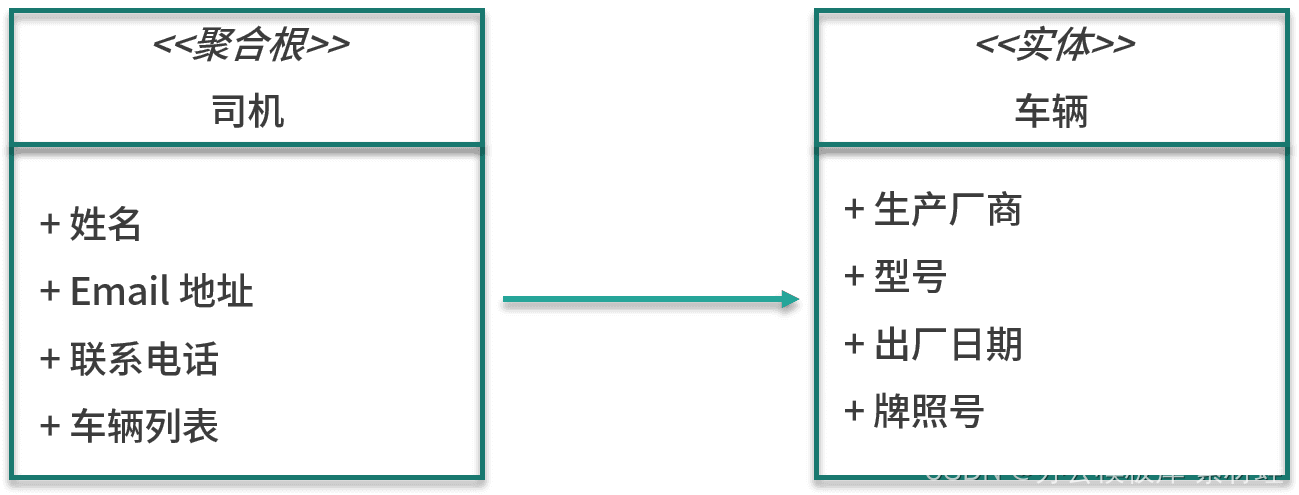
司机管理
司机管理模型中的重要实体是司机,也是司机聚合的根源。司机实体的属性包括姓名、Email 除司机实体外,聚合还包括车辆实体,车辆实体的属性包括厂家、型号、出厂日期、牌照号等。
下图显示了模型中的实体。
地址管理
地址管理模市、自治区到农村、街道,地址管理模型中的重要实体是地址。除分级地址外,还有一个重要的信息,即地理位置坐标,包括经度和纬度。
行程验证
具体实体不包含在行程验证模型中,而是验证行程的服务和相关算法的实现。
支付管理
支付记录是支付管理模型中的一个重要实体,包括引用行程和支付状态。
定义上下文之间的交互
在我们定义的上下文模型中,行程分配模型的行程实体需要引用乘客管理模型中乘客的根实体和司机管理模型中司机的根实体。在第 07 正如我们在课堂上提到的,外部对象只能引用聚合物的根实体。引用时,应引用聚合物根实体的标识符,而不是实体本身。乘客实体和司机实体的标识符是字符串类型,因此行程实体包含两个字符串类型的属性,分别引用乘客实体和司机实体。
当定义不同时上下文中的模型中出现相同的概念时,则需要进行映射,我们可以使用第 07 课时中提到的上下文映射的模式来进行映射。
在地址管理和行程派发上下文中,都有地址的概念。地址管理中的地址实体是一个复杂的结构,包括不同分级的地理名称,这是为了实现多级式的地址选择和地址查询。在行程派发上下文中,地址则只包含一个完整的名称,以及地理位置坐标。为了在两个上下文中进行映射,我们可以在行程派发上下文上增加一个防腐蚀层来进行模型的转换。
已有单体应用的迁移
本专栏的示例应用是从头开始创建的新应用,因此在划分微服务时并没有可参考的已有实现。当把已有的单体应用迁移为微服务架构时,划分微服务会更加的有迹可循,可以从单体应用的已有实现中,了解到系统各个部分的实际交互,有助于更好的根据它们的职责来进行划分。这样划分出来的微服务更贴近实际的运行情况。
ThoughtWorks 的 Sam Newman 在其《Building Microservices》一书中分享了产品 SnapCI 的微服务划分的经验,由于有开源项目 GoCD 的相关经验,SnapCI 团队很快就划分了 SnapCI 的微服务。但是,GoCD 和 SnapCI 的用户场景存在一些不同,在一段时间过后,SnapCI 团队发现当前的微服务划分带来了很多问题,他们经常需要做一些跨多个微服务的改动,产生了很高的开销。
SnapCI 团队的做法是把这些微服务重新合并成一个单体系统,让他们有更多的时间来了解系统的实际运行状况。一年之后,SnapCI 团队把这个单体系统重新划分成微服务,经过这一次的划分,微服务的边界变得更加稳定。SnapCI 的这个例子说明了在划分微服务时,对领域的了解是至关重要的。
总结
微服务划分在微服务架构应用开发中至关重要。通过应用领域驱动设计的思想,把微服务的划分问题转换成领域驱动设计中子领域的划分问题,再通过界定的上下文来对领域中的概念进行建模。通过界定的上下文之间的映射模式,可以进行模型的转换。
第09讲:快速部署开发环境与框架
本课时将介绍“快速部署开发环境与框架”相关的内容。
在前面的课时中,我们对云原生微服务架构相关的背景知识进行了介绍,接下来的课时将进入到实际的微服务开发中。本课时作为微服务开发相关的第一个课时,将着重介绍如何准备本地开发环境,以及对示例应用中用到的框架、第三方库和工具进行介绍。
开发必备
开发必备指的是开发环境所必须的。
Java
示例应用的微服务是基于 Java 8 开发的。虽然 Java 14 已经发布,示例应用仍然采用较旧的 Java 8 版本,这是因为该版本的使用仍然很广泛,并且在 Java 8 之后添加的新功能对示例应用的作用不大。如果没有安装 JDK 8,建议你去 AdoptOpenJDK 网站下载 OpenJDK 8 的安装程序。在 MacOS 和 Linux 上,可以用 SDKMAN! 来安装 JDK 8 和管理不同版本的 JDK。
下面是 java -version 的输出结果:
openjdk version "1.8.0_242" OpenJDK Runtime Environment (AdoptOpenJDK)(build 1.8.0_242-b08) OpenJDK 64-Bit Server VM (AdoptOpenJDK)(build 25.242-b08, mixed mode)
Maven
示例应用使用的构建工具是 Apache Maven,你可以手动安装 Maven 3.6,或使用 IDE 中自带的 Maven 来构建项目。MacOS 和 Linux 上推荐使用 HomeBrew 来安装,Windows 上推荐使用 Chocolatey 来安装。
集成开发环境
一个好的集成开发环境可以极大的提高开发人员的生产力。在 IDE 方面,主要是 IntelliJ IDEA 和 Eclipse 两个选择;在 IDE 的选择上,两者并没有太大的区别,我自己使用的 IntelliJ IDEA 社区版 2020。
Docker
本地开发环境需要使用 Docker 来运行应用所需的支撑服务,包括数据库和消息中间件等。通过 Docker,解决了不同软件服务的安装问题,使得开发环境的配置变得非常简单。从另外一个方面来说,应用的生产运行环境是 Kubernetes,其也是使用容器化部署的,这样就保证了开发环境和生产环境的一致性。为了简化本地开发流程,在本地环境上使用 Docker Compose 来进行容器编排。
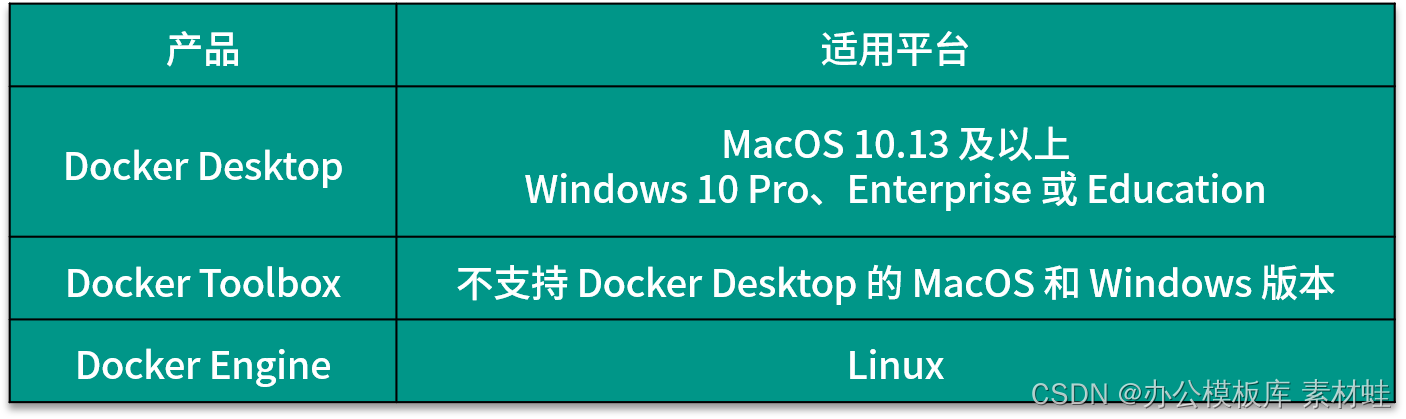
根据开发环境的操作系统的不同,安装 Docker 的方式也不相同。一共有 3 种不同的 Docker 产品可以用来安装 Docker,分别是 Docker Desktop、Docker Toolbox 和 Docker Engine,下表给出了这 3 个产品的适用平台。对 MacOS 和 Windows 来说,如果版本支持,则应该优先安装 Docker Desktop,然后再考虑 Docker Toolbox。
Docker Desktop 产品由很多组件组成,包括 Docker Engine、Docker 命令行客户端、Docker Compose、Notary、Kubernetes 和 Credential Helper。Docker Desktop 的优势在于直接使用操作系统提供的虚拟化支持,可以提供更好的集成,除此之外,Docker Desktop 还提供了图形化的管理界面。大部分时候,我们都是通过 docker 命令行来操作 Docker。如果 docker -v 命令可以显示正确的版本信息,就说明 Docker Desktop 安装成功。
下图给出了 Docker Desktop 的版本信息。

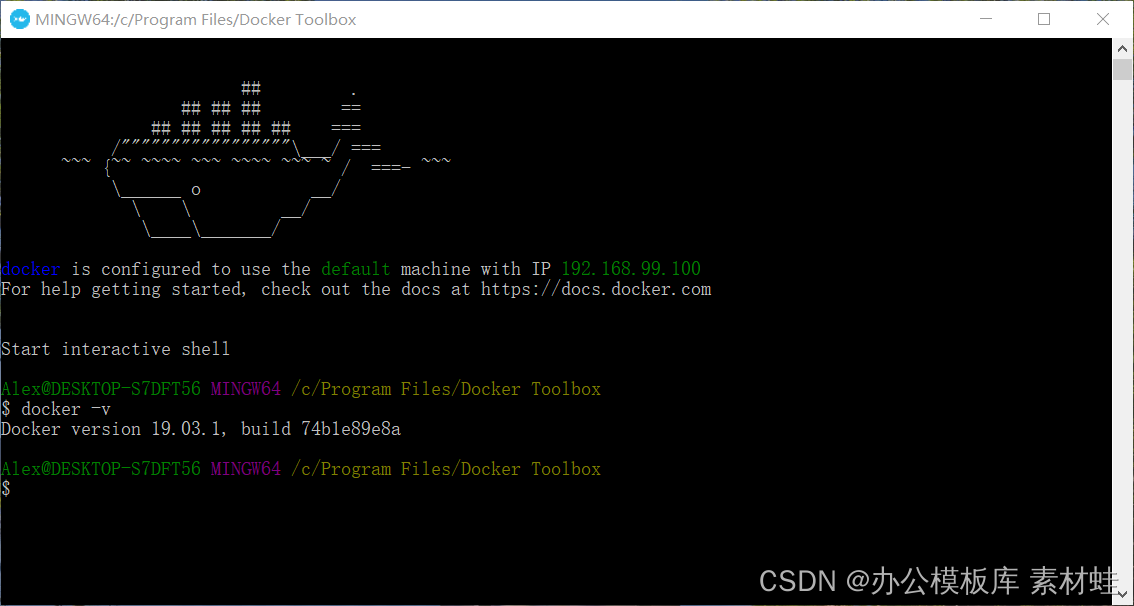
Docker Toolbox 是 Docker Desktop 之前的产品。Docker Toolbox 使用 VirtualBox 进行虚拟化,对系统的要求较低。Docker Toolbox 由 Docker Machine、Docker 命令行客户端、Docker Compose、Kitematic 和 Docker Quickstart 终端组成。安装完成之后,通过 Docker Quickstart 启动一个终端来执行 docker 命令。
下图是 Docker Quickstart 终端的运行效果。
在 Linux 上,我们只能直接安装 Docker Engine,同时还需要手动安装 Docker Compose。
Docker Desktop 和 Docker Toolbox 在使用上有一个显著的区别。Docker Desktop 上运行的容器可以使用当前开发环境主机上的网络,容器暴露的端口,可以使用 localhost 来访问;Docker Toolbox 上运行的容器,实际上运行在 VirtualBox 的一个虚拟机之上,需要通过虚拟机的 IP 地址来访问。我们可以在 Docker Quickstart 启动的终端上通过 docker-machine ip 命令来获取到该 IP 地址,如 192.168.99.100。容器暴露的端口,需要使用这个 IP 地址来访问,这个 IP 地址不是固定不变的。推荐的做法是在 hosts 文件中添加名为 dockervm 的主机名,并指向这个 IP 地址。在访问容器中的服务时,总是使用 dockervm 这个主机名。当虚拟机的 IP 地址改变时,只需要更新 hosts 文件即可。
Kubernetes
在部署应用时,我们需要一个可用的 Kubernetes 集群,一般有 3 种方式创建 Kubernetes 集群。
第一种方式是。很多云平台都提供了对 Kubernetes 的支持,由云平台来负责 Kubernetes 集群的创建和管理,只需要通过 Web 界面或命令行工具就可以快速创建 Kubernetes 集群。使用云平台的好处是省时省力,但是开销较大。
第二种方式是。虚拟机可以是云平台提供的,也可以是自己创建和管理的,使用自己维护的物理裸机集群也是可以的。有非常多的开源 Kubernetes 安装工具可供使用,如 RKE、Kubespray、Kubicorn 等。这种方式的好处是开销比较小,不足之处是需要前期的安装和后期的维护。
第三种方式是。Docker Desktop 已经自带 Kubernetes,只需要启用即可,除此之外,还可以安装 Minikube。这种方式的好处是开销最低并且高度可控,不足之处是会占用本地开发环境的大量资源。
在上述三种方式中,云平台的方式适合于生产环境的部署。对于测试和交付准备(Staging)环境来说,则可以选择云平台,也可以从开销的角度选择自己搭建环境。本地开发环境上的 Kubernetes 在很多时候也是必须的。
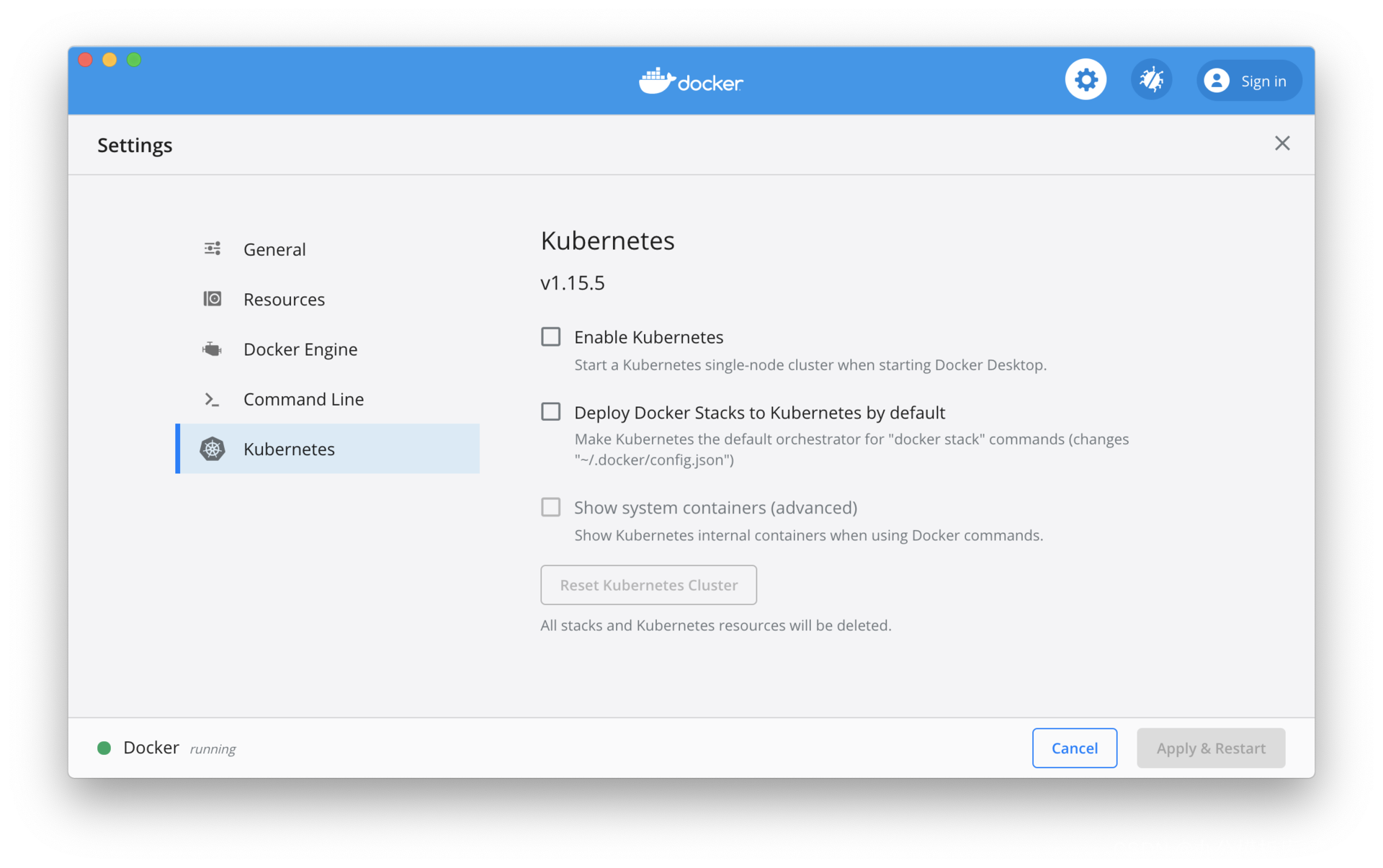
在本地开发环境中,Docker Desktop 的 Kubernetes 需要手动启用。对于 Minikube,可以参考官方文档来进行安装。两者的区别在于,Docker Desktop 自带的 Kubernetes 版本一般会落后几个小版本。如下图所示,勾选“Enable Kubernetes”选项,可以启动 Kubernetes 集群。Docker Desktop 自带的 Kubernetes 版本是 1.15.5,而目前最新的 Kubernetes 版本是 1.18。
框架与第三方库
示例应用会用到一些框架和第三方库,下面对它们进行简单的介绍。
Spring 框架和 Spring Boot
Java 应用开发很难离开 Spring 框架。Spring Boot 也是目前 Java 开发微服务的流行选择之一,关于 Spring 和 Spring Boot 的介绍,不在本专栏的范围之内。示例应用的微服务会用到 Spring 框架中的一些子项目,包括 Spring Data JPA、Spring Data Redis 和 Spring Security 等。
Eventuate Tram
Eventuate Tram 是示例应用使用的事务性消息框架,事务性消息模式在保持数据的一致性上有重要作用。Eventuate Tram 提供了对事务性消息模式的支持,还包括对异步消息传递的支持。Eventuate Tram 与 PostgreSQL、Kafka 进行集成。
Axon 服务器与框架
示例应用也使用了事件源和 CQRS 技术,事件源实现使用的是 Axon 服务器和 Axon 框架。Axon 服务器提供了事件的存储;Axon 框架则连接 Axon 服务器,并提供了 CQRS 支持。
支撑服务与工具
示例应用的支撑服务是运行时所必须的,相关的工具则是开发中可能会用到的。
Apache Kafka 和 ZooKeeper
示例应用在不同的微服务之间使用异步消息来保证数据的最终一致性,因此需要使用消息中间件。Apache Kafka 作为示例应用中使用的消息中间件,ZooKeeper 是运行 Kafka 必须的。
PostgreSQL
示例应用的某些微服务使用关系型数据库来存储数据。在众多的关系型数据库中,PostgreSQL 被选择作为示例应用中某些微服务的数据库。
数据库管理工具
在开发中,我们可能需要查看关系型数据库中的数据。有很多 PostgreSQL 的客户端可供使用,包括 DBeaver、pgAdmin 4、OmniDB 等,还可以使用 IDE 的插件,比如 IntelliJ IDEA 上的 Database Navigator 插件。
Postman
在开发和测试中,我们经常需要发送 HTTP 请求来测试 REST 服务,与测试 REST 服务相关的工具很多,常用的有 Postman、Insomnia 和 Advanced REST Client 等。我推荐使用 Postman,是因为它可以直接导入 OpenAPI 规范文件,并生成相应的 REST 请求模板。由于我们的微服务采用 API 优先的设计方式,每个微服务的 API 都有相应的 OpenAPI 规范文件。在开发时,我们只需要把 OpenAPI 文件导入 Postman,就可以开始测试了,省去了手动创建请求的工作。
总结
在讲解实战之前,我们首先需要准备本地的开发环境。本课时首先介绍了如何安装和配置 Java、Maven、集成开发环境、Docker 和 Kubernetes;接着对示例应用中用到的框架和第三方库进行了简要介绍;最后介绍了示例应用所使用的支撑服务,以及开发中需要用到的工具。
第10讲:使用 OpenAPI 和 Swagger 实现 API 优先设计
从本课时开始,我们将进入到云原生微服务架构应用的实战开发环节,在介绍微服务的具体实现之前,首要的工作是设计和确定每个微服务的。开放 API 在近几年得到了广泛的流行,很多在线服务和政府机构都对外提供了开放 API,其已经成为在线服务的标配功能。开发者可以利用开放 API 开发出各种不同的应用。
微服务应用中的开放 API 与在线服务的开放 API,虽然存在一定的关联,但作用是不同的。在微服务架构的应用中,微服务之间只能通过进程间的通讯方式来交互,一般使用 REST 或 gRPC。这样的交互方式需要以形式化的方式固定下来,就形成了开放 API,一个微服务的开放 API 对外部使用者屏蔽了服务内部的实现细节,同时也是外部使用者与之交互的唯一方式(当然,这里指的是微服务之间仅通过 API 来进行集成,如果使用异步事件来进行集成的话,这些事件也是交互方式)。由此可以看出,微服务 API 的重要性。从受众的角度来说,微服务API的使用者主要是其他微服务,也就是说,主要是应用内部的使用者,这一点与在线服务的 API 主要面向外部用户是不同的。除了其他微服务之外,应用的 Web 界面和移动客户端也需要使用微服务的 API,不过,它们一般通过 API 网关来使用微服务的 API。
由于微服务 API 的重要性,我们需要在很早的时候就得进行 API 的设计,也就是 API 优先的策略。
API 优先的策略
如果你有过开发在线服务 API 的经验,会发现通常是先有实现,再有公开 API,这是因为在设计之前,并没有考虑到公开 API 的需求,而是之后才添加的公开 API。这种做法带来的结果就是,开放的 API 只是反映了当前的实际实现,而不是 API 应该有的样子。API 优先(API First)的设计方式,是把 API 的设计放在具体的实现之前,API 优先强调应该更多地从 API 使用者的角度来考虑 API 的设计。
在写下第一行实现的代码之前,API 的提供者和使用者应该对 API 进行充分的讨论,综合两方面的意见,最终确定 API 的全部细节,并以形式化的格式固定下来,成为 API 规范。在这之后,API 的提供者确保实际的实现满足 API 规范的要求,使用者则根据 API 规范来编写客户端实现。API 规范是提供者和使用者之间的契约,API 优先的策略已经应用在很多在线服务的开发中了。API 设计并实现出来之后,在线服务自身的 Web 界面和移动端应用,和其他第三方应用一样,都使用相同的 API 实现。
API 优先的策略,在微服务架构的应用实现中,有着更加重要的作用。这里有必要区分两类 API:一类是提供给其他微服务使用的 API,另一类是提供给 Web 界面和移动客户端使用的 API。在第 07 课时中介绍领域驱动设计的时候,我提到过界定的上下文的映射模式中的开放主机服务和公开语言,微服务与界定的上下文是一一对应的。如果把开放主机服务和公共语言结合起来,就得到了微服务的 API,公共语言就是 API 的规范。
从这里我们可以知道,第一类微服务 API 的目的是进行上下文映射,与第二类 API 的作用存在显著的不同。举例来说,乘客管理微服务提供了管理乘客的功能,包括乘客注册、信息更新和查询等。对于乘客 App 来说,这些功能都需要 API 的支持,其他微服务如果需要获取乘客信息,也必须调用乘客管理微服务的 API。这是为了把乘客这个概念在不同的微服务之间进行映射。
API 实现方式
在 API 实现中,首要的一个问题是选择 API 的实现方式。理论上来说,微服务的内部 API 对互操作性的要求不高,可以使用私有格式。不过,为了可以使用服务网格,推荐使用通用的标准格式,下表给出了常见的 API 格式。除了使用较少的 SOAP 之外,一般在 REST 和 gRPC 之间选择。两者的区别在于,REST 使用文本格式,gRPC 使用二进制格式;两者在流行程度、实现难度和性能上存在不同。简单来说,REST 相对更加流行,实现难度较低,但是性能不如 gRPC。

本专栏的示例应用的 API 使用 REST 实现,不过会有一个课时专门来介绍 gRPC。下面介绍与 REST API 相关的 OpenAPI 规范。
OpenAPI 规范
为了在 API 提供者和使用者之间更好的沟通,我们需要一种描述 API 的标准格式。对于 REST API 来说,这个标准格式由 OpenAPI 规范来定义。
OpenAPI 规范(OpenAPI Specification,OAS)是由 Linux 基金会旗下的 OpenAPI 倡议(OpenAPI Initiative,OAI)管理的开放 API 的规范。OAI 的目标是创建、演化和推广一种供应商无关的 API 描述格式。OpenAPI 规范基于 Swagger 规范,由 SmartBear 公司捐赠而来。
OpenAPI 文档描述或定义 API,OpenAPI 文档必须满足 OpenAPI 规范。OpenAPI 规范定义了 OpenAPI 文档的内容格式,也就是其中所能包含的对象及其属性。OpenAPI 文档是一个 JSON 对象,可以用 JSON 或 YAML 文件格式来表示。下面对 OpenAPI 文档的格式进行介绍,本课时的代码示例都使用 YAML 格式。
OpenAPI 规范中定义了几种基本类型,分别是 integer、number、string 和 boolean。对于每种基本类型,可以通过 format 字段来指定数据类型的具体格式,比如 string 类型的格式可以是 date、date-time 或 password。
下表中给出了 OpenAPI 文档的根对象中可以出现的字段及其说明,目前 OpenAPI 规范的最新版本是 3.0.3。

Info 对象
Info 对象包含了 API 的元数据,可以帮助使用者更好的了解 API 的相关信息。下表给出了 Info 对象中可以包含的字段及其说明。

下面的代码是 Info 对象的使用示例。
title: 测试服务 description: 该服务用来进行简单的测试 termsOfService: http://myapp.com/terms/ contact: name: 管理员 url: http://www.myapp.com/support email: support@myapp.com license: name: Apache 2.0 url: https://www.apache.org/licenses/LICENSE-2.0.html version: 2.1.0
Server 对象
Server 对象表示 API 的服务器,下表给出了 Server 对象中可以包含的字段及其说明。
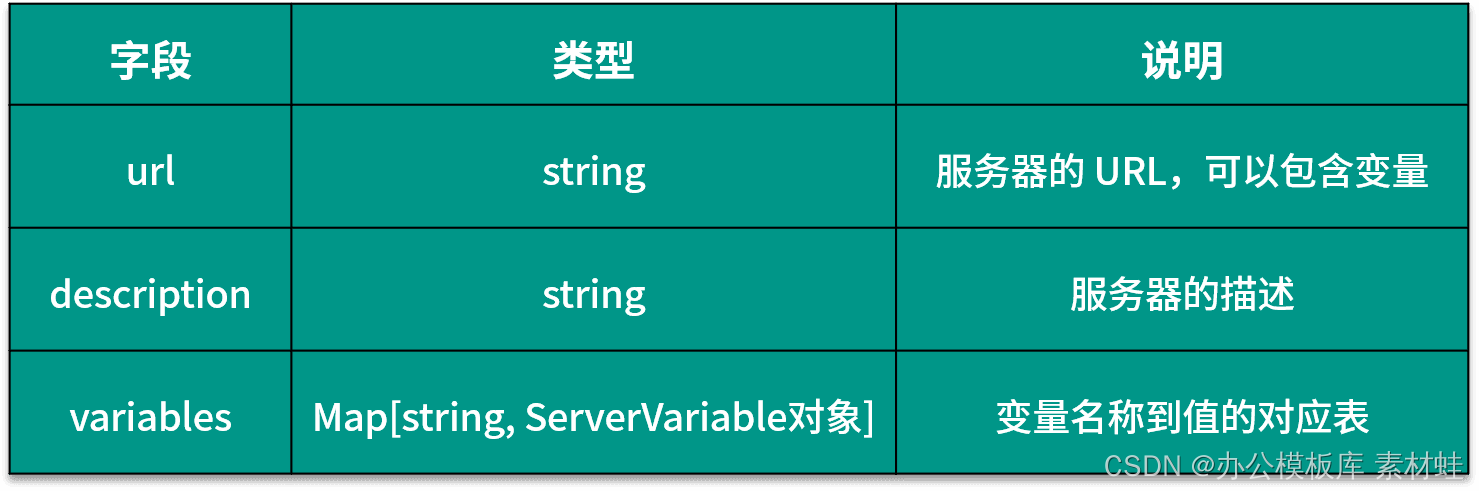
下面代码是 Server 对象的使用示例,其中服务器的 URL 中包含了 port 和 basePath 两个参数,port 是枚举类型,可选值是 80 和 8080。
url: http://test.myapp.com:{port}/{basePath}
description: 测试服务器
variables:
port:
enum:
- '80'
- '8080'
default: '80'
basePath:
default: v2 Paths 对象
Paths 对象中的字段是动态的。每个字段表示一个路径,以“/”开头,路径可以是包含变量的字符串模板。字段的值是 PathItem 对象,在该对象中可以使用 summary、description、servers 和 parameters 这样的通用字段,还可以使用 HTTP 方法名称,包括 get、put、post、delete、options、head、patch 和 trace,这些方法名称的字段,定义了对应的路径所支持的 HTTP 方法。
Operation 对象
在 Paths 对象中,HTTP 方法对应的字段的值的类型是 Operation 对象,表示 HTTP 操作。下表给出了 Operation 对象中可以包含的字段及其说明,在这些字段中,比较常用的是 parameters、requestBody 和 responses。

Parameter 对象
Parameter 对象表示操作的参数。下表给出了 Parameter 对象中可以包含的字段及其说明。
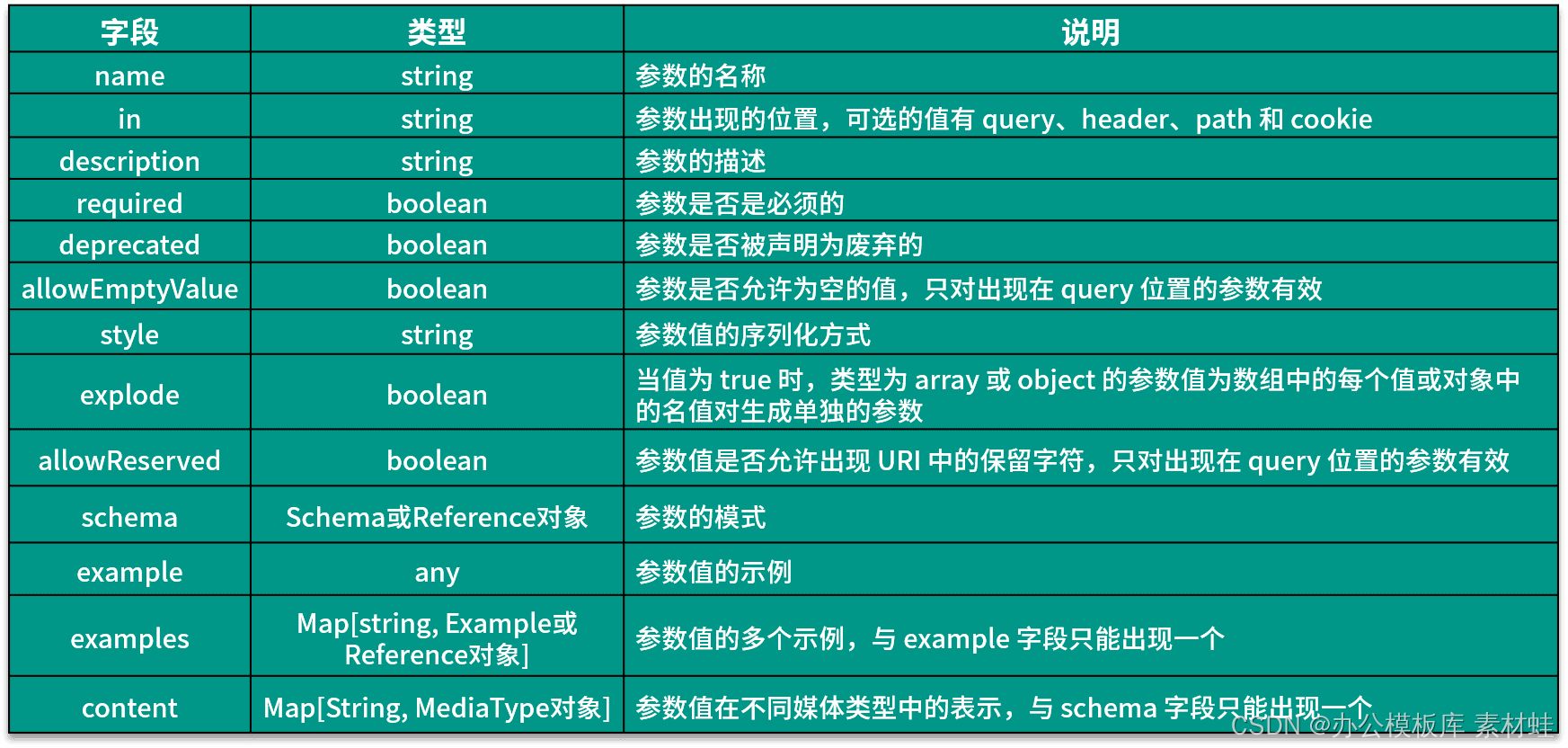
下面的代码是 Parameter 对象的使用示例,参数 id 出现在路径中,类型是 string。
name: id in: path description: 乘客ID required: true schema: type: string
RequestBody 对象
RequestBody 对象表示 HTTP 请求的内容,下表给出了 RequestBody 对象中可以包含的字段及其说明。
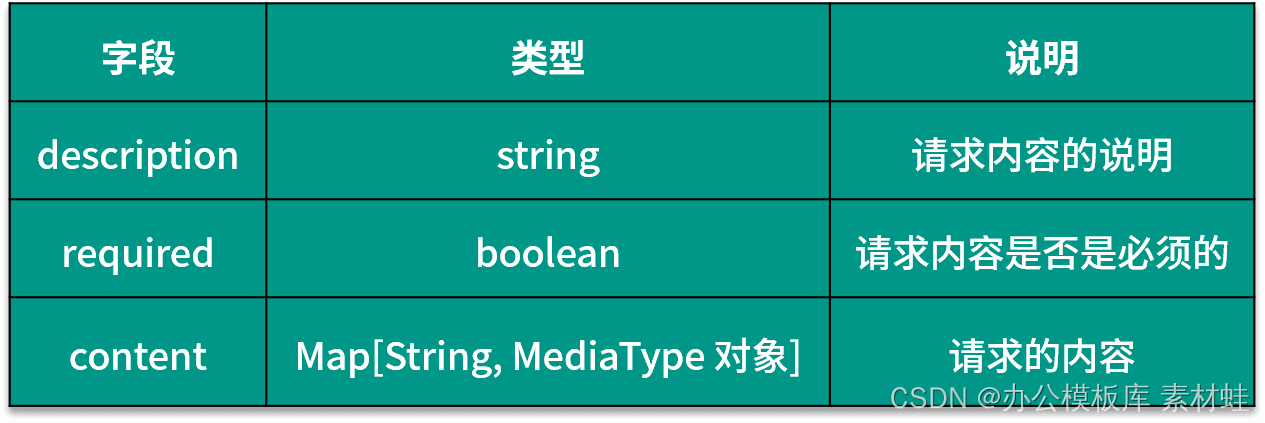
Responses 对象
Responses 对象表示 HTTP 请求的响应,该对象中的字段是动态的。字段的名称是 HTTP 响应的状态码,对应的值的类型是 Response 或 Reference 对象。下表给出了 Response 对象中可以包含的字段及其说明。

Reference 对象
在对不同类型的对象描述中,字段的类型可以是 Reference 对象,该对象表示对其他组件的引用,其中只包含一个 $ref 字段来声明引用。引用可以是同一文档中的组件,也可以来自外部文件。在文档内部,可以在 Components 对象中定义不同类型的可复用组件,并由 Reference 对象来引用;文档内部的引用是以 # 开头的对象路径,比如 #/components/schemas/CreateTripRequest。
Schema 对象
Schema 对象用来描述数据类型的定义,数据类型可以是简单类型、数组或对象类型,通过字段 type 可以指定类型,format 字段表示类型的格式。如果是数组类型,即 type 的值是 array,则需要通过字段 items 来表示数组中元素的类型;如果是对象类型,即 type 的值是 object,则需要通过字段 properties 来表示对象中属性的类型。
完整文档示例
下面是一个完整的 OpenAPI 文档示例。在 paths 对象中,定义了 3 个操作,操作的请求内容和响应格式的类型定义,都在 Components 对象的 schemas 字段中定义。操作的 requestBody 和 responses 字段都使用 Reference 对象来引用。
openapi: '3.0.3'
info:
title: 行程服务
version: '1.0'
servers:
- url: http://localhost:8501/api/v1
tags:
- name: trip
description: 行程相关
paths:
/:
post:
tags:
- trip
summary: 创建行程
operationId: createTrip
requestBody:
content:
application/json:
schema:
$ref: "#/components/schemas/CreateTripRequest"
required: true
responses:
'201':
description: 创建成功
/{tripId}:
get:
tags:
- trip
summary: 获取行程
operationId: getTrip
parameters:
- name: tripId
in: path
description: 行程ID
required: true
schema:
type: string
responses:
'200':
description: 获取成功
content:
application/json:
schema:
$ref: "#/components/schemas/TripVO"
'404':
description: 找不到行程
/{tripId}/accept:
post:
tags:
- trip
summary: 接受行程
operationId: acceptTrip
parameters:
- name: tripId
in: path
description: 行程ID
required: true
schema:
type: string
requestBody:
content:
application/json:
schema:
$ref: "#/components/schemas/AcceptTripRequest"
required: true
responses:
'200':
description: 接受成功
components:
schemas:
CreateTripRequest:
type: object
properties:
passengerId:
type: string
startPos:
$ref: "#/components/schemas/PositionVO"
endPos:
$ref: "#/components/schemas/PositionVO"
required:
- passengerId
- startPos
- endPos
AcceptTripRequest:
type: object
properties:
driverId:
type: string
posLng:
type: number
format: double
posLat:
type: number
format: double
required:
- driverId
- posLng
- posLat
TripVO:
type: object
properties:
id:
type: string
passengerId:
type: string
driverId:
type: string
startPos:
$ref: "#/components/schemas/PositionVO"
endPos:
$ref: "#/components/schemas/PositionVO"
state:
type: string
PositionVO:
type: object
properties:
lng:
type: number
format: double
lat:
type: number
format: double
addressId:
type: string
required:
- lng
- lat OpenAPI 工具
我们可以用一些工具来辅助 OpenAPI 规范相关的开发。作为 OpenAPI 规范的前身,Swagger 提供了很多与 OpenAPI 相关的工具。
Swagger 编辑器
Swagger 编辑器是一个 Web 版的 Swagger 和 OpenAPI 文档编辑器。在编辑器的左侧是编辑器,右侧是 API 文档的预览。Swagger 编辑器提供了很多实用功能,包括语法高亮、快速添加不同类型的对象、生成服务器代码和生成客户端代码等。
使用 Swagger 编辑器时,可以直接使用在线版本,也可以在本地运行,在本地运行最简单的方式是使用 Docker 镜像 swaggerapi/swagger-editor。
下面的代码启动了 Swagger 编辑器的 Docker 容器,容器启动之后,通过 localhost:8000 访问即可。
docker run -d -p 8000:8080 swaggerapi/swagger-editor
下图是 Swagger 编辑器的界面。

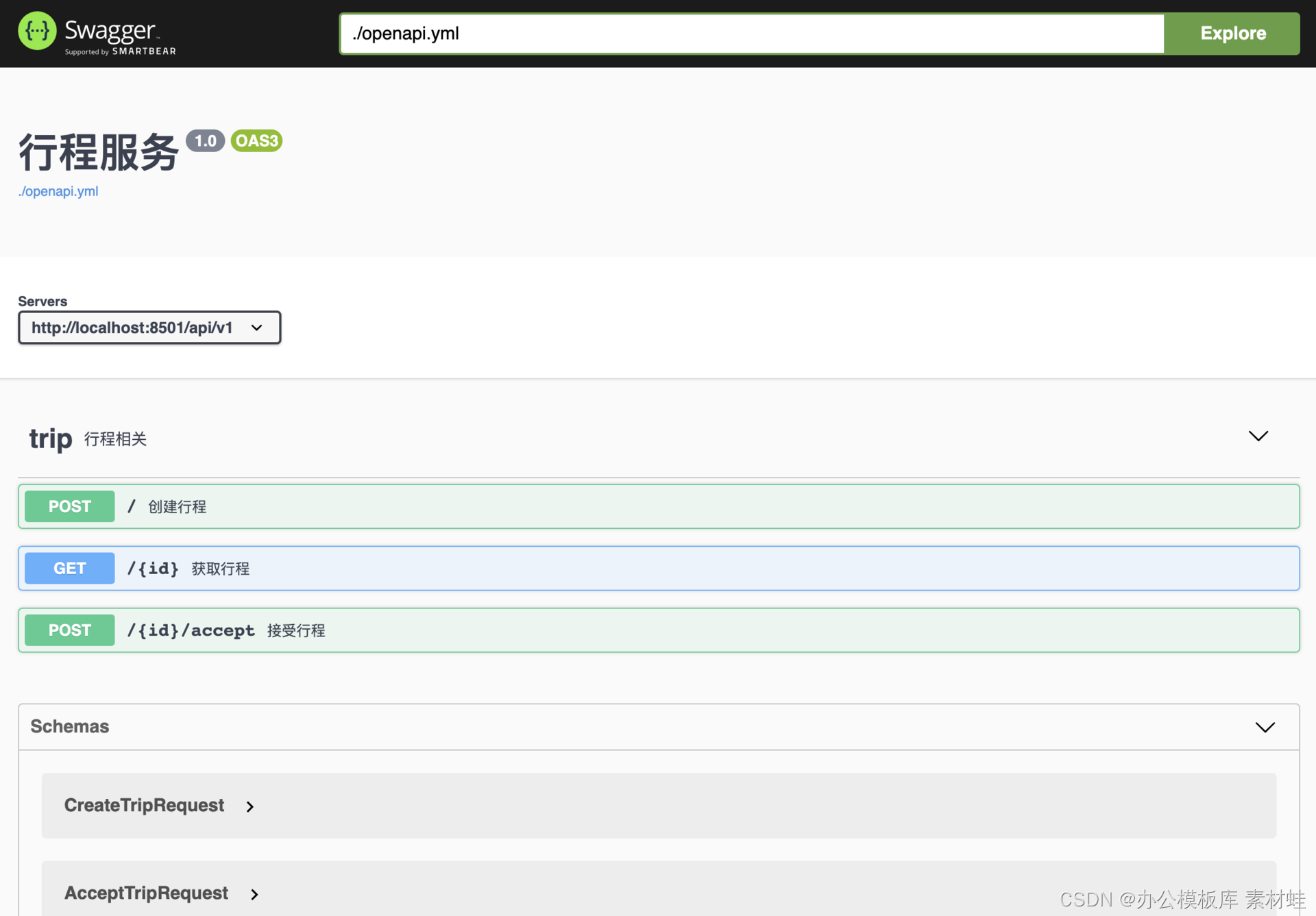
Swagger 界面
Swagger 界面提供了一种直观的方式来查看 API 文档,并进行交互。通过该界面,可以直接发送 HTTP 请求到 API 服务器,并查看响应结果。
同样,我们可以用 Docker 来启动 Swagger 界面,如下面的命令所示。容器启动之后,通过 localhost:8010 来访问即可。
docker run -d -p 8010:8080 swaggerapi/swagger-ui
对于本地的 OpenAPI 文档,可以配置 Docker 镜像来使用该文档。假设当前目录中有 OpenAPI 文档 openapi.yml,则可以使用下面的命令来启动 Docker 镜像来展示该文档。
docker run -p 8010:8080 -e SWAGGER_JSON=/api/openapi.yml -v $PWD:/api swaggerapi/swagger-ui
下图是 Swagger 界面的截图。
代码生成
通过 OpenAPI 文档,可以利用 Swagger 提供的代码生成工具来自动生成服务器存根代码和客户端。代码生成时可以使用不同的编程语言和框架。
下面给出了代码生成工具所支持的编程语言和框架。
aspnetcore, csharp, csharp-dotnet2, go-server, dynamic-html, html, html2, java, jaxrs-cxf-client, jaxrs-cxf, inflector, jaxrs-cxf-cdi, jaxrs-spec, jaxrs-jersey, jaxrs-di, jaxrs-resteasy-eap, jaxrs-resteasy, micronaut , spring, nodejs-server, openapi, openapi-yaml, kotlin-client, kotlin-server, php, python, python-flask, r, scala, scal a-akka-http-server, swift3, swift4, swift5, typescript-angular, javascript
代码生成工具是一个 Java 程序,下载之后可以直接运行。在下载 JAR 文件 swagger-codegen-cli-3.0.19.jar 之后,可以使用下面的命令来生成 Java 客户端代码,其中 -i 参数指定输入的 OpenAPI 文档,-l 指定生成的语言,-o 指定输出目录。
java -jar swagger-codegen-cli-3.0.19.jar generate -i openapi.yml -l java -o /tmp
除了生成客户端代码之外,还可以生成服务器存根代码。下面代码是生成 NodeJS 服务器存根代码:
java -jar swagger-codegen-cli-3.0.19.jar generate -i openapi.yml -l nodejs-server -o /tmp
总结
API 优先的策略保证了微服务的 API 在设计时,充分考虑到 API 使用者的需求,使得 API 成为提供者和使用者之间的良好契约。本课时首先介绍了 API 优先的设计策略,然后介绍了 API 的不同实现方式,接着介绍了 REST API 的 OpenAPI 规范,最后介绍了 OpenAPI 的相关工具。