https://baijiahao.baidu.com/s?id=1678519457206249337&wfr=spider&for=pc GCN它是一种卷积神经网络,可以直接在图纸上工作,并使用图纸的结构信息。 GCN基本思路:对于每个节点,我们从其所有邻居节点获取其特征信息,包括其自身特征。假设我们使用它average()函数。我们将操作相同的所有节点。最后,我们将这些计算的平均值输入到神经网络中。 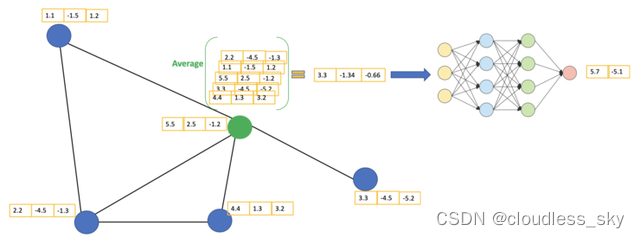 GCN以绿色节点为例。首先,我们,包括自身节点。然后,将平均值通过神经网络。请注意,在GCN中,我们只是。在这个例子中,我们(全连接层的两个节点)。 我们可以在实际操作中使用比例average聚合函数更复杂。我们也可以叠加在一起获得。每层的输出将被视为下一层的输入。从邻居那里获得的信息也会传播到下一层。可以想象,当层数过多时,最后一层基本上聚集了所有的信息,这是不好的。 2层GCN的例子:第一层的输出是第二层的输入。同样,(图片来自[2])。
GCN以绿色节点为例。首先,我们,包括自身节点。然后,将平均值通过神经网络。请注意,在GCN中,我们只是。在这个例子中,我们(全连接层的两个节点)。 我们可以在实际操作中使用比例average聚合函数更复杂。我们也可以叠加在一起获得。每层的输出将被视为下一层的输入。从邻居那里获得的信息也会传播到下一层。可以想象,当层数过多时,最后一层基本上聚集了所有的信息,这是不好的。 2层GCN的例子:第一层的输出是第二层的输入。同样,(图片来自[2])。
数学原理 详见交叉熵的解释:https://wenku.baidu.com/view/81d0aef2900ef12d2af90242a8956bec0975a50e.html 简单地说,对于交叉熵损失函数,预测值Z和标签Y越像,L就越小。
以下是更详细、更直观的解释:
从图G中,我们有一个相邻矩阵A和一个度矩阵D。同时,我们也有节点矩阵的特征X。 这里的邻接矩阵通常通过节点之间的地理距离或特征相似性来计算,或通过随机初始化node embedding,然后从正则化或图形传播后的损失函数反向传播中学习。详见以下两个博客: https://nakaizura.blog.csdn.net/article/details/120995371 https://blog.csdn.net/qq_39388410/article/details/120997414
那么我们?A和是解决方案X的相乘。
看看相邻矩阵的第一行。我们看到节点A和节点E之间有连接。矩阵的第一行是连接到A的E节点的特征向量(如下图所示)。同样,矩阵的第二行是D和E通过这种方法,我们可以得到所有邻居节点的向量之和。
计算 "和向量矩阵 "AX的第一行。
还有一些地方需要改进。 我们忽略了节点本身的特征。例如,计算矩阵的第一行也应包含节点A的特征。 不需要使用sum()函数,但需要取平均值,甚至更好的邻居节点特征向量量。那我们为什么不用呢?sum()函数呢?原因是在使用sum()函数时,大度节点可能产生大V向量,低度节点往往获得小的聚集向量,可能导致梯度爆炸或梯度消失(例如,使用sigmoid时)。此外,神经网络似乎对输入数据的规模非常敏感。因此,我们需要将这些向量归一化,以摆脱可能出现的问题。 在问题(1)中,我们可以通过在A中添加单位矩阵I来获得新的邻接矩阵。
取lambda=1(让节点本身和邻居一样重要),我们有=A I,注意,我们可以把lambda作为训练参数,但现在只需要lambda即使在论文中,赋值也可以是1,lambda只是简单的赋值为1。 通过为每个节点添加一个自循环,我们可以获得新的邻接矩阵
问题(2): 对于矩阵缩放,我们通常将矩阵乘以对角线矩阵。在目前的情况下,我们应该根据节点度数采取聚合特性的平均值或聚合向量矩阵X。直觉告诉我们,这里用来缩放的对角矩阵与度矩阵D有关(为什么?D,而不是D?因为我们考虑的是新邻接矩阵 的度矩阵D,而不是A)。
现在的问题已经成为我们想要的?换句话说:
我们如何将邻居的信息传递给特定的节点?我们从老朋友那里average开始。在这种情况下,D逆矩阵(即,D^{-1}会起作用。基本上,D逆矩阵中的每个元素都是对角矩阵D中相应项的倒数。 例如,节点A的度数为2,因此我们将节点A的聚合向量乘以1/2,而节点E的度数为5。我们应该将E的聚合向量乘以1/5,以此类推。
因此,通过D取反和X乘法,我们可以取所有邻居节点的平均特征向量(包括自己的节点)。
到目前为止,一切都很好。但是你可能会问加权平均()怎么样?直觉上,如果我们区别对待高低节点,应该会更好。 但我们只是按行缩放,却忽略了相应的列(虚线框)。 。
新的缩放方法为我们提供了 “加权 平均值。我们在这里做的是。这种平均加权的想法是,我们假设低节点会对邻居节点产生更大的影响,而高节点更低,因为它们的影响分散在太多的邻居节点上。 在节点B处聚合邻接节点特征时,我们为节点B本身分配最大的权重(度数为3),为节点E分配最小的权重(度数为5)。 因为我们归一化了两次,所以我们将-1 改为-1/2 例如,我们有10个类别的多分类问题,F 设置为10。在第二层有10个维度的向量后,我们通过一个向量softmax预测函数。
Loss函数的计算方法很简单,就是通过所有标签例子的交叉熵误差来计算,其中Y_{l}是标签节点的集合。
**层数是指节点特征可以传输的最远距离。**例如,在一楼GCN其中,每个节点只能从邻居那里获取信息。每个节点收集信息的过程是独立的,所有节点都是同时进行的。
当我们在第一层的基础上叠加另一层时,我们重复信息收集过程,但这一次,邻居节点已经有了自己的邻居信息(从上一步)。这使得层数成为每个节点最大的跳跃。因此,这取决于我们认为节点应该从网络中获得多远的信息,我们可以为#layers设置合适的数字。但在图片中,我们通常不想走得太远。设置为6-7跳,我们几乎可以得到整个图片,但这使得聚合意义不大。 在论文中,作者还分别是浅层和深层GCN做了一些实验。在下图中,我们可以看到使用两层或三层模型可以得到最好的结果。此外,对于深层GCN(7层以上),但往往性能不佳(虚线蓝色)。解决方案是利用隐藏层之间的残余连接(紫线)。
GNN 该模型可分为频谱域 (spectral domain) 和空间域 (spatial domain) 两大类:spectral 该方法通常采用拉普拉斯矩阵,借助图谱进行卷积操作;spatial 该方法通常以更直接的方式聚合邻居节点的信息。以上是基于频谱域的。以下是空间域,实际上是通过直接积累节点的邻域信息来实现图的卷积。 http://www.51blog.com/?p=11720
各种图 https://baijiahao.baidu.com/s?id=1686742016283743917&wfr=spider&for=pc 监督下:直接使用交叉熵等损失函数 无监督:基础Random walk, graph factorization之类的 https://zhuanlan.zhihu.com/p/150596886 https://blog.csdn.net/zandaoguang/article/details/111940065
http://snap.stanford.edu/proj/embeddings-www/files/nrltutorial-part1-embeddings.pdf GNN如何训练模型好?node embedding?
GAT https://baijiahao.baidu.com/s?id=1671028964544884749&wfr=spider&for=pc 图神经网络 GNN 将深度学习应用到图结构中 (Graph) 其中,图卷积网络 GCN 可以在 Graph 卷积操作。但是 GCN 有一些缺陷:**依赖拉普拉斯矩阵不能直接用于有向图;模型训练依赖于整个图形结构,不能用于动态图;不同的权重不能分配给邻居节点。**因此 2018 年图注意网络 GAT (Graph Attention Network) 提出,解决 GCN 存在的问题。
GCN 假设图是无向的,因为使用了对称的拉普拉斯矩阵 (只有邻接矩阵 A 拉普拉斯矩阵可以正交分解),不能直接用于有向图。GCN 为了处理向图,作者需要处理向图 Graph 调整结构,。例如 e1、e2 两个节点,r 为 1,e2 的有向关系,则需要把 r 划分为两个关系节点 r1 和 r2 放入图中。连接 (e1, r1)、(e2, r2)。
GCN 不能处理动态图,GCN 在训练时依赖于具体的图结构,测试的时候也要在相同的图上进行。因此只能处理 transductive 任务,不能处理 inductive 任务。transductive 指训练和测试的时候基于相同的图结构,例如在一个社交网络上,知道一部分人的类别,预测另一部分人的类别。inductive 指训练和测试使用不同的图结构,例如在一个社交网络上训练,在另一个社交网络上预测。
GCN 不能为每个邻居分配不同的权重,GCN 在卷积时对所有邻居节点均一视同仁,不能根据节点重要性分配不同的权重。 2018 年图注意力网络 GAT 被提出,用于解决 GCN 的上述问题,论文是《GRAPH ATTENTION NETWORKS》。**GAT 采用了 Attention 机制,**可以为不同节点分配不同权重,训练时依赖于成对的相邻节点,而不依赖具体的网络结构,可以用于 inductive 任务。
VGAE https://blog.csdn.net/zz1049694353/article/details/118968296 自编码器图自编码器, 一种自监督的学习框架. 通过学习网络节点的, 然后通过图数据. http://www.51blog.com/?p=9363
理解了变分自编码器后,再来理解变分图自编码器就很容易了。如图5所示,输入图的邻接矩阵 A 和节点的特征矩阵 X ,通过编码器(图卷积网络)学习节点低维向量表示的均值 μ 和方差 σ ,然后用解码器(链路预测)生成图。
图生成网络GGN
图生成网络, 从数据中获取图的经验分布, 然后根据经验分布来的网络.
特定领域有很多图网络模型, 比如用于分子图生成的SMILES.
近来提出了一些统一的生成方法, 其中有一部分将图生成看做节点和边的交替生成的过程, 另一部分采用GAN的方案进行训练.