一、简介
1、概述
远程字典服务器(Remote Dictionary Server,Redis):开源、高性能、轻量级、使用ANSI C语言编写、支持网络、基于内存或可持续的日志,Key-Value数据库是跨平台的非关系数据库,通过提供多种关键数据类型来测试不同场景下的缓存和存储需求。
2、特性
Redis 通过字典结构,允许其他应用程序存储数据TCP协议读写字典的内容。和大多数脚本语言中的字典一样,Redis字典中的键值不仅可以是字符串,还可以是其他数据类型。到目前为止,Redis支持键值数据类型:字符串类型、散列类型、列表类型、集合类型、有序集合类型。
Redis数据库中的所有数据都存储在内存中。因为内存的读写速度远快于硬盘,所以Redis与其他基于硬盘存储的数据库相比,性能具有非常明显的优势。
在内存中存储数据也存在问题,如程序退出后内存中的数据丢失。不过 Redis在不影响继续提供服务的情况下,可以将内存中的数据异步写入硬盘。Redis 在此基础上,将更新的数据定期写入磁盘或将修改操作写入额外的记录文件master-slave(主从)同步(数据备份)。
Redis实例提供多个存储数据的字典,客户端可以指定哪个字典存储数据, 字典可以理解为数据库。Redis默认链接16个数据库,每个数据库都是从0开始的递增数字命名,可以通过databases参数修改连接数,默认选择0号数据库SELECT命令更换redis > SELECT 1。
Redis 不支持自定义数据库名称或为每个数据库设置不同的访问密码。Redis 如果使用,数据库之间没有完全隔离FLUSHALL 一个可以清空Redis 所有实例数据。不同的应用程序应使用不同的应用程序Redis在实例中存储数据,同一实例的多个数据库可用于存储同一应用的不同环境的数据。
二、安装部署
1、卸载
(1)查看 Redis 还在运行吗?
[appuser@localhost redis]$ ps -ef|grep redis appuser 135694 125912 0 14:24 pts/1 00:00:00 ./bin/redis-server *:6379 appuser 135731 125912 0 14:24 pts/1 00:00:00 grep --color=auto redis (2)停止 Redis
[appuser@localhost redis]$ redis-cli SHUTDOWN (3)删除 Redis 相关安装文件
# 查找 Redis 安装路径: [root@localhost ~]# find / -name redis [root@localhost ~]# rm -rf /xxx/xxx/xxx 2、安装
以下内容为Linux版本的Redis安装过程:
Redis使用开源ANSI C语言编写需要安装c 解释器
[appuser@localhost app]$yum -y install gcc gcc-c libstdc -devel 官网:https://redis.io/download
[appuser@localhost ~]$ cd /app/redis [appuser@localhost redis]$ tar -zxvf redis-6.2.3.tar.gz [appuser@localhost ~]$cd /app/redis/redis-6.2.3 [appuser@localhost redis-6.2.3]$ make - 编译可能报错:
zmalloc.h:50:31: error: jemalloc/jemalloc.h: No such file or directory zmalloc.h:55:2: error: #error "Newer version of jemalloc required" make[1]: *** [adlist.o] Error 1 make[1]: Leaving directory `/data0/src/redis-2.6.2/src' make: *** [] Error 2
原因分析:关于分配器allocator,如果有MALLOC 这个环境变量,会有用这个环境变量的去建立Redis。而且libc 并不是默认的分配器, 默认的是 jemalloc,因为 jemalloc 被证明有更少的 fragmentation problems 比libc。但是如果你又没有jemalloc 而只有 libc 当然 make 出错。 所以加这么一个参数。
[appuser@localhost redis-6.2.3]$ make MALLOC=libc
1.4 安装
[appuser@localhost redis-6.2.3]$ make PREFIX=/app/redis install
Reids 的默认安装路径在/usr/local/bin,关键字 PREFIX 作用是编译的时候用于指定程序存放的路径。如果不添加该关键字,Linux会将可执行文件存放在/usr/local/bin目录,库文件会存放在/usr/local/lib目录。配置文件会存放在/usr/local/etc目录。其他的资源文件会存放在usr/local/share目录。这里指定好目录也方便后续的卸载,后续直接rm -rf /app/redis即可删除Redis
3、启停
Redis启动方式有两种:直接启动、通过初始化脚本启动,分别适用于开发环境和生产环境
- 直接启动
# 拷贝一份配置文件
[appuser@localhost ~]$ cd /app/redis
[appuser@localhost redis]$ cp redis-6.2.3/redis.conf conf/
[appuser@localhost bin]$ ./bin/redis-server conf/redis.conf
配置文件redis.conf中设置daemonize=yes,则Redis将采取后台进程方式启动
- 通过初始化脚本启动
在Linux中可以通过初始化脚本启动Redis,使得Reds能随系统自动运行,在生产环境中推荐使用该方式运行Redis。具体步骤如下:
① 配置初始化脚本:在redis-6.2.3/utils文件夹下有一个初始化脚本文件redis_init_script,将该脚本复制到ect/init.d目录中,文件重命名为redis_端口号,并将脚本中REDISPORT变量值改为同样的端口号。
② 创建文件夹:/etc/redis(存储redis的配置文件)、/var/redis/端口号(存放redis持久化文件)
③ 修改配置文件:将配置文件模板复制到/etc/redis目录中,重命名为端口号.conf,并修改一下参数:
# 使Redis以守护进程模式进行
daemonize=yes
# 设置Redis的PID文件位置
pidfile=/var/run/redis_端口号.pid
# 设置Redis监听的端口号
port=端口号
# 设置持久化文件存放位置
dir=/var/redis/端口号
现在就可以使用/etc/init.d/redis_端口号 start 来启动Redis了,而后需要执行下面的命令使Redis随系统自动启动:
[root@localhost ~]# sudo update_rc.d redis_端口号 default
Redis 有可能正在将内存中的数据同步到硬盘中,强行终止Redis进程可能会丢失数据,正确方式是向Redis发送 SHUTDOWN命令
[appuser@localhost bin]$ ./redis-cli SHUTDOWN
当 Redis收到 SHUTDOWN命令后会先断开所有客户端链接,然后根据配置执行持久化,最后退出
Redis 可以妥善处理SIGTERM信号,所以使用kill Redis进程的PID 也可以正常结束 Redis,效果同 SHUTDOWN命令
4、配置
Redis详细配置参见:https://www.redis.com.cn/redis-configuration.html
5、客户端
通过redis-cli向 Redis 发送命令有两种方式:
- 将命令作为redis-cli的参数执行
[appuser@localhost bin]$ ./redis-cli -h 127.0.0.1 -p 6379 PING
- 交互模式
# 不携带参数进入交互模式
[appuser@localhost bin]$ ./redis-cli
127.0.0.1:6379> PING
三、基础知识
1、命令
- KEYS pattern : 获得符合规则的键名列表
pattern 支持glob风格通配符格式: ? 、* 、[] 、\
-
EXISTS key : 判断一个键是否存在
-
DEL key [key…]:删除键
del不支持通配符,可结合Linux管道和xargs命令:redis-cli KEYS "user*" | xargs redis-cli DEL
-
TYPE key 获得键值的数据类型
-
dump key:序列化给定 key ,并返回被序列化的值
使用 RESTORE 命令可以将这个值反序列化为 Redis 键
- rename oldName newName:用于修改key的名称
- https://redis.io/commands
- https://www.runoob.com/redis/redis-commands.html
2、可执行文件
- redis-server : Redis服务器
- redis-cli : Redis命令行客户端
- redis-benchmark : Redis性能测试工具
- redis-check-aof : AOF文件修补工具
- redis-check-dump : RDB文件检查工具
- redis-sentinel : Sentinel服务器
-
集群客户端命令(redis-cli -c -h host -p port)
- 集群
- cluster info :打印集群的信息
- cluster nodes :列出集群当前已知的所有节点( node),以及这些节点的相关信息。
- 节点
- cluster meet :将 ip 和 port 所指定的节点添加到集群当中,让它成为集群的一份子。
- cluster forget <node_id> :从集群中移除 node_id 指定的节点。
- cluster replicate <node_id> :将当前节点设置为 node_id 指定的节点的从节点。
- cluster saveconfig :将节点的配置文件保存到硬盘里面。
- 槽(slot)
- cluster addslots [slot …] :将一个或多个槽( slot)指派( assign)给当前节点。
- cluster delslots [slot …] :移除一个或多个槽对当前节点的指派。
- cluster flushslots :移除指派给当前节点的所有槽,让当前节点变成一个没有指派任何槽的节点。
- cluster setslot node <node_id> :将槽 slot 指派给 node_id 指定的节点,如果槽已经指派给另一个节点,那么先让另一个节点删除该槽>,然后再进行指派。
- cluster setslot migrating <node_id> :将本节点的槽 slot 迁移到 node_id 指定的节点中。
- cluster setslot importing <node_id> :从 node_id 指定的节点中导入槽 slot 到本节点。
- cluster setslot stable :取消对槽 slot 的导入( import)或者迁移( migrate)。
- 键
- cluster keyslot :计算键 key 应该被放置在哪个槽上。
- cluster countkeysinslot :返回槽 slot 目前包含的键值对数量。
- cluster getkeysinslot :返回 count 个 slot 槽中的键
- 集群
-
连接 Redis服务器
-
第一种:交互式方式
$redis-cli -h 127.0.0.1 -p 6379 127.0.0.1:6379>set hello world OK 127.0.0.1:6379>get hello "world" -
第二种方式:命令方式
$redis-cli -h 127.0.0.1 -p 6379 get hello "world"redis-cli包含很多参数,redis-cli -help命令查询参数。
-
-r(repeat):代表将命令执行多次,例如下面操作将会执行三次ping
# ping命令可用于检测redis实例是否存活,如果存活则显示PONG redis-cli -r 3 ping PONG PONG PONG -
-i(interval):代表每隔几秒执行一次命令,但是-i选项必须和-r选 项一起使用,下面的操作会每隔1秒执行一次ping命令,一共执行5次:
# 注意-i的单位是秒,不支持毫秒为单位,但是如果想以每隔10毫秒执行 一次,可以用-i0.01 redis-cli -r 5 -i 0.01 ping # 例如下面的操作利用-r和-i选项,每隔1秒输出内存的使用量,一共输出 100次 redis-cli -r 100 -i 1 info | grep used_memory_human used_memory_human:2.95G used_memory_human:2.95G -
-x :选项代表从标准输入(stdin)读取数据作为redis-cli的最后一个参数
# 将字符串world作为set hello的值 $ echo "world" | redis-cli -x set hello OK -
-c(cluster):连接Redis Cluster节点时需要使用的,防止moved和ask异常
-
-a : 如果Redis配置了密码,可以用-a(auth)选项,有了这个选项就不需要 手动输入auth命令
-
–scan 和 --pattern:用于扫描指定模式的键,相当于使用scan命令
-
–slave:把当前客户端模拟成当前Redis节点的从节点,可以用来 获取当前Redis节点的更新操作
-
–rdb: 请求Redis实例生成并发送RDB持久化文件,保存在本地。 可使用它做持久化文件的定期备份
# 下面开启第一个客户端,使用--slave选项,看到同步已完成: $ redis-cli --slave SYNC with master, discarding 72 bytes of bulk transfer... SYNC done. Logging commands from master. -
–pipe:用于将命令封装成Redis通信协议定义的数据格式,批量发送 给Redis执行
# 例如下面操作 同时执行了set hello world和incr counter两条命令: echo -en '*3\r\n$3\r\nSET\r\n$5\r\nhello\r\n$5\r\nworld\r\n*2\r\n$4\r\nincr\r\ n$7\r\ncounter\r\n' | redis-cli --pipe -
–bigkeys:使用scan命令对Redis的键进行采样,从中找到内存占用比,较大的键值,这些键可能是系统的瓶颈
-
–eval:用于执行指定Lua脚本,有关Lua脚本的使用将在3.4节介绍。
-
–latency:测试客户端到目标Redis的网络延迟,客户端B和Redis在机房B,客户端A在机房A,机房A和机房B是跨地区的,拓扑图:
# 可以看到客户端A由于距离Redis比较远,平均网络延迟会稍微高一些 # 客户端B: redis-cli -h { machineB} --latency min: 0, max: 1, avg: 0.07 (4211 samples) # 客户端A: redis-cli -h { machineB} --latency min: 0, max: 2, avg: 1.04 (2096 samples)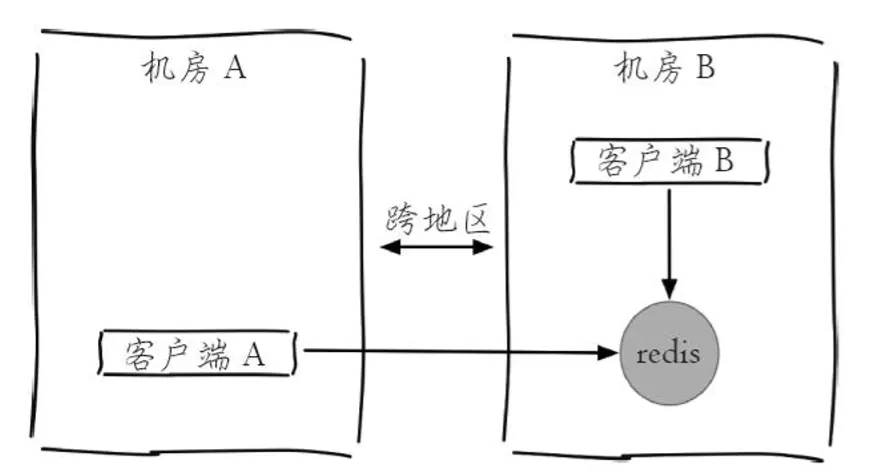
-
–latency-history:以分时段的形式了解延迟信息
# 可以看到延时信息每15秒输出一次,可以通过-i参数控制间隔时间。 redis-cli -h 10.10.xx.xx --latency-history min: 0, max: 1, avg: 0.28 (1330 samples) -- 15.01 seconds range… min: 0, max: 1, avg: 0.05 (1364 samples) -- 15.01 seconds range -
–latency-dist:使用统计图表的形式从控制台输出延迟统计信息
-
–stat:可以实时获取Redis的重要统计信息,虽然info命令中的统计信息更全,但是能实时看到一些增量的数据(例如requests)对于Redis的运维还是有一定帮助的
-
–raw 返回格式化后的结果
-
–no-raw 要求命令的返回结果必须是原始的格式
# 在Redis中设置一个中文的value: $redis-cli set hello "你好" OK # 如果正常执行get或者使用--no-raw选项,那么返回的结果是二进制格式: //如果使用了--raw选项,将会返回中文: $redis-cli --raw get hello
-
-
-
redis-cli --cluster help
redis-cli --cluster help
Cluster Manager Commands:
create host1:port1 ... hostN:portN #创建集群
--cluster-replicas <arg> #从节点个数
check host:port #检查集群
--cluster-search-multiple-owners #检查是否有槽同时被分配给了多个节点
info host:port #查看集群状态
fix host:port #修复集群
--cluster-search-multiple-owners #修复槽的重复分配问题
reshard host:port #指定集群的任意一节点进行迁移slot,重新分slots
--cluster-from <arg> #需要从哪些源节点上迁移slot,可从多个源节点完成迁移,以逗号隔开,传递的是节点的node id,还可以直接传递--from all,这样源节点就是集群的所有节点,不传递该参数的话,则会在迁移过程中提示用户输入
--cluster-to <arg> #slot需要迁移的目的节点的node id,目的节点只能填写一个,不传递该参数的话,则会在迁移过程中提示用户输入
--cluster-slots <arg> #需要迁移的slot数量,不传递该参数的话,则会在迁移过程中提示用户输入。
--cluster-yes #指定迁移时的确认输入
--cluster-timeout <arg> #设置migrate命令的超时时间
--cluster-pipeline <arg> #定义cluster getkeysinslot命令一次取出的key数量,不传的话使用默认值为10
--cluster-replace #是否直接replace到目标节点
rebalance host:port #指定集群的任意一节点进行平衡集群节点slot数量
--cluster-weight <node1=w1...nodeN=wN> #指定集群节点的权重
--cluster-use-empty-masters #设置可以让没有分配slot的主节点参与,默认不允许
--cluster-timeout <arg> #设置migrate命令的超时时间
--cluster-simulate #模拟rebalance操作,不会真正执行迁移操作
--cluster-pipeline <arg> #定义cluster getkeysinslot命令一次取出的key数量,默认值为10
--cluster-threshold <arg> #迁移的slot阈值超过threshold,执行rebalance操作
--cluster-replace #是否直接replace到目标节点
add-node new_host:new_port existing_host:existing_port #添加节点,把新节点加入到指定的集群,默认添加主节点
--cluster-slave #新节点作为从节点,默认随机一个主节点
--cluster-master-id <arg> #给新节点指定主节点
del-node host:port node_id #删除给定的一个节点,成功后关闭该节点服务
call host:port command arg arg .. arg #在集群的所有节点执行相关命令
set-timeout host:port milliseconds #设置cluster-node-timeout
import host:port #将外部redis数据导入集群
--cluster-from <arg> #将指定实例的数据导入到集群
--cluster-copy #migrate时指定copy
--cluster-replace #migrate时指定replace
help
For check, fix, reshard, del-node, set-timeout you can specify the host and port of any working node in the cluster.
① 创建集群主节点
./redis-cli --cluster create host1:port1 host2:port2 host3:port3
② 创建集群主从节点
//说明:--cluster-replicas 参数为数字,1表示每个主节点需要1个从节点
./redis-cli --cluster create host1:port1 host2:port2 host3:port3 host4:port4 host5:port5 host6:port6 --cluster-replicas 1 -a 123456
③ 添加集群主节点
// 新节点:host1:port1 集群中任意一节点:host2:port2
./redis-cli --cluster add-node host1:port1 host2:port2
④ 添加集群从节点
./redis-cli --cluster add-node host1:port1 host2:port2 --cluster-slave --cluster-master-id master_node_id
// 新节点:host1:port1
// 集群中任意一节点:host2:port2
// 指定新节点的主节点的节点ID:master_node_id,不指定将随机分配给某个主节点
⑤ 删除节点
// 指定IP、端口和node_id 来删除一个节点,从节点可以直接删除,有slot分配的主节点不能直接删除
./redis-cli --cluster del-node target_host:target_port target_node_id
⑥ 检查集群
// host:port:集群中任意节点
./redis-cli --cluster check host:port --cluster-search-multiple-owners
⑦ 查看集群信息 key、slots、从节点个数的分配情况
./redis-cli --cluster info host:port
⑧ 修复集群和槽的重复分配问题
./redis-cli --cluster fix host:port --cluster-search-multiple-owners
⑨ 设置集群的超时时间
./redis-cli --cluster set-timeout host:port 10000
⑩ 集群中执行相关命令
// 连接到集群的任意一节点来对整个集群的所有节点进行设置
redis-cli --cluster call 192.168.163.132:6381 config set requirepass cc
redis-cli -a cc --cluster call 192.168.163.132:6381 config set masterauth cc
redis-cli -a cc --cluster call 192.168.163.132:6381 config rewrite
⑪集群伸缩:
- 根据提示迁移:
./redis-cli -a cc --cluster reshard host:port
- 根据参数迁移
// 连接到集群的任意一节点来对指定节点指定数量的slot进行迁移到指定的节点
./redis-cli -a cc --cluster reshard host1:port1 --cluster-from node_id1 --cluster-to node_id2 --cluster-slots 10 --cluster-yes --cluster-timeout 5000 --cluster-pipeline 10 --cluster-replace
⑫ 平衡(rebalance)slot :
- 平衡集群中各个节点的slot数量
./redis-cli -a cc --cluster rebalance host:port
- 根据集群中各个节点设置的权重等平衡slot数量(不执行,只模拟)
./redis-cli -a cc --cluster rebalance --cluster-weight node_id1=5 node_id2=4 node_id3=3 --cluster-simulate host:port
⑬ 导入集群
// 外部Redis实例(host2:port2)导入到集群中的任意一节点
./redis-cli --cluster import host1:port1 --cluster-from host2:port2 --cluster-replace
- 注意:测试下来发现参数–cluster-replace没有用,如果集群中已经包含了某个key,在导入的时候会失败,不会覆盖,只有清空集群key才能导入。
*** Importing 97847 keys from DB 0
Migrating 9223372011174675807 to 192.168.163.132:6381: Source 192.168.163.132:9021 replied with error:
ERR Target instance replied with error: BUSYKEY Target key name already exists
- 如果集群设置了密码,也会导入失败,需要设置集群密码为空才能进行导入(call)
- 通过monitor(9021)的时候发现,在migrate的时候需要密码进行auth认证。
3、事务
Redis 事务:https://zhuanlan.zhihu.com/p/135241403
Redis watch命令:http://c.biancheng.net/view/4544.html
4、时间空间
Redis 过期时间:https://www.cnblogs.com/xiaoxiongcanguan/p/9937433.html
Redis 限制访问频率:https://blog.csdn.net/weixin_44922018/article/details/100181454
Redis 数据淘汰策略:https://blog.csdn.net/qq_37286668/article/details/110631680
5、排序
https://www.cnblogs.com/-wenli/p/13034628.html
6、消息通知
https://blog.csdn.net/men_wen/article/details/62237970
7、管道
https://www.cnblogs.com/xiaoxiongcanguan/p/9954254.html
8、脚本
Redis在2.6版推出了脚本功能,允许开发者使用Lua语言编写脚本传到Redis中执行,在Lua脚本中可以调用大部分的Redis命令。使用脚本的好处:
-
减少网络开销:使用脚本功能完成的操作只需要发送一个请求即可,减少了网络往返时延。
-
原子操作:Redis会将整个脚本作为一个整体执行,中间不会被其他命令插入。换句话说在编写脚本的过程中无需担心会出现竞态条件,也就无需使用事务。事务可以完成的所有功能都可以用脚本来实现。
-
复用:客户端发送的脚本会永久存储在 Redis 中,这就意味着其他客户端(可以是其他语言开发的项目)可以复用这一脚本而不需要使用代码完成同样的逻辑。
Redis中使用Lua脚本:https://zhuanlan.zhihu.com/p/77484377
Redis Lua脚本入门:https://www.cnblogs.com/felordcn/p/13838321.html
Lua 教程:https://www.w3cschool.cn/lua/
9、持久化
Redis 的强劲性能很大程度上是由于其将所有数据都存储在了内存中,然而当Redis重启后,所有存储在内存中的数据就会丢失。在一些情况下,我们会希望 Redis在重启后能够保证数据不丢失,例如:
- 将Redis 作为数据库使用时。
- 将Redis作为缓存服务器,但缓存被穿透后会对性能造成较大影响,所有缓存同时失效会导致缓存雪崩,从而使服务无法响应。
这时我们希望Redis能将数据从内存中以某种形式同步到硬盘中,使得重启后可以根据硬盘中的记录恢复数据。这一过程就是持久化。
Redis支持两种方式的持久化:
- RDB方式:根据指定的规则“定时”将内存中的数据存储在硬盘上
- AOF 方式:在每次执行命令后将命令本身记录下来。
两种持久化方式可以单独使用其中一种,但更多情况下是将二者结合使用。
Redis 持久化详解:https://blog.csdn.net/qq_45722267/article/details/124525345
10、管理
- 可信的环境
- 数据库密码
- 命令命令
- 简单协议
- 统一请求协议
(3)管理工具
- redis-cli
- phpRedisAdmin
- Rdbtools
11、节省时间
精简键名和键值是最直观的减少内存占用的方式,如将键名 very.important.person:20改成VIP:20。当然精简键名一定要把握好尺度,不能单纯为了节约空间而使用不易理解的键名(比如将VIP:20修改为V:20,这样既不易维护,还容易造成命名冲突)。又比如一个存储用户性别的字符串类型键的取值是male和 female,我们可以将其修改成m和f来为每条记录节约几个字节的空间(更好的方法是使用0和1来表示性别)。
https://blog.csdn.net/sinat_33087001/article/details/110387844
12、性能问题
- Master AOF持久化,Master调用BGREWRITEAOF重写AOF文件,AOF在重写的时候会占大量的CPU和内存资源,导致服务load过高,出现短暂服务暂停现象。如果不重写AOF文件,这个持久化方式对性能的影响是最小的,但是AOF文件会不断增大,AOF文件过大会影响Master重启的恢复速度
- Master写内存快照,save命令调度rdbSave函数,会阻塞主线程的工作,当快照比较大时对性能影响是非常大的,会间断性暂停服务,所以Master最好不要写内存快照
- Master最好不要做任何持久化工作,包括内存快照和AOF日志文件,特别是不要启用内存快照做持久化
- 如果数据比较关键,某个Slave开启AOF备份数据,策略为每秒同步一次
- Redis主从复制的性能问题:为了主从复制的速度和连接的稳定性,Master和Slave最好在同一个局域网内
- 尽量避免在压力很大的主库上增加从库
- 主从复制不要用图状结构,用单向链表结构更为稳定,即:Master ⬅ Slave1 ⬅ Slave2 ⬅Slave3 … 这样的结构方便解决单点故障问题,实现Slave对Master的替换。如果Master挂了,可以立刻启用Slave1做Master,其他不变。
13、适合的场景
Redis 适合所有数据in-momory的场景,虽然Redis也提供持久化功能,但实际更多的是一个disk-backed的功能
- 会话缓存(Session Cache) Redis提供持久化,当维护一个不是严格要求一致性的缓存时,避免用户数据丢失
- 全页缓存(FPC) 即使重启了Redis实例,因为有磁盘的持久化,用户也不会看到页面加载速度的下降,这是一个极大改进
- 队列 Reids 提供 list 和 set 操作,这使得Redis能作为一个很好的消息队列平台来使用
- 排行榜/计数器 Redis在内存中对数字进行递增或递减的操作实现的非常好。集合(Set)和有序集合(Sorted Set)执行这些操作的时候变的非常简单,Redis只是正好提供了这两种数据结构
- 发布/订阅
四、集群
一个小型项目使用一台 Redis 服务器已经非常足够了,然而现实中的项目通常需要若干台Redis服务器的支持:
- 从结构上,单个 Redis服务器会发生单点故障,同时一台服务器需要承受所有的请求负载。这就需要为数据生成多个副本并分配在不同的服务器上;
- 从容量上,单个 Redis服务器的内存非常容易成为存储瓶颈,所以需要进行数据分片。
1、主从模式
**(1)概述 **
通过持久化功能,Redis保证了即使在服务器重启的情况下也不会损失(或少量损失)数据。但是由于数据是存储在一台服务器上的,如果这台服务器出现硬盘故障等问题,也会导致数据丢失。为了避免单点故障,通常的做法是将数据库复制多个副本以部署在不同的服务器上,这样即使有一台服务器出现故障,其他服务器依然可以继续提供服务。为此,Redis提供了复制(replication)功能,可以实现当一台数据库中的数据更新后,自动将更新的数据同步到其他数据库上。
Redis主从同步策略:主从数据库刚刚连接的时候,采用全量同步来初始化slave节点。salve正常工作时,采用增量同步来将主服务器发生的写操作同步到从服务器。无论如何,redis首先会尝试进行增量同步,如不成功,要求从数据库进行全量同步。当然,如果有需要,slave 在任何时候都可以发起全量同步。
全量同步:当一个从数据库启动后,会向主数据库发送SYNC命令。主数据库接收到SYNC命令后会开始在后台保存快照(即RDB持久化的过程),并将保存快照期间接收到的命令缓存起来。当快照完成后,Redis会将快照文件和所有缓存的命令发送给从数据库。从数据库收到后,会载入快照文件并执行收到的缓存的命令。
增量复制:从数据库发送 PSYNC命令,格式为PSYNC 主数据库的运行ID 断开前最新的命令偏移量。主数据库收到PSYNC命令后,首先会判断从数据库传送来的运行ID是否和自己的运行ID相同(确保从数据库之前确实是和自己同步的,以免从数据库拿到错误的数据),然后判断从数据库最后同步成功的命令偏移量是否在积压队列中。两个条件都满足的话就可以执行增量复制,并将积压队列中相应的命令发送给从数据库。如果此次重连不满足增量复制的条件,主数据库会进行一次全量同步。
主数据库不需要配置,从数据库的配置文件(redis.conf)中加入slaveof 数据库地址 主数据库端口 即可
- 数据库分类、图结构
- 乐观复制
- 读写分离一致性
- 从数据库持久化
- 无硬盘复制
- 缺点
2、哨兵模式
哨兵的作用是监控Redis系统的运行状态,在主数据库故障时自动将从数据库转换为主数据库。
工作机制:
-
每个sentinel 以每秒钟一次的频率向它所知的master,slave 以及其他sentinel 实例发送一个 PING 命令,如果一个实例距离最后一次有效回复 PING 命令的时间超过
down-after-milliseconds选项所指定的值, 则这个实例会被sentinel标记为主观下线。 -
如果一个master被标记为主观下线,则正在监视这个master的所有sentinel 要以每秒一次的频率确认master的确进入了主观下线状态,当有足够数量的sentinel(大于等于配置文件指定的值)在指定的时间范围内确认master的确进入了主观下线状态, 则master会被标记为客观下线
-
当master被sentinel标记为客观下线时,sentinel向下线的master的所有slave发送 INFO 命令的频率会从 10 秒一次改为 1 秒一次
若没有足够数量的sentinel同意master已经下线,master的客观下线状态就会被移除;若master重新向sentinel的 PING 命令返回有效回复,master的主观下线状态就会被移除
使用sentinel模式的时候,客户端就不要直接连接Redis,而是连接sentinel的ip和port,由sentinel来提供具体的可提供服务的Redis实现,这样当master节点挂掉以后,sentinel就会感知并将新的master节点提供给使用者。
创建一个哨兵配置文件sentinel.conf,内容:
sentinel monitor 主数据库名称 主数据库ip 主数据库port 执行故障恢复操作需要同意的哨兵个数
执行Sentinel进程:
[appuser&localhost bin]$ ./redis-sentinel ../conf/sentinel
配置哨兵监控一个系统时,只需要配置其监控主数据库即可,哨兵会自动发现所有复制该数据库的从数据库
- 监控提醒
- 投票选举
- 自动故障迁移
- 事件
- 特点
- 缺点
3、集群模式
Redis 集群采用P2P模式,是完全去中心化的,不存在中心节点或者代理节点。
Redis 集群是没有统一的入口的,客户端(client)连接集群的时候连接集群中的任意节点(node)即可,集群内部的节点是相互通信的(PING-PONG机制),每个节点都是一个redis实例。
Redis 把所有的 Key 分成了 16384 个 slot,每个 Redis 实例负责其中一部分 slot 。集群中的所有信息(节点、端口、slot等),都通过节点之间定期的数据交换而更新。
Redis集群至少需要3个节点,因为投票容错机制要求超过半数节点认为某个节点挂了该节点才是挂了,所以2个节点无法构成集群。要保证集群的高可用,需要每个节点都有从节点,也就是备份节点,所以Redis集群至少需要6台服务器。
因为我没有那么多服务器,也启动不了那么多虚拟机,所在这里搭建的是伪分布式集群,即一台服务器虚拟运行6个redis实例,修改端口号为(7001-7006),当然实际生产环境的Redis集群搭建和这里是一样的。
👉 第一步:创建6个Redis实例
- 拷贝配置文件
[appuser&localhost ~]$ cd /app/redis/conf
[appuser&localhost conf]$ echo "7001.conf 7002.conf 7003.conf 7004.conf 7005.conf 7006.conf" | xargs -n 1 cp redis.conf
【建议先复制一个7001.conf,在用7001来复制其他配置文件,再使用vim编辑器的全局替换命令(:%s/7001/7002/g)】
- 修改配置文件部分参数,其他参数不变,这里以7001.conf为例:
[appuser&localhost conf]$ vim 7001.conf
# 节点端口号
port 7001
# 绑定当前机器 IP
bind 127.0.0.1
# Redis后台运行
daemonize yes
# 数据文件存放位置
dir /app/redis-cluster/data
# pid 7001和port要对应
# pidfile:包含进程标识号(pid)的文件,该文件存储在文件系统定义明确的位置,因此允许其他程序找出正在运行的脚本的pid。
pidfile /var/run/redis_7001.pid
# 日志文件
logfile "/app/redis-cluster/logs/7001.log"
# 启动集群模式
cluster-enabled yes
# 集群的配置 配置文件首次启动自动生成 7000,7001,7002
cluster-config-file nodes_7001.conf
# 请求超时 默认15秒,可自行设置
cluster-node-timeout 15000
# 是否需要每个节点都可用,集群才算可用,关闭
cluster-require-full-coverage no
# aof日志开启 有需要就开启,它会每次写操作都记录一条日志
appendonly yes
# 密码详解:https://blog.csdn.net/damanchen/article/details/100584275
masterauth 123456@rds
requirepass 123456@rds
- 写个启动脚本用来启动Redis实例:
[appuser@localhost conf]$ cd ../script
[appuser@localhost script]$ vim start-cluster.sh
# 删除 data文件夹下的 appendonly.aof dump.rdb nodes-7005.conf
rm -rf ../data/*
# 启动服务
cd ../bin
./redis-server ../conf/7001.conf
./redis-server ../conf/7002.conf
./redis-server ../conf/7003.conf
./redis-server ../conf/7004.conf
./redis-server ../conf/7005.conf
./redis-server ../conf/7006.conf
# 给脚本权限并执行
[appuser@localhost script]$ chmod 764 start-cluster.sh
[appuser@localhost script]$ ./start-cluster.sh
- 查看Redis服务,此时集群处于失败状态,各节点互相直接发现不了,而且还没有可存储的位置,即slot(槽)没有分配:
[appuser@localhost script]$ ps -ef |grep redis
appuser 42398 1 0 15:19 ? 00:00:00 ./redis-server 127.0.0.1:7001 [cluster]
appuser 42400 1 0 15:19 ? 00:00:00 ./redis-server 127.0.0.1:7002 [<