Aurora 64B/66B IP概述
介绍
Aurora 8B/10B 内核支持 AMBA协议、AXI4-Stream 用户接口。 该内核使用 Zynq、Artix-7、Kintex-7 和 Virtex-7 系列、UltraScale和 UltraScale 实现系列高速串行收发器 Aurora 8B/10B 协议。
特点
- 吞吐量范围为 480 Mb/s 至 84.48 Gb/s 通用数据通道。
- 支持多达 16 连续键合 7 系列 GTX/GTH、UltraScale GTH 或 UltraScale GTH 多达四个键合收发器 GTP 收发器。
- Aurora 8B/ 符合 10B 协议规范 v2.3。
- 资源成本低。
- 易于使用的基础 AXI4-Stream 帧(或流)和流控接口。
- 通道的自动初始化和维护。
- 全双工或单工操作。
- 16 位加扰器/解扰器。
- 用户数据 16 位或 32 位循环冗余校验 (CRC)。
- 热插拔逻辑。
- 可配置的 DRP/INIT 时钟。
- GTREFCLK 和内核 INIT_CLK 单/差分时钟选项。
IP概述
Vivado具有可配置数据路径宽度的工具 Aurora 8B/10B 核生成源代码。 内核可以是单工或全双工的,并具有两个简单的用户界面之一和可选的流量控制。Aurora 8B/10B 通道使用结构如下图所示,是高速串行通信的可扩展、轻量级链路层协议。 该协议是开放的,可以使用 Xilinx FPGA 实现技术。 该协议通常用于使用一个或多个收发器在设备之间传输数据,需要简单、低成本和高速数据通道。
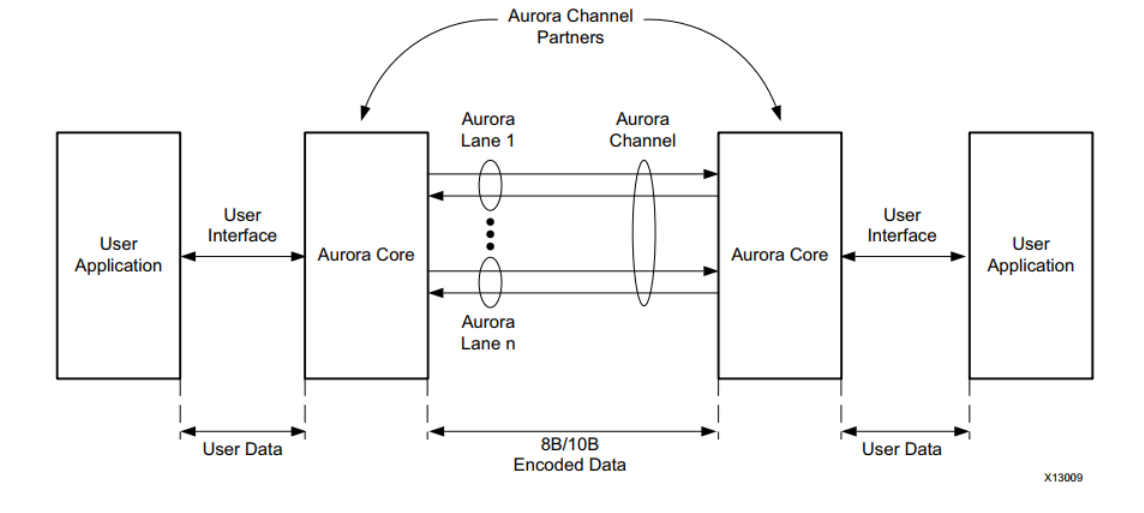
Aurora 8B/10B 连接到内核 Aurora 通道将自动初始化通道,并以帧或数据流的形式在通道中自由传输数据。
有效数据字节之间的间隙会自动填充空闲以保持锁定并防止过度的电磁干扰。 流量控制可用于降低传入数据的速度或通过通道发送短的高优先级信息。 流量是单一的,无休止的帧。 在没有数据的情况下,传输空闲来维持链路活动。 Aurora 8B/10B 内核使用 8B/10B 编码规则检测单比特和大多数多比特错误。 过多的位错、断开连接或设备故障会导致内核复位,并试图重新初始化新通道。
应用
Aurora 8B/10B 内核资源成本低,吞吐量可扩展,数据接口灵活,可用于各种应用。 核心应用示例包括:
- 芯片链接到芯片:用高速串行连接代替芯片之间的并行连接可以显著减少 PCB 上所需的走线和层数。 内核最低 FPGA 提供使用资源成本 GTP、GTX 和 GTH 收发器所需的逻辑。
- :8.内核使用标准B/10B 编码使其与许多现有的电缆和背板硬件标准兼容。 Aurora 8B/10B 为了在新的高性能系统中使用廉价的传统硬件,内核可以扩展线速和通道宽度。
- :Aurora 该协议提供了实施单向通道初始化的替代方法,可以在没有反向通道的情况下使用 GTP、GTX 和 GTH 收发器,降低未使用全双工资源造成的成本。
内核结构
下图显示了 Aurora 8B/10B 实现内核的框图。
Aurora 8B/10B 内核的主要功能模块有:
- :每个 GTP、GTX 或 GTH 收发器(以下简称收发器)由通道逻辑模块的实例驱动,对每个单独的收发器进行初始化,处理编码,解码和错误检测控制字符。
- :全球逻辑模块执行渠道的初始绑定和验证阶段。 模块在运行过程中生成 Aurora 协议所需的随机空闲字符监控所有通道逻辑模块的错误。
- :AXI4-Stream RX 用户接口将数据从通道移动到应用程序,并执行流量控制功能。
- :AXI4-Stream TX 用户接口将数据从应用程序移动到通道,并执行流量控制 TX 功能。 内核嵌入标准时钟补偿模块。 该模块控制时钟补偿 (CC) 定期传输字符。
简述延迟性能
本节概述了 Aurora 8B/10B 内核 AXI4-Stream 每个通道都有用户界面 2 字节和每个通道 4 字节设计的 user_clk 预期周期延迟。 为说明延迟,Aurora 8B/10B 该模块分为收发器逻辑和协议引擎 (PE) 逻辑,后者在 FPGA 在可编程逻辑中实现。下图显示了默认配置的数据路径延迟。 由于设计中使用的收发器和 IP 配置而异。
在默认内核配置的功能模拟中,从 s_axi_tx_tvalid 到 m_axi_rx_tvalid 两字节帧设计的最小延迟约为 37 个 user_clk 周期见下图:
从 s_axi_tx_tvalid 到 m_axi_rx_tvalid 默认四字节帧设计的最小延迟约为 41 个 user_clk 周期。流水线延迟旨在保持时钟速度。 如果没有依赖性,请检查是否可以通过其他可选功能添加延迟。
吞吐量性能简述
Aurora 8B/10B 核吞吐量取决于收发器的数量和目标线速率。 设计到单通道 16 通道设计的吞吐量分别从 0.4 Gb/s 到 84.48 Gb/s 不等。 使用吞吐量 Aurora 8B/10B 协议编码的 20% 开销和 0.5 Gb/s 至 6.6 Gb/s 计算出线速范围。
端口描述
用于生成每一个 Aurora 8B/10B 内核的参数决定了可用于特定内核的接口。 Little Endian Support 选项时使用 [n:0] 总线格式。选择支持 Big Endian 选项时使用 [0:n] 总线格式。除非另有说明,端口一般为高电平有效。
用户接口
用户接口 Aurora 8B/10B 内核可以由帧或流式用户数据接口生成。 该接口包括流式传输或成帧数据传输所需的所有端口。帧用户用户界面 AMBA AXI4-Stream 协议规范,并包传输和接收帧用户数据所需的信号。流接口允许在没有帧分隔符的情况下发送数据,操作更简单,使用的资源比帧接口少。
顶层架构
Aurora 8B/10B 内核顶层文件例化了通道逻辑模块,TX 和 RX AXI4-Stream 包装模块、全球逻辑模块和收发器。 时钟、复位电路、帧生成器和检查器模块也在示例设计中实例化。下图显示了双工配置 Aurora 8B/10B 内核顶层。
AXI4-Stream Bit Ordering (AXI4-Stream 位排序)
Aurora 8B/10B 内核采用升序排列。 它们首先发送和接收最高有效字节的最高有效位。 下图显示了 Aurora 8B/10B 内核的 AXI4-Stream 数据接口的 n 字节示例的组织结构。
用户接口端口
下表列出了双工和单工的内核 AXI4-Stream TX 和 RX 数据端口说明。
| 名称 | 方向 | 时钟域 | 描述 |
|---|---|---|---|
| s_axi_tx_tdata[0:(8n–1)] or s_axi_tx_tdata[(8n–1):0] | Input | user_clk | 传出数据。 作为车道数 x 车道宽度。 n 是字节数的计算。 |
| s_axi_tx_tready | Output | user_clk | 当来自源的信号被接受并且输出数据准备好发送时断言。 |
| s_axi_tx_tlast | Input | user_clk | 表示帧结束。 如果选择了流接口选项,则此端口不可用。 |
| s_axi_tx_tkeep[0:(n–1)] or s_axi_tx_tkeep[(n–1):0] | Input | user_clk | 指定最后一个数据节拍中的有效字节数; 仅在 s_axi_tx_tlast 被断言时有效。 s_axi_tx_tkeep 是字节限定符,指示 s_axi_tx_tdata 的关联字节的内容是否有效。 Aurora 8B/10B 内核期望数据从 LSB 连续填充到 MSB。 不能有无效字节与有效 s_axi_tx_tdata 总线交错。 如果选择了流接口选项,则此端口不可用。 |
| s_axi_tx_tvalid | Input | user_clk | 当传出 AXI4-Stream 信号或来自源的信号有效时置位。 |
| 名称 | 方向 | 时钟域 | 描述 |
|---|---|---|---|
| m_axi_rx_tdata[0:8(n–1)] or m_axi_rx_tdata[8(n–1):0] | Output | user_clk | 来自通道的传入数据(升序位顺序)。 |
| m_axi_rx_tlast | Output | user_clk | 表示传入帧的结束(在单个用户时钟周期内声明)。如果选择了流接口选项,则此端口不可用。 |
| m_axi_rx_tkeep[0:(n–1)] or m_axi_rx_tkeep[(n–1):0] | Output | user_clk | 指定最后一个数据节拍中的有效字节数。如果选择了流接口选项,则此端口不可用。 |
| m_axi_rx_tvalid | Output | user_clk | 当来自 Aurora 8B/10B 内核的传出数据和控制信号或数据和控制信号有效时置位。 |
帧接口
下图显示了 Aurora 8B/10B 内核的帧用户接口,带有用于 TX 和 RX 数据的 AXI4-Stream 兼容端口。
传输数据
为了传输数据,用户应用程序操纵控制信号使内核执行以下操作:
- 当 s_axi_tx_tvalid 和 s_axi_tx_tready 信号置位时,从 s_axi_tx_tdata 总线上的用户接口获取数据。
- 通过Aurora 8B/10B 通道中的通道串行化数据。
- 使用s_axi_tx_tvalid 信号传输数据。 用户应用程序可以置低 s_axi_tx_tvalid 以在线路上插入空闲(引入停顿或暂停)。
- 暂停数据(即插入空闲)(s_axi_tx_tvalid 无效)。
当内核接收数据时,它会执行以下操作:
- 检测并丢弃控制字节(空闲、时钟补偿、通道开始 PDU (SCP)、通道结束协议数据单元 (ECPDU) 和 PAD。
- 断言成帧信号 (m_axi_rx_tlast) 并指定最后一个数据节拍中的有效字节数 (m_axi_rx_tkeep)。
- 从通道中恢复数据。
- 通过置位m_axi_rx_tvalid 信号,拼接数据传递给m_axi_rx_tdata 总线上的用户接口。
AXI4-Stream 数据仅在成帧时有效。 帧外的数据被忽略。
Aurora 8B/10B 帧
TX 子模块将通过 TX 接口接收到的每个用户帧转换为 Aurora 8B/10B 帧。 帧开始 (SOF) 通过在帧开始处添加 2 字节 SCP 代码组来指示。 帧结束 (EOF) 通过在帧末尾添加一个 2 字节的通道结束协议 (ECP) 代码组来指示。 只要数据不可用,就会插入空闲代码组。 代码组是 8B/10B 编码字节对,所有数据都作为代码组发送,因此具有奇数字节的用户帧在帧末尾附加一个称为 PAD 的控制字符以填充最终代码组。 下表显示了具有偶数个数据字节的典型 Aurora 8B/10B 帧。
长度
用户应用程序通过操纵 s_axi_tx_tvalid 和 s_axi_tx_tlast 信号来控制通道帧长度。 Aurora 8B/10B 内核分别以帧开始和帧结束有序集 /SCP/ 和 /ECP/ 进行响应。
传输示例
简单数据传输
下图显示了在 n 字节宽的 AXI4-Stream 接口上进行简单数据传输的示例。
在这种情况下,发送的数据量为 3n 字节,因此需要三个数据节拍。 s_axi_tx_tready 置位,表示 AXI4-Stream 接口已准备好传输数据。 用户应用程序在前 n 个字节期间置位 s_axi_tx_tvalid 以开始数据传输。 /SCP/ 有序集放置在通道的前两个字节上,以指示帧的开始。 然后将前 n–2 个数据字节放在通道上。 由于 /SCP/ 所需的偏移量,每个数据节拍中的最后两个字节总是延迟一个周期,并在通道的下一个节拍的前两个字节上传输。
为了结束数据传输,用户应用程序在 s_axi_tx_tkeep 总线上置位 s_axi_tx_tlast、最后一个数据字节和适当的值。 在此示例中,s_axi_tx_tkeep 在波形中设置为 N,以指示所有字节在最后一个数据节拍中均有效。 当 s_axi_tx_tlast 被置位时,s_axi_tx_tready 在下一个时钟周期被置低,内核使用数据流中的间隙发送最终的偏移数据字节和 /ECP/ 有序集,指示帧结束。 s_axi_tx_tready 在下一个周期重新置位以允许数据传输继续。
使用填充的数据传输
下图显示了一个需要使用填充的 (3n–1) 字节数据传输示例。
Aurora 8B/10B 内核根据协议要求为具有奇数字节的帧附加填充字符。 传输 3n–1 个数据字节需要两个完整的 n 字节数据字和一个部分数据字。 在此示例中,s_axi_tx_tkeep 设置为 N–1 以指示最后一个数据字中的 n–1 个有效字节。
带暂停的数据传输
下图显示了用户接口如何在帧传输期间暂停数据传输。 在此示例中,用户应用程序在前 n 个字节之后通过置低 s_axi_tx_tvalid 暂停数据流,并改为传输空闲。 暂停一直持续到 s_axi_tx_tvalid 被取消断言。
带时钟补偿的数据传输
Aurora 8B/10B 内核在发送时钟补偿序列时会自动中断数据传输。 时钟补偿序列每 10,000 个字节对每个通道施加 12 个字节的开销。下图显示了 Aurora 8B/10B 内核如何在时钟补偿序列期间暂停数据传输。
由于每通道每 10,000 字节需要进行时钟补偿(每通道 2 字节设计需要 5,000 个时钟;每通道 4 字节设计需要 2,500 个时钟),因此您无法连续传输数据,也无法连续接收数据。 在时钟补偿期间,数据传输暂停六个或三个时钟周期。
接收数据
RX 子模块没有用于用户数据的内置弹性缓冲区。 因此,RX AXI4-Stream 接口上没有 m_axi_rx_tready 信号。 用户应用程序控制来自 Aurora 8B/10B 通道的数据流的唯一方法是使用IP可选流控制功能之一。
m_axi_rx_tkeep 端口指示每帧最后一个字中的有效字节数。m_axi_rx_tkeep 信号仅在 m_axi_rx_tlast 置位时有效。
Aurora 8B/10B 内核可以随时取消断言 m_axi_rx_tvalid,甚至在一帧期间。即使帧最初是在没有暂停的情况下传输的,内核偶尔也会置低 m_axi_rx_tvalid。 这些停顿是框架字符解码和左对齐过程的结果。
下图显示了一个 3n 字节的接收数据被暂停中断的示例。
数据显示在 m_axi_rx_tdata 总线上。 当前 n 个字节放置在总线上时,m_axi_rx_tvalid 被置位以指示数据已准备好供用户应用程序使用。 内核在第一个数据节拍之后的时钟周期内将 m_axi_rx_tvalid 置低,以指示数据流暂停。暂停后,内核置位 m_axi_rx_tvalid 并继续在 m_axi_rx_tdata 总线上组装剩余数据。 在帧结束时,内核断言 m_axi_rx_tlast。 内核还计算 m_axi_rx_tkeep 总线的值,并根据帧最后一个字中的有效字节总数将其呈现给用户应用程序。
成帧效率
有两个因素会影响 Aurora 8B/10B 内核的成帧效率:
-
帧大小。
-
数据路径的宽度。
CC 序列(每 10,000 字节在每个通道上使用 12 个字节)消耗大约 0.12% 的总信道带宽。
Aurora 8B/10B 内核中的所有字节都以两字节代码组发送。 具有偶数字节的 Aurora 8B/10B 帧有四个字节的开销,两个字节用于 SCP(帧开始)和两个字节用于 ECP(帧结束)。 具有奇数字节的 Aurora 8B/10B 帧具有 5 个字节的开销、4 个字节的成帧开销以及一个用于填充字节的附加字节。
IP仅在通道的特定通道中传输帧定界符。 SCP 仅在最左侧(最重要)的通道中传输,而 ECP 仅在最右侧(最不重要)的通道中传输。 在最后一个有数据的代码组和 ECP 代码组之间的信道中的任何空间都用空闲填充。 结果是降低了设计的资源成本,但以最小的额外吞吐量成本为代价。 尽管 SCP 和 ECP 可以针对额外的吞吐量进行优化,但用户界面施加的每周期单帧限制会使这种改进在大多数情况下无法使用。
使用公式中所示的公式计算任意通道数、任意接口宽度和任意字节数帧的设计效率。该公式包括时钟补偿的开销。
其中:
- E = 指定 PDU 的平均效率。
- n = 用户数据字节数。
- 12n/9988 = 时钟校正开销。
- 4 = SCP + ECP 开销。
- 0.5 = 平均 PAD 开销。
- IDLE = IDLE 开销 = ( w/2) – 1。
- w = 接口宽度。
表 2-4 是根据公式 2-1 计算得出的示例。 它显示了 8 字节、4 通道通道的效率,并说明效率随着通道帧长度的增加而增加。
表 2-5显示了通过四个通道传输 256 字节帧数据时 8 字节 4 通道通道的开销。 由于开始和结束字符以及填充通道所需的空闲,生成的数据单元为 264 字节长。 这相当于发射机开销的 3.03%。 此外,每 10,000 个字节在每个通道上发生一个 12 字节的时钟补偿序列,这会增加少量的开销。 接收器可以处理稍微更有效的数据流,因为它不需要任何空闲模式。
表 2-6 显示了 s_axi_tx_tkeep 的每个值产生的开销。在 Vivado中选择 Little Endian 选项时,s_axi_tx_tkeep 位顺序从 MSB 更改为 LSB。
流接口
下显示了一个配置有流式用户界面的 Aurora 8B/10B 内核示例。
流接口端口
| 名称 | 方向 | 时钟域 | 描述 |
|---|---|---|---|
| s_axi_tx_tdata[0:(8n–1)] or s_axi_tx_tdata[(8n–1):0] | Input | user_clk | 传出数据。 作为车道数 x 车道宽度。 n 是计算的字节数。 |
| s_axi_tx_tready | Output | user_clk | 当来自源的信号被接受并且输出数据准备好发送时断言。 |
| s_axi_tx_tvalid | Input | user_clk | 当传出 AXI4-Stream 信号或来自源的信号有效时置位。 |
| 名称 | 方向 | 时钟域 | 描述 |
|---|---|---|---|
| m_axi_rx_tdata[0:8(n–1)] or m_axi_rx_tdata[8(n–1):0] | Output | user_clk | 来自通道的传入数据(升序位顺序)。 |
| m_axi_rx_tvalid | Output | user_clk | 当来自 Aurora 8B/10B 内核的传出数据和控制信号或数据和控制信号有效时置位。 |
收发数据
流接口允许 Aurora 8B/10B 通道用作管道。 初始化后,通道始终可用于写入,发送时钟补偿序列时除外。 核心数据传输符合 AXI4-Stream 协议。
当 s_axi_tx_tvalid 被置低时,字之间会产生间隙并保留间隙,除非正在传输时钟补偿序列。当数据到达 Aurora 8B/10B 通道的 RX 侧时,它会呈现在 m_axi_rx_tdata 总线上,并且 m_axi_rx_tvalid 被置位。 数据必须立即读取,否则会丢失。 如果这是不可接受的,则必须将缓冲区连接到 RX 接口以保存数据,直到可以使用为止。
传输示例
TX 流数据传输
下图显示了流数据的典型示例。
Aurora 8B/10B 内核通过置位 s_axi_tx_tready 来指示它已准备好传输数据。 一个周期后,用户逻辑通过置位 s_axi_tx_tdata 总线和 s_axi_tx_tvalid 信号来指示它已准备好传输数据。 因为两个就绪信号现在都已置位,所以数据 D0 从用户逻辑传输到 Aurora 8B/10B 内核。 数据 D1 在下一个时钟周期传输。 在此示例中,Aurora 8B/10B 内核将其就绪信号 s_axi_tx_tready 置低,直到下一个时钟周期再次置位 s_axi_tx_tready 信号时才传输数据。 然后用户逻辑在下一个时钟周期将 s_axi_tx_tvalid 置低,直到两个就绪信号都置位后才传输数据。
RX 流数据传输
下图显示了数据传输的接收端。
流量控制
本节介绍如何使用 Aurora 8B/10B 流量控制。 使用帧接口的内核上有两个可选的流控制接口。 本机流量控制 (NFC) 调节全双工通道接收端的数据传输速率。 用户流控制 (UFC) 为控制操作提供高优先级消息。
用户流控制接口
UFC 接口是在生成内核并启用 UFC 时创建的,如下图。
TX 侧的 UFC s_axi_ufc_tx_tvalid 和 s_axi_ufc_tx_tready 端口启动 UFC 消息,3 位 s_axi_ufc_tx_tdata 端口指定消息的长度。断言 s_axi_ufc_tx_tready 后,可以将 UFC 消息提供给数据端口。
UFC 接口的 RX 端由一组 AXI4-Stream 端口组成,允许将 UFC 消息作为帧读取simplex留在支持的方向上发送数据所需的接口。
UFC I/O 端口描述
| 名称 | 方向 | 时钟域 | 描述 |
|---|---|---|---|
| s_axi_ufc_tx_tvalid | Input | user_clk | 断言请求向合作通道发送 UFC 消息。 必须保持直到 s_axi_ufc_tx_tready 被断言。 除非准备好发送整个 UFC 消息,否则不要断言此信号; UFC 消息在开始后不能被中断。 |
| s_axi_ufc_tx_tdata[0:2] or s_axi_ufc_tx_tdata[2:0] | Input | user_clk | 指定发送的 UFC 消息的大小。 SIZE 编码是一个介于 0 和 7 之间的值。 |
| s_axi_ufc_tx_tready | Output | user_clk | 当 Aurora 8B/10B 内核准备好读取 UFC 消息的内容时置位。 在 s_axi_ufc_tx_tready 信号置位后的周期内,s_axi_tx_tdata 端口上的数据被视为 UFC 数据。 s_axi_tx_tdata 数据继续用于填充 UFC 消息,直到经过足够的周期来发送完整的消息。 UFC 循环中未使用的字节将被丢弃。 |
| 名称 | 方向 | 时钟域 | 描述 |
|---|---|---|---|
| m_axi_ufc_rx_tdata[0:(8n–1)] or m_axi_ufc_rx_tdata[(8n–1):0] | Output | user_clk | 来自通道的传入 UFC 消息数据(最大 n = 16 个字节)。 |
| m_axi_ufc_rx_tvalid | Output | user_clk | 当 m_axi_ufc_rx_tdata 端口上的值有效时置位。 |
| m_axi_ufc_rx_tlast | Output | user_clk | 表示传入 UFC 消息的结束。 |
| m_axi_ufc_rx_tkeep[0:(n–1)] or m_axi_ufc_rx_tkeep[(n–1):0] | Output | user_clk | 指定在 UFC 消息的最后一个字的 m_axi_ufc_rx_tdata 端口上显示的有效数据字节数。 仅当 m_axi_ufc_rx_tlast 置位时有效(n = 最大 16 字节)。 |
传输 UFC 消息
UFC 消息可以携带从 2 到 16 的偶数数据字节。用户应用程序通过驱动 s_axi_ufc_tx_tdata 端口上的 SIZE 代码来指定消息的长度。 下表 显示了 UFC 消息的合法 SIZE 代码值。
| SIZE Field Contents | UFC Message Size |
|---|---|
| 000 | 2 bytes |
| 001 | 4 bytes |
| 010 | 6 bytes |
| 011 | 8 bytes |
| 100 | 10 bytes |
| 101 | 12 bytes |
| 110 | 14 bytes |
| 111 | 16 bytes |
要发送 UFC 消息,用户应用程序在使用所需 SIZE 代码驱动 s_axi_ufc_tx_tdata 端口时断言 s_axi_ufc_tx_tvalid。 s_axi_ufc_tx_tvalid 信号必须保持到 Aurora 8B/10B 内核置位 s_axi_ufc_tx_tready 信号。UFC 消息的数据必须放在 s_axi_tx_tdata 端口上,从 s_axi_ufc_tx_tready 置位后的第一个周期开始。 当 s_axi_tx_tdata 端口用于 UFC 数据时,内核将 s_axi_tx_tready 置低。只有在完成当前的 UFC 请求后才能发出 UFC 请求; IP 可能不支持背靠背的 UFC 请求。
下图显示了一个用于将 TX_D 从发送常规数据切换到 UFC 数据的电路。
表 2-9 显示了根据 AXI4-Stream 数据接口的宽度传输不同大小的 UFC 消息所需的周期数。 在所有消息数据可用之前,不应启动 UFC 消息。 与常规数据不同,UFC 消息在 s_axi_ufc_tx_tready 被断言后不能被中断,直到当前 UFC 消息完成。
传输单周期 UFC 消息
传输单周期 UFC 消息的过程如下图所示。在这种情况下,在 4 字节接口上发送 4 字节消息。s_axi_ufc_tx_tready 信号在两个周期内被置低。 Aurora 8B/10B 内核使用数据流中的这个间隙来传输 UFC 标头和消息数据。
传输多周期 UFC 消息
传输两周期 UFC 消息的过程如下图所示。 在这种情况下,用户应用程序使用 2 字节接口发送 4 字节消息。s_axi_tx_tready 断言三个周期:一个周期用于在 s_axi_ufc_tx_tready 周期期间发送的 UFC 标头,两个周期用于 UFC 数据。
接收UFC消息
当 Aurora 8B/10B 内核接收到 UFC 消息时,它会通过专用的 UFC AXI4-Stream 接口将数据传递给用户应用程序。 数据呈现在 m_axi_ufc_rx_tdata 端口上; m_axi_ufc_rx_tvalid 表示消息数据的开始,m_axi_ufc_rx_tlast 表示结束。 m_axi_ufc_rx_tkeep 用于显示消息的最后一个周期内 m_axi_ufc_rx_tdata 上的有效字节数。
接收单周期 UFC 消息
下图显示了具有 4 字节数据接口的 Aurora 8B/10B 内核接收 4 字节 UFC 消息。 内核通过置位 m_axi_ufc_rx_tvalid 和 m_axi_ufc_rx_tlast 来向用户应用程序提供此数据以指示单个周期帧。m_axi_ufc_rx_tkeep 设置为 4’hF,表示只有接口的四个最高有效字节有效。
接收多周期 UFC 消息
下图显示了具有 4 字节接口的 Aurora 8B/10B 内核接收 8 字节消息。生成的帧长两个周期,m_axi_ufc_rx_tkeep 在第二个周期设置为 4’hF,表示数据的所有四个字节都有效。
Native Flow Control
Aurora 8B/10B 协议包括本机流量控制 (NFC) 接口,如下图所示。
该接口允许接收器通过指定必须放入数据流中的空闲数据节拍数来控制接收数据的速率。 甚至可以通过请求发送器暂时仅发送空闲 (XOFF) 来完全关闭数据流。NFC 通常用于防止 FIFO 溢出情况。
原生流控制接口
NFC 接口是在生成内核并启用 NFC 选项时创建的。 此接口包括用于发送 NFC 消息的请求 (s_axi_nfc_tx_tvalid) 和确认(s_axi_nfc_tx_tready) 端口,以及用于指定请求的空闲周期数的 4 位 s_axi_nfc_tx_tdata 端口。
下表列出了仅在全双工 Aurora 8B/10B 内核中可用的 NFC 接口端口。
NFC I/O Ports
| Name | Direction | Clock Domain | Description |
|---|---|---|---|
| s_axi_nfc_tx_tready | Output | user_clk | 当核心接受 NFC 请求时置位。 |
| s_axi_nfc_tx_tdata[0:3] or s_axi_nfc_tx_tdata[3:0] | Input | user_clk | 指示连接通道在收到 NFC 消息时必须发送的 PAUSE 空闲数。 必须保持直到 s_axi_nfc_tx_tready 被断言。 |
| s_axi_nfc_tx_tvalid | Input | user_clk | 断言请求向连接通道发送 NFC 消息。 必须保持直到 s_axi_nfc_tx_tready 被断言。 |
| Name | Direction | Clock Domain | Description |
|---|---|---|---|
| m_axi_nfc_tx_tvalid | Output | user_clk | 表示收到来自合作伙伴的 NFC 消息。 |
| m_axi_nfc_tx_tdata[0:3] or m_axi_nfc_tx_tdata[3:0] | Output | user_clk | 表示接收到的 NFC 消息的 PAUSE 值。 应使用 m_axi_nfc_tx_tvalid 对该端口进行采样。 |
下表显示了本机流量控制 (NFC) 的代码。 这些值在大端格式的 [0:3] 位和小端格式的 [3:0] 位上驱动。
| s_axi_nfc_tx_tdata | Idle Cycles Requested |
|---|---|
| 0000 | 0 (XON) |
| 0001 | 2 |
| 0010 | 4 |
| 0011 | 8 |
| 0100 | 16 |
| 0101 | 32 |
| 0110 | 64 |
| 0111 | 128 |
| 1000 | 256 |
| 1001 to 1110 | Reserved |
| 1111 | Infinite (XOFF) |
用户应用程序断言 s_axi_nfc_tx_tvalid 并将 NFC 代码写入 s_axi_nfc_tx_tdata。 NFC 代码指示通道合作伙伴应在其 TX 数据流中插入的最小空闲周期数。 用户应用程序必须保持 s_axi_nfc_tx_tvalid 和 s_axi_nfc_tx_tdata,直到 s_axi_nfc_tx_tready 被置位。 Aurora 8B/10B 内核在发送 NFC 消息时无法传输数据。s_axi_tx_tready 总是在 s_axi_nfc_tx_tready 断言之后的周期被取消断言。
发送 NFC 消息示例
下图显示了用户应用程序向通道伙伴发送 NFC 消息时的传输时序示例。s_axi_nfc_tx_tready 信号被置低一个周期(假设 n 至少为 2)以在放置 NFC 消息的数据流中创建间隙。
接收插入了 NFC 空闲的消息示例
下图显示了接收到 NFC 消息时 TX 用户界面上的信号示例。 在这种情况下,NFC 消息的代码为 0001,请求两个空闲数据节拍。 核心在用户界面上置低 s_axi_tx_tready,直到发送了足够的空闲来满足请求。 在此示例中,内核在立即 NFC 模式下运行,其中立即插入 NFC 空闲。 Aurora 8B/10B 内核也可以在完成模式下运行,其中 NFC 空闲仅插入帧之间。 如果完成模式核心在传输帧时收到 NFC 消息,它会在取消断言 s_axi_tx_tready 以插入空闲之前完成传输帧。
状态、控制和收发器接口
Aurora 8B/10B 内核的状态和控制端口允许应用程序监控通道并使用收发器的内置功能。 本节提供状态和控制接口、收发器串行 I/O 接口以及专用于单工模块的边带初始化端口的图表和端口说明。
状态和控制端口
下表描述了 Aurora 8B/10B 内核的每个状态和控制端口的功能。
| Name | Direction | Clock Domain | Description |
|---|---|---|---|
| channel_up/ tx_channel_up/ rx_channel_up | Output | user_clk | 当 Aurora 8B/10B 通道初始化完成并且通道准备好进行数据传输时置位。 tx_channel_up 和 rx_channel_up 仅适用于它们各自的单工内核。 |
| lane_up[0:m–1]/ tx_lane_up[0:m–1]/ rx_lane_up[0:m–1] | Output | user_clk | 通道初始化成功后为每个通道置位,每个位代表一个通道。 tx_lane_up[0:(m–1)] 和 rx_lane_up[0:(m–1)] 仅适用于它们各自的单工核。m 是收发器的数量。 |
| frame_err | Output | user_clk | 检测到通道帧/协议错误。 该端口被断言为单个时钟。 不适用于单工 TX 内核。 |
| hard_err/ tx_hard_err/ rx_hard_err | Output | user_clk | 检测到硬错误(在 Aurora 8B/10B 内核复位之前一直有效)。 tx_hard_err 和 rx_hard_err 仅适用于它们各自的单工内核。 |
| soft_err | Output | user_clk | 在传入的串行流中检测到软错误。 在单工 TX 内核上不可用。 |
| reset/ tx_system_reset/ rx_system_reset | Input | async | 重置 Aurora 8B/10B 内核(高电平有效)。 该信号必须被断言至少六个 user_clk 周期。 tx_system_reset 和 rx_system_reset 仅适用于它们各自的单工内核。 |
| gt_reset | Input | async | 收发器的复位信号通过去抖动器连接到顶层。 gt_reset 端口应在模块首次在硬件上电时置位。 这系统地重置了收发器的所有物理编码子层 (PCS) 和物理介质附件 (PMA) 子组件。 该信号使用 init_clk_in 进行去抖动,并且必须在六个 init_clk_in 周期内置位。 |
| link_reset_out | Output | init_clk | 如果热插拔计数到期,则驱动为高电平。 |
| init_clk_in | Input | NA | init_clk_in 端口是必需的,因为当 gt_reset 置位时 user_clk 停止。 建议为 init_clk_in 选择的频率低于 GT 参考时钟输入频率。 |
| tx_aligned | Input | user_clk | 当 RX 通道完成所有通道的通道初始化时置位。 通常连接到 rx_aligned。 |
| tx_bonded | Input | user_clk | 当 RX 通道完成通道绑定时置位。 单通道通道不需要。 通常连接到 rx_bonded。 |
| tx_verify | Input | user_clk | 当 RX 通道完成验证时置位。 通常连接到 rx_verify。 |
| tx_reset | Input | user_clk | 由于 RX 通道的初始化状态而需要复位时置位。 该信号必须与 user_clk 同步,并且必须在至少一个 user_clk 周期内被置位。 通常连接到 rx_reset。 |
| rx_aligned | Output | user_clk | 当 RX 模块完成通道初始化时置位。 通常连接到 tx_aligned。 |
| rx_bonded | Output | user_clk | 当 RX 模块完成通道绑定时置位。 不用于单通道通道。 通常连接到 tx_bonded。 |
| rx_verify | Output | user_clk | 当 RX 模块完成验证时置位。 通常连接到 tx_verify。 |
| rx_reset | Output | user_clk | 当 RX 模块需要 TX 模块重新初始化初始化时置位。 通常连接到 tx_reset。 |
全双工内核
全双工状态和控制端口
全双工内核提供 TX 和 RX Aurora 8B/10B 通道连接。 下图显示了全双工 Aurora 8B/10B 内核的状态和控制界面。
错误状态信号
设备问题和通道噪声可能导致 Aurora 8B/10B 通道操作期间出现错误。 8B/10B 编码允许 Aurora 8B/10B 内核检测通道中发生的所有单位错误和大多数多位错误,并在每个周期置位 soft_err。
TX 单工内核不包括 soft_err 端口。 除非存在设备问题,否则假定所有传输数据在传输时都是正确的。该内核还监视每个收发器的硬件错误,例如缓冲区溢出/下溢和失锁,并断言 hard_err 信号。 使用 rx_hard_err 信号报告单工内核中的 RX 端硬错误。 灾难性的硬件错误也可以表现为软错误的爆发。 内核使用 Aurora 8B/10B 协议规范 描述的漏桶算法来检测短时间内发生的大量软错误,并断言 hard_err 或 rx_hard_err 信号。
每当检测到硬错误时,内核都会自动重置并尝试重新初始化。 这允许通道重新初始化并在导致硬错误的硬件问题得到解决后立即重新建立。 除非在短时间内发生足够多的软错误,否则不会导致复位。
具有 AXI4-Stream 数据接口的 Aurora 8B/10B 内核还可以检测 Aurora 8B/10B 帧中的错误并断言 frame_err 信号。 帧错误可以是没有数据的帧、连续的帧开始符号和连续的帧结束符号。 该信号不适用于单工 TX 内核。 当可用时,该信号通常在接近 soft_err 断言时被断言,软错误是帧错误的主要原因。 下表总结了 Aurora 8B/10B 内核可以检测到的错误情况以及用于提醒用户应用程序的错误信号。
全双工初始化
全双工内核在上电、复位或硬错误后自动初始化,并执行 Aurora 8B/10B 初始化程序,直到通道准备好使用。 lane_up 总线指示通道中的哪些通道已完成通道初始化过程。 该信号可用于帮助调试多通道通道中的设备问题。
只有在内核完成整个初始化过程后才会断言 channel_up。在声明 channel_up 之前,Aurora 8B/10B 内核无法接收数据。 仅应使用用户界面上的 m_axi_rx_tvalid 信号来限定传入数据。channel_up 可以反转并用于复位驱动全双工通道的 TX 侧的模块,因为在 channel_up 之后才能进行传输。 如果用户应用程序模块需要在数据接收之前复位,可以反转并使用其中一个 lane_up 信号。 直到所有 lane_up 信号被置位后才能接收数据。
单工内核
单工 TX 状态和控制端口
单工 TX 内核允许用户应用程序将数据传输到单工 RX 内核。 他们没有 RX 连接。 下图显示了单工 TX 内核的状态和控制接口。
单工 RX 状态和控制端口
单工 RX 内核允许用户应用程序从单工 TX 内核接收数据。下图显示了单工 RX 内核的状态和控制接口。
Simplex 初始化
Simplex 内核不依赖于来自 Aurora 8B/10B 通道的信号进行初始化。相反,单工通道的 TX 和 RX 侧通过一组边带初始化信号传达其初始化状态:对齐、绑定、验证和复位; 一组用于带有 TX_ 前缀的 TX 侧,一组用于带有 RX_ 前缀的 RX 侧。 绑定端口仅用于多通道内核。使用单边初始化信号初始化单工模块的方法有两种:
- 将信息从 RX 边带初始化端口发送到 TX 边带初始化端口。
- 使用定时初始化间隔独立于 RX 边带初始化端口驱动 TX 边带初始化端口。
使用反向通道
反向通道是在 RX 和 TX 之间没有通道的情况下初始化和维护单工通道的最安全方法。 反向通道只需将消息传递到 TX 侧,以指示在信号变化时断言哪个边带初始化信号。包含在 example_design 目录中的带有单工 Aurora 8B/10B 内核的示例设计显示了一个简单的侧通道,该通道在器件上使用了三个或四个 I/O 引脚。
使用定时器
如果反向通道是不可能的,串行通道可以通过使用一组定时器驱动 TX 单工初始化来初始化。 必须仔细设计定时器以满足系统的需要,因为初始化的平均时间取决于许多特定于通道的条件,例如时钟速率、通道延迟、通道之间的偏移和噪声。
C_ALIGNED_TIMER、C_BONDED_TIMER 和 C_VERIFY_TIMER 是分别用于断言 tx_aligned、tx_bonded 和 tx_verify 信号的定时器。 这些计时器使用从极端情况功能仿真中获得并在 <component name>_core 模块中实现的最坏情况值。
Aurora 8B/10B 模块中的一些初始化逻辑使用看门狗定时器来防止死锁。 这些看门狗定时器用于通道的 RX 侧,可能会干扰 TX 初始化定时器的正常运行。 如果 RX 单工模块从对齐、绑定或验证变为复位,请确保这不是因为 TX 逻辑在这些状态之一中花费了太多时间。 如果需要特别长的定时器来满足系统的需要,可以通过编辑模块来调整看门狗定时器。 在大多数情况下,这不是必需的,也不建议这样做。
Aurora 8B/10B 通道通常仅在发生故障时才会重新初始化。 当没有可用的反向通道时,对于大多数错误来说,事件触发的重新初始化是不可能的,因为通常情况下,RX 侧检测到故障,而条件必须由 TX 侧处理。 解决方案是让定时器驱动的 TX 单工模块定期重新初始化。 如果发生灾难性错误,通道将在下一个重新初始化周期到来后重置并再次运行。 系统设计人员应平衡重新初始化所需的平均时间与系统可以容忍不工作通道的最长时间,以确定系统的最佳重新初始化周期。
收发器接口
该接口包括收发器的串行 I/O 端口,以及控制和状态。
| Name | Direction | Clock Domain | Description |
|---|---|---|---|
| rxp[0:m–1] | Input | RX Serial Clock | 正差分串行数据输入引脚。 |
| rxn[0:m–1] | Input | RX Serial Clock | 负差分串行数据输入引脚。 |
| txp[0:m–1] | Output | TX Serial Clock | 正差分串行数据输入引脚。 |
| txn[0:m–1] | Output | TX Serial Clock | 负差分串行数据输入引脚。 |
| power_down | Input | user_clk | 驱动收发器的掉电输入。 如需更多信息,请参阅适用的收发器用户指南。 |
| loopback[2:0] | Input | user_clk | loopback[2:0] 端口在收发器的正常操作和不同的环回模式之间进行选择。 |
| tx_resetdone_out | Output | user_clk | 收发器的 TXRESETDONE 信号。 |
| rx_resetdone_out | Output | user_clk | 收发器的 RXRESETDONE 信号。 |
| tx_lock | Output | user_clk | 指示传入的串行收发器 refclk 被收发器锁相环 (PLL) 锁定。 |
时钟接口
时钟接口具有用于收发器参考时钟的端口,以及 Aurora 8B/10B 内核与应用逻辑共享的并行时钟。下表描述了 Aurora 8B/10B 内核时钟端口。
| Clock Ports | Direction | Description |
|---|---|---|
| pll_not_locked | Input | 如果使用 PLL 为 Aurora 8B/10B 内核生成时钟,则 pll_not_locked 信号应连接到 PLL 的锁定信号的反相。 如果 PLL 不用于为 Aurora 8B/10B 内核生成时钟信号,请将 pll_not_locked 接地。 |
| user_clk | Input | 由 Aurora 8B/10B 内核和用户应用程序共享的并行时钟。 user_clk 和 sync_clk 是 tx_out_clk 驱动的 PLL 或 BUFG 的输出。 这些时钟生成可在 <component name>_clock_module 文件中找到。user_clk 作为收发器的 txusrclk2 输入。 |
| sync_clk | Input | 收发器内部同步逻辑使用的并行时钟。 sync_clk 作为收发器的 txusrclk 输入。 |
| gt_refclk | Input | 通过 IBUFDS_GTE 馈送的 gt_refclk (clkp/clkn) po 收发器参考时钟。 |
| gt0_pll0outclk_in/ gt1_pll0outclk_in | Input | 该端口应连接到 GTPE2_COMMON 生成的 PLL0OUTCLK/PLL1OUTCLK 时钟输出。 该端口在内部连接到 GTPE2_CHANNEL 原语上的 PLL0CLK/PLL1CLK 端口。 |
| gt0_pll0outrefclk_in/ gt0_pll1outrefclk_in | Input | 该端口应连接到 GTPE2_COMMON 生成的 PLL0OUTREFCLK/PLL1OUTREFCLK 时钟输出。 该端口在内部连接到 GTPE2_CHANNEL 原语上的 PLL0REFCLK/PLL1REFCLK 端口。 |
| quad1_common_lock_in | Input | GTPE2_COMMON PLL 锁定输入端口。 |
下表提供了有关由于选择共享逻辑选项而导致的端口更改的详细信息。
| Name | Direction | Description | Remarks |
|---|---|---|---|
| gt_refclk1_p gt_refclk1_n | Input | Transceiver reference clock 1 | 选择内核中的共享逻辑时启用。 单端 GT REFCLK 选项提供单端 gtrefclk1 输入。 |
| gt_refclk2_p gt_refclk2_n | Input | Transceiver reference clock 2 | 选择内核中的共享逻辑时启用。 单端 GT REFCLK 选项提供单端 gtrefclk2 输入。 |
| gt_refclk1_out | Output | 收发器参考时钟 1 的 IBUFDS_GTE2 输出 | 选择内核中的共享逻辑时启用。 不适用于单端 GT REFCLK 选项。 |
| gt_refclk2_out | Output | 收发器参考时钟 2 的 IBUFDS_GTE2 输出 | 选择内核中的共享逻辑时启用。 不适用于单端 GT REFCLK 选项。 |
| user_clk_out | Output | Aurora 8B/10B 内核共享的并行时钟 | 选择内核中的共享逻辑时启用 |
| sync_clk_out | Output | 用于 A7 器件 GTP 收发器设计的 txusrclk | 选择内核中的共享逻辑时启用 |
| sys_reset_out | Output | 用于复位的去抖动器输出 | 选择内核中的共享逻辑时启用 |
| gt_reset_out | Output | gt_reset 去抖动器的输出 | 选择内核中的共享逻辑时启用 |
| init_clk_p init_clk_n | Input | 自由运行的系统/板时钟 | 选择内核中的共享逻辑时启用。 Single Ended INIT CLK 选项提供单端 init_clk 输入。 |
| init_clk_out | Output | 系统时钟差分缓冲器输出 | 选择内核中的共享逻辑时启用。 不适用于单端 INIT CLK 选项。 |
| gt0_pll0refclklost_out gt1_pll0refclklost_out | Output | 表示 GTPE2_COMMON 的 refclklost 端口 | 选择内核中的共享逻辑时启用。 |
| quad1_common_lock_out quad2_common_lock_out | Output | 表示 GTPE2_COMMON 的 PLL 已实现锁定 | 选择内核中的共享逻辑时启用。 |
| gt0_pll0outclk_out gt0_pll1outclk_out gt0_pll0outrefclk_out gt0_pll1outrefclk_out gt1_pll0outclk_out gt1_pll1outclk_out gt1_pll0outrefclk_out gt1_pll1outrefclk_out | Output | GTPE2_COMMON 生成的时钟输出 | 选择内核中的共享逻辑时启用。 |
| gt< quad>_qplllock_out | Output | 表示 GTXE2_COMMON/GTHE2_COMMON 的 PLL 已实现锁定 | 选择内核中的共享逻辑时启用。 |
| gt< quad>_qpllrefclklost _out | Output | 指示 GTXE2_COMMON/GTHE2_COMMON 的参考时钟输入丢失 | 选择内核中的共享逻辑时启用。 |
| gt_qpllclk_quad< quad>_out gt_qpllclk_quad< quad> _out | Output | GTXE2_COMMON/GTHE2_COMMON 生成的时钟输出 | 选择内核中的共享逻辑时启用。 |
| gt_qpllrefclk_quad< quad>_ out | Output | 由 GTXE2_COMMON/GTHE2_COMMON 生成的四路锁相环 (QPLL) 参考时钟输出 | 选择内核中的共享逻辑时启用。 |
| gt< quad>_qplllock_in | Input | 表示 GTXE2_COMMON/GTHE2_COMMON 的 PLL 已实现锁定 | 选择示例设计中的共享逻辑时启用。 |
| gt< quad>_qpllrefclklost_in | Input | 表示 GTXE2_COMMON/GTHE2_COMMON 的参考时钟输入丢失 | 选择示例设计中的共享逻辑时启用。 |
| gt_qpllclk_quad< quad>_in | Input | GTXE2_COMMON/GTHE2_C OMMON 生成的时钟输出 | 选择示例设计中的共享逻辑时启用。 |
| gt_qpllrefclk_quad< quad>_ in | Input | 从 GTXE2_COMMON/GTHE2_COMMON 生成的 QPLL 参考时钟输出 | 选择示例设计中的共享逻辑时启用。 |
| gt_qpllreset_out | Output | 接地 | 选择示例设计中的共享逻辑时启用。 |
| tx_out_clk | Output | Aurora 8B/10B 内核共享的并行时钟 | 选择示例设计中的共享逻辑时启用。 |
CRC
CRC 模块提供 16 位或 32 位 CRC,用于用户数据。下表描述了 CRC 模块端口。
| Port Name | Direction | Domain | Description |
|---|---|---|---|
| c_valid | Output | user_clk | CRC 有效端口。 当置为高电平时,启用对 crc_pass_fail_n 信号的采样。 |
| c_pass_fail_n | Output | user_clk | 当发送器和接收器的 CRC 值匹配时,crc_pass_fail_n 信号在发送和接收时置为高电平。 crc_pass_fail_n 信号只能与 crc_valid 信号一起采样。 |
生成无 GT 的 Aurora
启用后,它会生成不带 GT 的 Aurora 内核,并将收发器从内核移至示例设计中的支持级别。 下表提供了用于在 Aurora IP 之外与 GT 收发器交互的端口列表。
| Name | Direction | Clock Domain | Description |
|---|---|---|---|
| gttxresetdone_in | Input | user_clk | 向 Aurora 指示由复位控制器帮助程序块启动的收发器原语的发送器复位序列已完成的高电平有效指示。 |
| gtrxresetdone_in | Input | user_clk | 向 Aurora 指示由复位控制器帮助程序块启动的收发器原语的接收器复位序列已完成的高电平有效指示。 |
| rxdata_in | Input | user_clk | 收发器通道接收数据的用户接口。 |
| rxnotintable_in | Input | - | 连接到 UltraScale GT 向导的 rxctrl3_out 端口。 |
| rxdisperr_in | Input | - | 连接到 UltraScale GT 向导的 rxctrl1_out 端口。 |
| rxchariscomma_in | Input | - | 连接到 UltraScale GT 向导的 rxctrl2_out 端口。 |
| rxcharisk_in | Input | - | 连接到 UltraScale GT 向导的 rxctrl0_out 端口。 |
| rxrealign_in | Input | - | 连接到 UltraScale GT 向导的 rxbyterealign_out 端口。 |
| rxbufferr_in | Input | - | 连接到 UltraScale GT 向导的 rxbufstatus_out 端口。 |
| txbuferr_in | Input | - | 连接到 UltraScale GT 向导的 txbufstatus_out 端口。 |
| chbonddone_in | Input | - | 连接到 UltraScale GT 向导的 rxchanisaligned_out 端口。 |
| txoutclk_in | Input | - | 连接到 UltraScale GT 向导的 txoutclk_out 端口。 |
| txlock_in | Input | - | 连接到 UltraScale GT 向导的 cplllock_out 端口。 |
| rxfsm_datavalid_out | Output | user_clk | Active-High |