场景:Few-Shot Learning Prompt Learning PLM(BART) Transfer Learning
Abstract
最近,人们研究了少量的研究。NER我很感兴趣,低资源的目标域和资源丰富的源域有不同的标签集。。为了解决这一问题,我
1 Introduction
命名实体识别(NER)是自然语言处理中的一项基本任务,根据预定义的实体类别识别文本输入,如位置、人、组织等。目前,顺序神经网络用于主要方法,如BiLSTM和bert表示输入文本,使用softmax或CRF输出层分配指定的实体标签(如组织、人和位置)或非实体标签token上。如figure2(a)。 神经NER该模型需要大量的标记训练数据,可用于新闻等某些领域,但在大多数其他领域很少。理想情况下,最好从资源丰富的新闻领域转移知识,以便在基于一些标记实例的目标领域使用模型。然而,在实践中,一个挑战是实体类别可能在不同的领域不同。如figure系统需要识别新闻域的位置和人物,但要识别电影域的人物和标题。 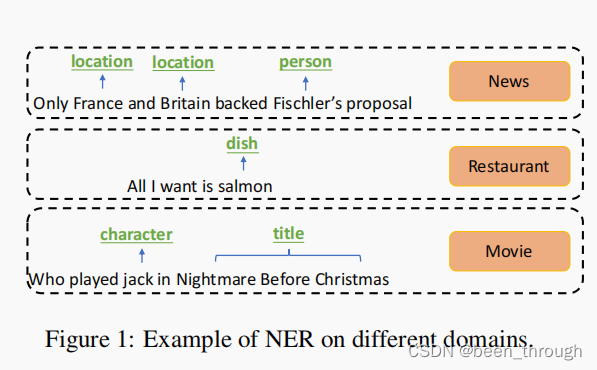
最近的工作通过使用距离测量研究了少镜头NER的设置。其主要思想是基于源域的实例训练相似度函数,然后以目标域的相似度函数为基础FSL-NER最近标准。与传统方法相比,基于距离的方法大大降低了领域自适应的成本,尤其是目标领域数量大的情况。然而,它们在标准域内设置的性能相对较弱。此外,它们在两个方面的自适应能力也受到限制。 为了解决这些问题,我们研究了一种基于模板的方法,利用生成式预训练语言模型的少镜头学习潜力进行序列标记。具体来说,如图2所示,BART微调采用相应标记实体填充的预定义模板。例如,我们可以定义模板,例如<candidate_span> is a <entity_type entity>”, where <entity_type> can be “person” and “location”, etc.。考虑到句子ACL will be held in Bangkok”,其中“ Bangkok”有一个gold label “location我们可以使用填充模板 “Bangkok is a location entity””来训练BART,输入句子decoder输出。在非实体跨度方面,我们使用模板<candidate_span> is not a named entity”,。在推理过程中,我们将输入句子中所有可能的文本跨度列为命名的实体候选人,并根据模板上的文本跨度列出BART分数将它们分为实体或非实体。 该方法有三个优点。首先,由于预训练模型具有良好的泛化能力,网络可以有效地利用新领域的标记实例 fine-tuning。其次,与基于距离的方法相比,即使目标域和源域在写作风格上存在较大差距,这种方法也具有较强的鲁棒性。第三,使用传统方法(softmax/CRF与预训练模型相比,我们的方法可以在不改变输出层的情况下应用于任何新变输出层,因此允许持续学习( continual learning). 在资源丰富、镜头少的设置下,我们进行了实验。结果表明,我们的方法是新闻数据集CoNLL03(获得了标签依赖方法最先进的竞争结果,在少镜头设置上明显优于怀斯曼和斯特拉托斯(2019年)。Ziyadi等人(2020年)和黄等人(2020年)。
2 Related Work
神经方法在NER给出了竞争性能。一些方法(Chiu2016年与尼科尔斯、斯特鲁贝尔等,2017年将NER使用其他方法作为每个输入标记的局部分类问题CRF(Ma和Hovy,2016)或序列到序列框架(Zhang等,2018;Liu等,2019)。Cui和Zhang(2019)和Gui等人(2020)分别使用标签注意网络和贝叶斯神经网络。Yamada等人(2020年)使用实体感知的预训练NER取得了最先进的成绩。 我们的工作是基于距离的NER,适应成本最小化领域。怀斯曼和stratos(2019)从最近的邻居那里复制令牌级别的标签,通过检索一个有标记的句子列表。Yang和Katiyar(2020)怀斯曼和斯特拉托斯(2019)通过使用维特比解码器捕获从源域估计的标签依赖。Ziyadi等人(2020)采用两步法(Lin等人,2019;Xu等人,2017),该方法首先检测跨界,然后通过比较与标记实例的相似性来识别实体类型。虽然不更新NER网络参数,但这些方法依赖于源域和目标域之间实体模式。一个例外是Huang等人(2020)使用外部噪音webNER噪声监督预训练和自我训练方法的数据研究。 使用模板解决自然语言理解任务的一系列工作。它的基本思想是利用预训练模型的信息,在语言建模任务中定义特定的句子模板。.Brown等人(2020年)首次在文本分类任务中使用提示符进行小样本学习。Schick和Schutze(2020)重构输入作为文本分类的完形填空问题。Schick等人(2020)和Gao等人(2020)通过自动生成标签词和模板,扩展了Schick和Schutze(2020)。Petroni等人(2019)通过构建封闭模板,从BERT提取实体之间的关系。Sun等人(2019)用模板构建辅助句子,将情绪任务转化为句子对分类任务。
3 Background
Few shot Named Entity Recognition
有两个数据集:高资源和低资源。它们的标签可能是重叠的,不完全相同。目标是根据这两个数据集准确的鲁棒模型。
Traditional Sequence Labeling Methods
传统方法把NER输出作为序列标记任务BIO序列。 encoder softmax 该论文用的bert和bart作为encoder NER域自适应的一种标准方法是先使用源域数据R训练模型,然后使用目标域实例P进一步调整模型。然而,在不同的领域label输出层的参数可能会有所不同, 论文选择权重W和偏置直接从头训练目标b 然而,这种方法并没有充分利用标签关联(例如,percon”和“character关联)不能直接用于目标域中没有标记数据的零样本。
4 Template-Based Method
我们将NER作为seq2seq语言模型在框架下的排序问题。模型的源序列是输入文本X={x1,…,xn},而目标序列Tyk,xi:j={t1,…,tm}是候选文本span xi:j和实体类型yk填充模板。我们先在第四.第四节介绍了如何创建模板.2节和第4.推理和训练细节在3节中展示。
4.1 Template Creation
我们手动创建模板,它有一个slot用于candidate_span,另一个slot用于entity_type标签。使用一对一映射标签集L = {l1, . . . , l|L|}转化为自然语言集合Y = {y1, . . . , y|L|},例:LOC->location。然后定义模板T yk ,如:<candidate_span> is a location entity. 也有非命名实体 <candidate_span> is not a location entity.
我们首先列举了句子{x1,……,xn}中所有可能的跨度,并将它们填充到准备好的模板中。为了提高效率,我们将n-gram的数量从1个限制到8个,因此为每个句子创建了8n个模板。() 然后,我们使用微调的预训练生成语言模型为每个模板分配一个分数 通过使用任何预先训练过的生成语言模型来评分模板,我们计算了每个实体类型的分数f(T+yk,xi:j),以及无实体类型的分数f(T−xi:j)。然后,我们将得分最大的实体类型分配给文本跨度。在本文中,我们采用BART作为预训练的生成语言模型。我们的数据集不包含嵌套的实体。
4.3 Training
golden entities 用于在训练期间创建模板。假设xi:j的实体类型为yk。我们将文本跨度xi:j和实体类型yk填充到T+中,以创建一个目标句子T+yk,xi:j。同样,如果xi:j的实体类型为无实体文本跨度,则通过将xi:j填充到T−中,得到目标句子T−xi:j。.
给定一个序列对(X,T),我们将输入的X输入给BART的编码器,然后得到句子的隐藏表示 然后softmax,损失函数用的负对数似然
4.4 Transfer Learning
给定一个具有小样本实例的新域P,标签集LP(第4.1节)可以与用于训练NER模型的域P不同。因此,我们用用于训练和测试的新域标签集填充模板,其余的模型和算法保持不变。特别是,给定少量的(XP,TP),我们用上面描述的方法为低资源域创建序列对,并对在富源域上训练的NER模型进行微调。该过程成本低,但能有效地转移标签知识。因为我们的方法的输出是一个自然的句子,而不是特定的标签,所以资源丰富和低资源的标签词汇表都是预先训练过的语言模型词汇表的子集(废话)这使得我们的方法能够利用标签相关性,如“person”和“character”,以及“位置”和“城市”,以提高跨领域迁移学习的效果。(预训练模型encoder的功劳,考虑词汇尖的关系)
5 Experiments
我们在资源丰富的BART设置和基于模板的设置和少击设置上与多个基线进行比较。我们使用CoNLL2003作为资源丰富数据集。继Ziyadi等人(2020年)和Huang等人(2020年)之后,我们使用麻省理工学院电影评论(Liu等人,2013年)、麻省理工学院餐厅评论(Liu等人,2013年)和ATIS(Hakkani-Tur等人,2016年)作为跨域小样本数据集。关于跨域转移,在三个目标小样本数据集中存在unseen的实体类型(即高资源数据集有,低资源数据集没有)。我们的训练细节和数据集统计数据的细节显示在附录中。
5.1 Template Influence
表明模板是影响最终性能的一个关键因素。基于开发结果,我们使用了性能最好的模板 测试了以下几个模板,选了第一行的(性能最好的)。
5.2 CoNLL03 Results
Standard NER setting 在高资源数据集
我们可以看到,尽管基于模板的BART是为少数镜头的命名实体识别而设计的,但它在资源丰富的设置中也具有竞争力。 recall高这表明我们的方法在识别命名实体方面更有效,同时也能选择不相关的跨度 (判断是 entity 不是entity) .值得注意的是,虽然序列标记BART和基于模板的BART都使用了BART解码器表示,但它们的性能有很大的差距,后者在F1分数上绝对比前者高出1.30%,证明了基于模板的方法的有效性。观察结果与Lewis等人(2020)的观察结果一致,表明BART在序列分类方面并不是最具竞争力的。这可能是由于其基于seq2序列的去噪自动编码器训练的性质,这不同于BERT的掩蔽语言建模。 为了探究模板是否彼此互补,我们使用表1中报告的前三个模板训练了三个模型,并采用实体级投票方法对这三个模型进行集成。使用集成的精度提高了1.21%,这表明不同的模板可以捕获不同类型的知识。最后,我们的方法通过利用三个模板获得了92.55%的F1分数,这与报告的最佳分数具有很强的竞争力。为了提高计算效率,我们在后续的小样本实验中使用了一个单一的模型。
In domain few-shot NER setting.
我们在CoNLL03上构建了一个学习场few shot景,其中某些特定类别的训练实例数量受到down-sample(隔几个采一次样以实现小样本场景)的相当限制。特别地,我们将“MISC”和“ORG”设置为资源量丰富的实体,将“LOC”和“PER”设置为资源量较低的实体。我们对CoNLL03训练集进行降采样,得到3806个训练实例,其中包括3925个“ORG”,1423个“MISRC”,50个“LOC”和50个“PER ".由于文本样式在丰富资源和低资源的实体类别中是一致的,我们称域中的场景为NER。
5.3 Cross-domain Few-Shot NER Result
当目标实体类型与源域不同时,并且只有少量的标记数据可用于训练时,我们评估了模型数据的性能。我们通过从一个大的训练集中随机抽样训练实例作为目标域的训练数据来模拟跨域低资源数据场景。我们使用不同数量的实例进行训练,每个实体类型随机抽取固定数量的实例(MIT电影和MIT餐厅每个实体类型10、20、50、100、200、500个实例,ATIS每个实体类型10、20、50个实例)。如果一个实体的实例数量少于固定的样本数量,我们就使用所有的实例来进行训练。 我们首先考虑一个从头开始训练的设置,其中不使用源域数据。基于距离的方法不能适合此设置。与传统的序列标记BERT方法相比,我们的方法可以更好地利用few shot数据。特别是,对于每个实体类型只有20个实例,我们的方法给出了F1得分为57.1%,高于MIT餐厅上每个实体类型使用100个实例的BERT。 我们进一步研究知识有多少可以被迁移到新闻域(CoNLL03)。从新闻域(CoNLL03)转移。与基于距离的方法相比(怀斯曼和斯特拉托斯,2019;Ziyadi等人,2020;Huang等人,2020),随着目标域标记数据数量的增加,我们的方法显示出更多的改进,因为基于距离的方法只是优化其搜索阈值,而不是更新其神经网络参数。 一种可能的解释是,如前所述,我们的模型更多地利用了词汇表中不同实体类型标签之间的相关性(BART的功劳),而由于将输出作为离散的类标签来处理,BERT无法实现这一点。