Machine learning and the physical sciences
-
- 摘要
- Ⅳ.多体量子物质(MANY-BODY QUANTUM MATTER)
-
- A.量子态应用神经网络(Neural-Network quantum states)
-
- 1.表征理论(Representation theory)
- 2.从数据中学习 ( Learning from data)
- 3.变异学习 (Variational Learning)
- B.加快多体模拟(Speed up many-body simulations)
- C.多体量子相位分类( Classifying many-body quantum phases)
-
- 1.综合数据 (Synthetic data)
- 2.实验数据 ( Experimental data)
- D.用于机器学习Tensor网络(Tensor networks for machine learning)
- D.展望与挑战(Outlook and Challenges)
- Ⅴ.量子计算( QUANTUM COMPUTING)
-
- A.量子态层析成像(Quantum state tomography)
- B.控制和准备量子位(Controlling and preparing qubits)
- C.纠错( Error correction)
摘要
??机器学习包括近年来最科学的算法和建模工具,用于大量的数据处理任务。我们有选择地回顾了机器学习与物理科学交叉的最新研究。这包括以物理见解为动力的机器学习(ML)概念发展、机器学习技术在物理学多个领域的应用以及两个领域之间的交叉应用。在给出了机器学习方法和原理的基本概念后,我们描述了如何 。然后,我们将描述它 。我们还将重点介绍目的 。 在每一部分,我们都描述了最近的成功和特定领域的方法和挑战。
Ⅳ.多体量子物质(MANY-BODY QUANTUM MATTER)
??量子力学的内在概率性质使该领域的物理系统成为一个有效的无限大数据源,是机器学习和应用的一个非常有吸引力的领域。这种概率性质的例子是量子物理学中的测量过程。绕核运动的电子位置只能根据测量结果大致推断r。无限精确的经典测量设备只能用来记录电子位置的具体观察结果。。在单个电子的情况下,有效实施P(r)在许多量子粒子的情况下,理论预测和实验推断变得更加复杂。例如,观察到的N电子的概率分布为P(r1,…rN)本质上是高维函数,很少能准确确定N比几十个大。估计P(r1,… rN)指数硬度本身就是对复值多体振幅的估计ψ(r1,… rN)直接结果通常被称为量子多体问题 。量子多体问题在各种情况下都表现出来。这些最重要的功能包括复杂量子系统(大多数材料和分子)的理论建模和仿真,而通常仅提供近似的解决方案。量子多体问题的其他非常重要的表现形式包括 ,特别是与物质的复杂性有关。下面,我们讨论了一些ML这些应用侧重于缓解量子多体问题带来的一些具有挑战性的理论和实验问题。
A.量子态应用神经网络(Neural-Network quantum states)
??量子态的神经网络(NQS)使用人工神经网络(ANN)表示多体波函数。通常的选择是 : 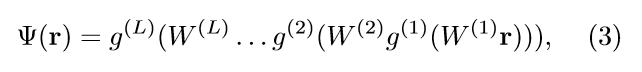 类似于等式(2)中引入的符号。
类似于等式(2)中引入的符号。
??早期工作主要集中在浅层网络上,最著名的是玻尔兹曼机受限(RBM)。在{±1}在可见单元上有隐藏单元,没有偏差RBM深度正式对应L = 2的FFNN,并激活函数g(1)(x)= logcosh(x),g(1)(x) = exp(x)。关于RBM无监督学习概率分布中应用程序的一个重要区别是,当它被用作时NQS时,RBM状态通常被认为具有复数值权重。在最近的工作中,我们不断研究和介绍更深层次的系统结构,如基于完全连接的NQS以及卷积深度网络,请参见图4示例。使用深度FFNN网络的一个动机是因为深度学习在工业中的成功应用,也因为在量子物理中的更一般的理论。例如,研究表明,量子纠缠的深度NQS方法比RBM更有效。NQS其他扩展涉及 。 在这种情况下,可以定义密度矩阵的正定RBM参数。
??量子域的具体挑战之一是NQS物理对称性强加于表示。在物质的周期性排列中,可以使用类似于图像分类任务的卷积结构来实现空间对称。在不同对称风扇区域选择高能态已被证明。虽然空间对称性是其他的ML应用程序中有类似的对应关系,但通常需要满足更多涉及的量子对称性ANN深刻反思架构。从这个意义上说,。
??Bose-Hubbard模型已被用作ANN玻璃模型结构的基准,并取得了最新的效果。但最具挑战性的对称性肯定是 。 在这种情况下,NQS表示需要编码波函数的反对称性(例如,交换两个粒子位置会导致数量减少)。在这种情况下,主要针对现有的费米子变体,探索了不同的方法ansatz进行扩展。校正反对称相关部分的对称RBM波函数已用于研究二维相互作用的晶格费米子(Nomura 等,2017)。其他方法是正确的Slater行列式向后转换,解决费米对称性问题(Luo和Clark,2018)或直接在第一次量化中工作(Han等人,2018a)。由于对称性的特殊性,目前对ML在方法上,费米的情况无疑是最具挑战性的。 到目前为止,在应用方面,NQS这意味着它已被用于三个主要的不同研究领域。
1.表征理论(Representation theory)
??与其他变异状态族相比,研究的活跃领域涉及NQS一般表达能力。关于NQS理论活动旨在了解量子系统神经网络的大小和深度,以描述有趣的相互作用。结合以RBM状态获得的第一个数值结果很快就发现纠缠是NQS有可能表达能力的候选人。例如,RBM状态能有效支持体积定律校准(Deng等人,2017b),许多变参数仅根据系统大小按多项式缩放。 在这个方向上,张量网络的语言正在澄清NQS有些特征特别有用(Chen等人,2018b; Pastori等人,2018)。已显示基于RBM状态的NQS家族相当于一些变异状态的家族,称为相关乘积-状态(Clark,2018; Glasser 等,2018a)。但是,确定属于NQS各种量子态类别的形式方程式(3)和计算有效的张量网络仍然存在问题。准确地表达物质的几个有趣阶段,包括 (Deng等人,2017a; Glasser等人,2018a; HuangandMoore,2017; Kaubrueggeret等人,2018; Lu等人,2018; Zheng等人 (2018年)。不足为奇的是,考虑到其深度较浅,RBM系统结构也普遍受到限制。 具体来说,通常不可能紧凑RBM写下所有可能的物理状态(GaoDuan,2017年)。还引入了类似的网络结构作为可能的理论框架,以替代量子力学的标准路径-积分表示形式(Carleo 等,2018)。
2.从数据中学习 ( Learning from data)
与了解NQS的理论性质的活动并行,该领域的一系列研究涉及以下问题:了解在实践中很难从数值数据中学习量子态。这可以使用合成数据(例如来自数值模拟的数据)或直接通过实验来实现。
在有监督的学习环境中探索了这一研究领域,以了解NQS可以如何很好地表示不容易以ANN形式表达(以封闭分析形式表示)的状态。然后,目标是训练NQS网络|ψ>,以尽可能接近地表示可以有效计算其幅度的某个目标状态|Ψ>。该方法已成功用于学习费米离子,沮丧的和玻色的哈密顿量的基态(Cai和Liu,2018)。这些代表了有趣的研究案例,。同样,有人提出了一种监督方法来学习具有浅NQS的随机矩阵乘积状态波函数(Borin和Abanin,2019),以及具有可计算处理的DBM形式的广义NQS(Pastori等,2018)。在后一种情况下,这些研究显示了进行学习的有效策略,而在前一种情况下,已显示出学习一些随机MPS的难度。目前,推测此硬度源自随机MPS的纠缠结构,但是尚不清楚这是否与NQS优化景观的硬度或浅NQS的固有限制有关。
除了对给定量子态的有监督学习之外,使用NQS的数据驱动方法还主要集中在无监督方法上。在此框架中,只有来自某些目标状态|Φ或密度矩阵的测量可用,并且目标是使用此类测量以NQS形式重建完整状态。 在最简单的设置中,给定一个数据集,该数据集根据Born规则处方P(r)= |Φ(r)| ²分布M个测量值r(1)… r(M),其中P(r)为 待重建。在波函数为正定的情况下,或者仅提供特定基础上的测量值的情况下,使用标准无监督学习方法重建P(r)足以重建基础量子态Φ上的所有可用信息。例如,已使用基于RBM的生成模型对随机哈密顿量的基态(Torlai等人,2018)证明了这种方法。 在一系列经典的难以从量子态采样的案例中,也证明了基于深度VAE生成模型的方法(Rocchetto等人,2018),对于这种证明网络深度对压缩的效应。
在更一般的情况下,问题是要使用来自多个量子数基础的测量结果来重构纯或混合的一般量子态。这些对于重新构造量子态的复数相特别重要。该问题对应于量子信息中的一个众所周知的问题,称为量子状态层析成像,为此已经引入了特定的NQS方法(Carrasquilla等,2019; Torlai等,2018; Torlai和Melko,2018)。 在专用的第V.A节中,还将结合用于此任务的其他ML技术,对这些内容进行更详细的讨论。
3.变异学习 (Variational Learning)
最后,NQS表示的主要应用之一是在多体量子问题的变分近似中。这些方法的目标是,例如,。在这种情况下,找到一个给定的量子哈密顿量H的基态的问题用变分形式表述为学习NQS权重W使E(W)=<Ψ(W)| H |Ψ(W)i>/<Ψ(W)|Ψ(W)>最小的问题。这是使用 来实现的(CarleoandTroyer,2017)。在该应用系列中,没有给出表示量子态的外部数据,因此与NQS的有监督和无监督的学习方案相比,它们通常需要更大的计算负担。
各种自旋的实验(Choo等人,2018; Deng等人,2017a; Glasser等人,2018a; Liang等人,2018),bosonic(Chooet等人,2018; Saito,2017,2018; Saito和Kato,2017年)和铁离子(Han等人,2018a; Luo和Clark,2018年; Nomuraet等人,2017年)模型表明,可以获得与现有最先进方法竞争的结果。在某些情况下,已经证明了对现有变分结果的改进,尤其是对于二维晶格模型(Carleo和Troyer,2017年; Luo和Clark,2018年; Nomura等人,2017年)以及物质的拓扑阶段(Glasser等人,2017年) 等人,2018a; Kaubruegger等人,2018)。
其他NQS应用程序涉及时间依赖的Schrödinger方程的解(Carleo和Troyer,2017年; Czischek等人,2018年; Fabiani和Mentink,2019年; Schmitt和Heyl,2018年)。在这些应用中,人们使用狄拉克(Dirac)和弗伦克尔(Frenkel)的时间相关变分原理(Dirac,1930; Frenkel,1934)来学习网络权重的最佳时间演化。这也可以适当地推广到开放的耗散量子系统,为此可以实现Lindblad方程的变分解(Hartmann和Carleo,2019年; Nagy和Savona,2019年; Vicentini等人,2019年; Yoshioka和Hamazaki,2019年) 。
在这里讨论的绝大多数变体应用中,使用的学习方案通常是比标准SGD方法更高阶的技术。随机重构(SR)方法(Beccaand Sorella,2017; Sorella,1998)及其对时间依赖情况的推广(Carleo等,2012)已被证明特别适合NQS的变分学习。SR方案可以看作是用于学习概率分布的自然梯度方法(Amari,1998)的量子模拟,它建立在与神经网络参数相关的内在几何上。 最近,为了不使用比最初采用的网络更深入,更具表现力的网络,基于一阶技术的学习方案得到了更一致的使用(Kochkov和Clark,2018; Sharir等,2019)。这些构成了解决同一问题的两种不同哲学。 一方面,早期的应用程序侧重于通过非常准确但昂贵的训练技术学习的小型网络。另一方面,后来的方法集中在更深的网络和更便宜但又不太准确的学习技术上。 以计算有效的方式将这两种哲学相结合是该领域面临的开放挑战之一。
B.加快多体模拟(Speed up many-body simulations)
在量子多体问题领域中使用ML方法已远远超出了量子态的神经网络表示。 研究相互作用模型的有效技术是 。这些方法通过映射到有效的经典模型(例如,借助路径积分表示)来随机计算量子系统的属性。由贴图程序得出的一个实用问题,即提供有效的高维空间采样方案(路径积分,扰动序列等),需要仔细进行调整,通常取决于问题。因此,为这些表示设计通用采样器是一个特别具有挑战性的问题。但是,无监督的ML方法可以用作加快经典和量子应用程序蒙特卡洛采样的工具。已经提出了在该方向上的几种方法,并且利用无监督学习的能力很好地近似了从基础蒙特卡洛方案中采样的目标分布。相对简单的基于能量的生成模型已用于古典系统的早期应用中(Huang和Wang,2017; Liu等,2017b)。然后,“自学习”蒙特卡洛技术也已推广到费米离子系统(Chen等,2018a; Liu等,2017c; Nagai等,2017)。总的来说,已经发现这种方法在减少自相关时间方面是有效的,特别是与效率较低的马尔可夫链蒙特卡洛族和本地更新的族相比。最近,采用了最新的生成ML模型来加快特定任务中的采样速度。 值得注意的是(Wu等,2018)使用了深度自回归模型,该模型可以使自旋玻璃等经典难题更有效地采样。。在(Sharir 等,2019)中,这种方法也已经推广到量子情况,其中引入了 。 该表示自动归一化,并允许在上述变分学习中绕过马尔可夫链蒙特卡洛方法。
QMC技术虽然适用于大量的玻色子和自旋系统,但在处理几种有趣的铁离子模型以及沮丧的自旋哈密顿量时,通常会引起严重的信号问题。在这种情况下,很容易使用ML方法来尝试直接或间接减少符号问题。虽然仅在第一阶段,但该系列应用程序已被用来通过格林函数中的隐藏信息来推断有关铁离子相的信息(Broecker等人,2017b)。
同样,机器学习技术可以帮助减轻量子模型动力学特性中符号问题更细微表现的负担。特别是,从虚数时间相关性重构频谱函数的问题也是一个领域,其中ML可以用作传统最大熵技术的替代方法,以执行QMC数据的解析连续性(Arsenault等人,2017年) ; Fournier等人,2018; Yoon等人,2018)。
C.多体量子相位分类( Classifying many-body quantum phases)
多体量子态的复杂性所带来的挑战以许多其他形式表现出来。 特别是,在数值模拟和实验中,。由于这个原因,用于识别物质相的ML方案在量子相的背景下变得特别流行。 在下文中,我们将回顾量子域的某些特定应用,而有关识别相和相变的更一般的讨论将在II.E中找到。
1.综合数据 (Synthetic data)
继有监督方法在相分类的早期发展(Carrasquilla and Melko,2017; Van Nieuwenburg等,2017; Wang,2016)之后,许多研究从那时起就着重于对合成数据中的物相进行分析,主要是通过量子系统模拟。尽管我们在这里不尝试详尽地回顾朝这个方向出现的许多研究,但我们着重介绍了两个大的问题系列,这些问题到目前为止在很大程度上已成为新的机器学习工具的基准。
量子多体定位的第一个具有挑战性的阶段分类方案是试验台。 这是一个难以捉摸的阶段,显示了多体波函数本身的特征指纹,但不一定从更传统的阶次参数中浮现出来[例如,有关该主题的最新评论,请参见(例如,Alet和La fl orencie,2018年)。该方向上的最初研究集中于 (Hsu等人,2018; Huembeli等人,2018b; Schindler等人,2017; Venderley等人,2018; Zhang等人。 ,2019)。这些工作证明了***在相对较小的系统中通过精确的对角化技术可以有效地学习MBL相变的能力***。相反,其他研究着重于 (Doggen等,2018; van Nieuwenburg等,2018)。目前,后一种方案似乎是最有希望的应用实验,而前者已被用作在相关疾病存在时识别意外阶段存在的工具。
分析物质的拓扑阶段时会发现另一类非常具有挑战性的问题。 这些在很大程度上被认为是ML计划的一项重要测试,因为这些阶段通常以非本地顺序参数为特征。反过来,对于用于图像的流行分类方案来说,很难学习这些非局部顺序参数。 当分析具有拓扑相变的经典模型时,已经存在该特定问题。例如,在存在BKT型过渡的情况下,在原始蒙特卡洛配置上训练的学习方案是无效的(Beachet等,2018; Hu等,2017)。这些问题可以通过使用预先设计的功能(Broecker等人,2017a; Cristoforetti等人,2017; WangandZhai,2017; Wetzel,2017)而不是原始蒙特卡罗样本来设计训练策略来规避。。在量子世界的更深处,沿着 的方向开展了研究活动。可以使用神经网络对非交互拓扑哈密顿主义者的族进行分类,例如使用离散的系数(不真实的(Ohtsuki和Ohtsuki,2016,2017)或动量空间(Sun等,2018; Zhang等,2018c)作为输入。在这些情况下,发现神经网络能够重现(已经预先已知的)拓扑不变量,例如绕组数,贝里曲率等。与非相互作用谱带模型的情况相比,高度相关的拓扑物质的上下文在很大程度上更具挑战性。在这种情况下,一种常见的方法是 。 一个众所周知的例子是所谓的量子环地形学(ZhangandKim,2017),它是对本地操作员进行训练的,该操作员是根据采样波函数助行器的单次镜头计算得出的,例如在变体蒙特卡洛中所做的。研究表明,这种对局部特征的非常具体的选择能够区分相互作用强烈的分数Chern绝缘子以及Z2量子自旋液体(Zhang等,2017)。已经实现了类似的方法来对物质的更多奇异相进行分类,包括磁性天sky相(Iakovlev等,2018)和反天rm动力学中的动力学状态(Ritzmann等,2018)。
尽管到目前为止在这里描述的多个方向上都取得了进步,但是可以说,物质的拓扑阶段,尤其是对于相互作用的系统,是构成阶段分类的主要挑战之一。虽然已经取得了一些良好的进展(Huembeli等,2018a; Rodriguez-Nieva和Scheurer,2018),但未来的研究将需要解决不依赖于数据特征预选的训练方案的问题。
2.实验数据 ( Experimental data)
除了对数值模拟的数据进行广泛研究以外,受监督的方案还发现了它们作为分析量子系统实验数据的工具的方式。在超冷原子实验中,有监督的学习工具已被用来绘制非相互作用粒子的拓扑相以及有限光阱中Mott绝缘相的开始(Rem等人,2018)。在这种特定情况下,这些阶段是已知的并且可以用其他方法识别。 但是,将先验的理论知识与实验数据相结合的基于ML的技术具有进行真正的科学发现的潜力。
例如,当实验数据必须归因于许多可用的且同样可能的先验理论模型之一,但是手头的实验信息不容易解释时,机器学习可以在有趣的情况下进行科学发现。通常会出现一些有趣的情况,例如,当顺序参数是实验结果的复杂且仅是隐式已知的非线性函数时。在这种情况下,机器学习方法可以用作有效学习给定理论的基本特征的强大工具,并提供可能公正的实验数据分类。高温超导体中不相称的情况就是这种情况,其扫描隧道显微镜图像显示出复杂的图案,而这些图案很难使用常规分析工具进行解读。在这种情况下使用监督方法,最近的工作(Zhang et al。,2018d)表明可以推断这些系统中空间排序的性质,见图5。
类似的想法也已经被用于费米子的另一种原型相互作用量子系统,即哈伯德模型,这是在光学晶格中的超冷原子实验中实现的。在这种情况下,参考模型提供了热密度矩阵的快照,可以通过监督学习的方式对其进行预分类。这项研究的结果(Bohrdt等人,2018)是,实验结果与所提出的一种理论具有良好的一致性,在这种情况下,。
在上述的最后两个实验应用中,监督方法的结果在很大程度上是非常重要的,并且很难根据现有的其他信息来进行先验预测。然而,由要分类的理论的选择引起的内在偏差是这类方法面临的当前限制之一。
D.用于机器学习的Tensor网络(Tensor networks for machine learning)
目前为止,研究主题主要涉及ML思想和工具在量子多体物理学领域研究问题的使用。作为这种哲学的补充,该领域中一个有趣的研究方向探索了相反的方向,研究了 。。这些是非常成功的多体波函数变体族,自然地从量子态的低纠缠表示中浮现出来(Verstraete等,2008)。在有监督的和无监督的环境中,Tensor网络都可以用作ML任务的实用工具和概念工具。
这些方法基于以下思想:提供物理启发式学习方案和网络结构,而这种结构是较常规采用的随机学习方案和FFNN网络所特有的。例如,矩阵生成状态(MPS)表示是一维用于相互作用的一维量子系统的仿真工具(White,1992),已被重新用于执行分类任务(Liu等,2018; Novikov 等人,2016; Stoudenmire和Schwab,2016),最近还被用作无监督学习的显式生成模型(Han等人,2018b; Stokes和Terilla,2019)。值得一提的是,在应用数学的背景下开发的其他相关高阶张量分解已用于机器学习目的(Acar和Yener,2009; Anandkumar等,2014)。正式引入了与MPS表示形式等效的 (Oseledets,2011)作为执行各种机器学习任务的工具(Gorodetsky等,2019; Izmailov等,2017; Novikov等, 2016)。 。
为了增加在这些低秩张量分解中编码的纠缠量,最近的工作集中在 上。一个著名的例子是使用具有层次结构的树张量网络(Hackbusch和Kühn,2009; Shi等,2006),这些技术已用于分类(Liu等,2017a; Stoudenmire,2018)和生成模型 (Cheng等人,2019)任务取得了成功。另一个例子是缠结板状状态的使用(Changlani等人,2009; Gendiar和Nishino,2002; Mezzacapo等人,2009)和字符串键合状态(Schuch等人,2008),都显示了分类任务的显着改进。 超过MPS状态(Glasser et al。,2018b)。
从理论上讲, 之间的深层联系可用于理解并可能启发成功的ML设计网络。张量网络形式主义已被证明可以通过重归一化组概念来解释深度学习。在这个方向上的开拓性工作已经将MERA张量网络状态(Vidal,2007)连接到分层贝叶斯网络(Bény,2013)。在后来的分析中,卷积算术电路(Cohen 等,2016)是一个具有乘积非线性的卷积网络家族,已经引入了一种方便的模型来将张量分解与FFNN体系结构联系起来。除了它们在概念上的相关性,这些联系可以帮助建立归纳性偏见在现代和普遍采用的神经网络中的作用(Levine等人,2017)。
D.展望与挑战(Outlook and Challenges)
在过去的几年中,ML在量子多体问题上的应用取得了飞速的发展,涉及从 的各种主题。在这种情况下,机器学习技术的潜力已经浮出水面,相对于针对选定问题的现有技术而言,已经显示出更高的性能。然而,在很大程度上,机器学习技术在该领域的真正力量仅得到了部分证明,还有一些悬而未决的问题有待解决。
例如,在使用NQS进行变分研究的情况下,到目前为止,与其他种类的变分状态家族(如张量网络)一样,对于不同种类的神经网络量子态所获得的经验成功的起源还没有得到很好的理解。费米离子系统的表示和模拟仍然面临着主要的开放挑战,对于它们,仍然需要有效的神经网络表示。
用于ML的Tensor网络表示形式,以及用于NQS的复数值网络,在将领域桥接回计算机科学领域中发挥着重要作用。该研究方向未来的挑战在于 。
。这与其他领域(例如高能和天体物理学)形成了鲜明的对比,在后者中,机器学习方法已经发展到一个阶段,在该阶段,它们通常被用作数据分析的标准工具。要在量子域中实现相同的目标,需要在理论和实验方法之间进行更紧密的协作,并且需要更深入地了解ML可以带来实质性差异的特定问题。
总体而言,鉴于ML方法应用于多体量子物质的时间相对较短,但是有充分的理由相信,这些挑战将在未来几年得到大力解决,并且其中一些挑战已得到了解决。
Ⅴ.量子计算( QUANTUM COMPUTING)
量子计算使用量子系统来处理信息。在最流行的基于门的量子计算框架(Nielsen和Chuang,2002年)中,一种量子算法描述了通过离散变换将n个两级系统(称为量子位, 或量子门)的量子系统的初始状态|ψ0>演化为最终状态|ψf>的过程。。
机器学习和量子计算的交叉领域在过去几年中已成为活跃的研究领域,并且包含多种将两种学科融合的方法(另请参见(Dunjko和Briegel,2018)。量子机器学习的问题表明量子计算机可以增强,加速或创新机器学习(Biamonte等人,2017; Ciliberto等人,2018; Schuld和Petruccione,2018a)(另见第VII和V节)。 量子学习理论强调了在量子框架下学习的理论方面(Arunachalam and de Wolf,2017)。
在本节中,我们关注第三个角度,。这个角度包括从使用智能数据挖掘方法到在可以用作量子位的材料中找到物理状态的主题(Kalantre等,2019),到量子装置的验证(Agresti等,2019),学习等。 量子算法的设计(Bang等人,2014; Wecker等人,2016),促进量子电路的经典仿真(Jónsson等人,2018),量子实验的自动化设计(Krenn等人,2016; Melnikov) 等人,2018),并学习从测量中提取相关信息(Seif等人,2018)。
我们关注与ML计算有关的三个与量子计算有关的一般问题:。。。
与本综述中的其他学科相似,机器学习在所有这些领域都显示出令人鼓舞的结果,并且从长远来看,它将有可能进入量子计算工具箱,与其他公认的方法并列使用。
A.量子态层析成像(Quantum state tomography)
。QST通常是量子信息和量子技术领域的核心工具,通常被用作评估实验平台的质量和局限性的一种方式。然而,执行完整的QST所需的资源极其苛刻,所需的测量数量与qubit /量子自由度成指数比例增长[请参阅(Paris and Rehacek,2004),以进行有关该主题的评论,以及(Haah等 等人,2017年; O’Donnell和Wright,2016年),探讨了状态层析成像学习的难度]。
机器学习工具已经在几年前被确定为一种利用密度矩阵中的特殊结构来提高完整QST成本的工具。压缩传感(Gross等人,2010)是解决该问题的一种重要方法,对于秩为r和维数为d的密度矩阵,可以将所需的测量次数从d²减少到O(rdlog(d)²)。 例如,已经针对六光子状态(Tóth等人,2010)或捕获离子的七比特系统(Riofrío等人,2017)实施了该技术的成功实验实现。在方法论方面,完整的QST最近已经看到了深度学习方法的发展。例如,使用基于神经网络的监督方法, 。 最近还使用基于神经网络的方法解决了为QST选择最佳测量基础的问题,该方法使用贝叶斯规则优化了目标密度矩阵上的先验分布(Quek等人,2018)。通常,虽然ML接近完整QST可以用作减轻测量要求的可行工具,但是它们不能对QST的固有指数标度提供改进。
通常仅在假定量子态具有某些特定规律性的情况下才能克服指数势垒。基于密度矩阵的张量网络参数化的层析成像是该方向上的重要第一步,允许对大型,低纠缠量子系统进行层析成像(Lanyon等,2017)。近年来,基于参数化的QST的ML方法已成为一种可行的选择,尤其是对于高度纠缠的状态。 具体而言,假设采用NQS形式(在纯态情况下,请参见方程3),可以将QST重新表述为无监督的ML学习任务。在纯态的情况下,已经证明了一种获取波函数相位的方案(Torlai等人,2018)。 在这些应用中,多体波函数的复数相位是在不同基础上重构与测量过程相关的几种概率密度时获得的。总的来说,这种方法可以演示高达约100量子位的高度纠缠态的QST,这对于完整的QST技术而言是不可行的。 层析成像方法可以适当地概括为混合态,以基于纯化的NQS(Torlai和Melko,2018)或基于深度归一化流量(Cranmer等,2019)引入密度矩阵的参数化。前一种方法也已经用Rydberg原子进行了实验证明(Torlai等,2019)。 最近也提出了一种有趣的替代方法,用于断层摄影的NQS表示(Carrasquilla等,2019)。这是基于直接根据正算子值度量(POVM)对密度矩阵进行参数化。因此,这种方法具有直接学习测量过程本身的重要优势,并且已经证明可以在相当大的混合状态下很好地缩放。与基于NQS的方法中的显式参数化相反,此方法可能的不便之处在于,仅根据生成模型隐式定义了密度矩阵。
QST的其他方法还探索了使用参数化为局部哈密顿量基态的量子态(Xin等人,2018),或绕过QST直接测量量子纠缠的诱人可能性(Gray等人,2018)。扩展到更复杂的量子过程层析成像问题也很有希望(Banchi等,2018),而基于ML的方法在更大系统上的可扩展性仍然带来挑战。最后,。在此框架中,PAC量子态的可学习性(Aaronson,2007)在(Rocchetto等人,2017)中进行了实验证明,而``阴影层析成像’'方法(Aaronson,2017)则表明即使是线性大小的训练集也可以 提供足够的信息以成功完成某些量子学习任务。这些信息理论保证带有计算限制,学习仅对特殊类别的状态有效(Rocchetto,2018)
B.控制和准备量子位(Controlling and preparing qubits)
量子控制的中心任务如下:给定一个演化U(θ),该演化依赖于参数θ并将初始量子态|ψ0>映射到|ψ(θ)> = U(θ)|ψ0>,其中θ*是最小准备状态与目标状态之间的重叠或距离|<ψ(θ)|ψtarget>| ²?为了促进分析研究,通常将可能的 ,以使U(θ)= U(s1,…,sT)成为步骤s1,…,sT的序列。 例如,可以仅在两个不同的强度h1和h2上应用控制场,目标是找到最优策略st∈{h1,h2},t = 1,…,T以使初始状态仅使用这些离散操作尽可能接近目标状态。
此设置直接推广到强化学习框架(Sutton和Barto,2018),在该框架中,代理从允许的控制干预列表中选择“动作”,例如应用于量子位量子态的两个场强。事实证明,该框架在各种环境下均能与最新方法竞争,例如相互作用量子比特的不可整合多体量子系统中的状态准备(Bukov等人,2018)或使用强周期振荡 准备所谓的“ Floquet-engineered”状态(Bukov,2018年)。最近的一项研究(强化学习)与传统优化方法(例如,随机梯度下降)用于准备单个量子状态的比较表明,如果“动作空间”自然离散且足够小,则学习是有利的(Zhang等, 2019)。
在稍微逼真的设置中,图片变得越来越复杂,例如,当控件嘈杂时(Niu等人,2018)。有趣的是,控制问题也已通过使用递归神经网络来分析未来噪声的时间序列来预测未来的噪声来解决。使用该预测,可以校正预期的未来噪声(Mavadia等,2017)。
机器学习的状态准备的一种完全不同的方法试图找到蒸发冷却以产生Bose-Einstein冷凝物的最佳策略(Wigley等,2016)。 在基于贝叶斯优化的在线优化策略中(Frazier,2018; Jones等,1998),高斯过程被用作统计模型,以捕获控制参数与冷凝水质量之间的关系。机器学习模型发现的策略允许使用比纯优化技术少10倍的迭代的冷却协议。一个有趣的功能是-与机器学习的普遍声誉相反,高斯过程允许确定哪些控制参数比其他参数更重要。
通过“学习”光学仪器的序列以准备高度纠缠的光子量子态的方法,捕获了另一个角度(Melnikov等人,2018)。
C.纠错( Error correction)
建立通用量子计算机的主要挑战之一是纠错。 在任何计算过程中,硬件的物理缺陷都会引入错误。但是,尽管经典计算机允许基于重复信息进行简单的错误校正,但量子力学的无克隆定理需要更复杂的解决方案。表面编码的最著名提议规定将一个“逻辑量子位”编码为几个“物理量子位”的拓扑状态。对这些物理量子位的测量揭示了一系列错误事件的“足迹”,称为综合症。 解码器将校正子映射到错误序列,一旦知道该错误序列,就可以通过再次应用相同的错误序列来纠正该错误序列,而不会影响存储实际量子信息的逻辑量子位。粗略地说,因此,量子错误校正的技术是预测来自症候群的错误-这自然是适合机器学习框架的一项任务。
在过去的几年中,从监督学习到无监督学习以及强化学习,已经将各种模型应用于量子误差校正。它们的应用细节变得越来越复杂。 第一个建议是部署一个由成对的数据集(错误,综合征)训练的Boltzmann机器,该数据集指定概率p(错误,综合征),该概率可用于从所需分布p(错误)提取样本。 (Torlai和Melko,2017)。这个简单的配方显示了某些错误的性能,可与普通基准媲美。综合症与错误之间的关系同样可以通过前馈神经网络来学习(Krastanov and Jiang,2017; Maskara等,2019; Varsamopoulos等,2017)。但是,由于可能的解码器空间爆炸并且数据采集成为问题,因此这些策略受到可伸缩性问题的困扰。最近,神经网络已经与泛神经网络概念化小组相结合来解决这个问题(Varsamopoulos等,2018),并且已经研究了神经网络不同超参数的意义(Varsamopoulos等,2019)。
除了可扩展性之外,量子纠错中的一个重要问题是校正子测量过程也可能引入误差,因为它涉及应用小的量子电路。此设置增加了问题的复杂性,但对于实际应用而言是必不可少的。 可以通过重复进行校正子测量循环来减少错误识别中的噪声。为了考虑额外的时间维度,已经提出了递归神经网络架构(Baireuther等人,2018)。另一个途径是将解码视为强化学习问题(Sweke等,2018),其中代理可以选择对物理量子位(而不是逻辑量子位)进行连续操作来校正综合症,如果序列可以得到奖励 ,则错误得到更正。
虽然许多用于纠错的机器学习都侧重于根据某种设置方案用物理量子位表示逻辑量子位的表面代码,但增强剂也可以与代码无关地设置(有人可以说,他们与解码策略一起学习了代码 )。量子存储器已经做到了这一点,量子系统应该在其中存储而不是操纵量子状态(Nautrup等人,2018),以及在反馈控制框架中保护量子位免受退相干(Fösel等人, 2018)。最后,除了传统的强化学习之外,射影模拟等新策略也可用于对抗噪音(Tiersch等人,2015)。
总而言之,用于量子误差校正的机器学习是一个具有多层复杂性的问题,对于实际应用而言,它需要相当复杂的学习框架。尽管如此,对于机器学习,尤其是强化学习,它是一个非常好的选择。