估计移动和嵌入式人体姿势
- 1. 背景
-
- 1.1 获取小网络的方法
- 1.2 判断模型的指标
- 1.3 经典网络结构
- 1.4 源码
- 1.5 正确阅读论文的方法
- 1.6 分组卷积(Group Convolution)
- 2. 移动应用模型
-
- 2.1 MobileNet -V1 (2017 Google)
-
- 2.1.1 卷积概念可以深度分离
- 2.1.2 卷积过程可以深度分离
- 2.1.3 可分离卷积计算成本深度
- 2.1.4 网络结构
- 2.1.5 超参
- 2.1.6 实验结果
- 2.1.7 局限性
- 2.2 MobileNetV2
-
- 2.2.1 卷积可分离深度
- 2.2.2 线性瓶颈 (Linear Bottlenecks)
- 2.2.3 卷块的变体
- 2.2.4 反向残差(Inverted residuals)
- 2.2.5 网络结构
-
- 2.2.5.1 线性瓶颈深度可分离卷积结构 (bottleneck depth-separable convolution)
- 2.2.5.2 不同架构的卷积块比较
- 2.2.5.3 最大通道数/内存比较
- 2.2.6 实验结果
-
- 2.2.6.1 不同网络的性能曲线
- 2.2.6.2 线性瓶颈和反向残差Top 1 Accuracy的影响
- 2.2.6.3 性能比较(基于COCO数据集)
- 2.2.6.4 性能比较(基于ImageNet数据集)
- 2.3 MobileNetV3
-
- 2.3.1 在Pexel 手机上的性能
- 2.3.2 高效移动构建块(Efficient Mobile Building Blocks)
- 2.3.3 网络搜索(Network Search)
-
- 2.3.3.1 增强探索空间
- 2.3.3.2 SENet (Squeeze-and-Excitation Networks)
- 2.3.4 感知平台的NAS用于逐块搜索 (Block-wise Search)
- 2.3.5 NetAdapt用于逐层搜索(Layer-wise Search)
- 2.3.6 网络改善
-
- 2.3.6.1 重新设计耗时的层
- 2.3.6.2 非线性(激活)函数
- 2.3.7 网络模型
- 2.3.8 实验结果
-
- 2.3.8.1 分类(Classification)
- 2.3.8.2 检测 (Detection)
- 2.3.8.3 语义分割 (Semantic Segmentation)
- 2.4 网络设计空间的设计 (DNDS)
-
- 2.4.1 网络设计进化史
- 2.4.2 设计设计空间 (Design Space Design)
-
- 2.4.2.1 设计空间设计的工具(Tools for Design Space Design)
- 2.4.2.2 AnyNet设计空间(The AnyNet Design Space)
- 2.4.2.3 RegNet设计空间
- 2.4.3 比较移动设备的性能
- 3. 估计基于深度图的位置
-
- 3.1 数据集
- 3.2 估计基于单深度图的有效人体姿势
-
- 3.2.1 数据
- 3.2.2 实现方案
-
- 3.2.2.1 深度图像特征(Depth image features)
- 3.2.2.2 随机森林( Randomized forests)
- 3.2.2.3 叶节点预测模型(Leaf node prediction models)
- 3.2.2.4 汇总预测(Aggregating predictions)
- 3.3 基于推理嵌入多任务学习的深度图像人体姿势估计
-
- 3.3.1 框架
- 3.3.2 网络结构
-
- 3.3.2.1 全连接网络 (FCN: Fully Convolutional Network)
- 3.3.2.2 内置推理MatchNet (Inference Built-in MatchNet)
- 3.3.2.3 训练
- 3.3.2.4 实验结果
- 3.4 基于单个深度图的实时3D位置估计
-
- 3.4.1 方法
-
- 3.4.1.1 第一阶段(估计2D位置)
- 3.4.1.2 第二阶段(估计3D位置)
- 3.4.1.3 实现流程
- 3.4.2 Slim Hourglass Block (SHB) for Faster Inference
- 3.4.3 堆叠沙漏网络用于人体姿势估计
-
- 3.4.3.1 相关工作
- 3.4.3.2 网络结构
- 3.4.3.3 有中间监督的堆叠沙漏
- 3.4.3.4 训练细节
- 3.4.3.5 实验结果
- 3.4.3.6 不同网络的训练过程
- 3.5 基于RGB-D的地面检测
-
- 3.5.1 基于RGB-D的新型地面检测方法
-
- 3.5.1.1 数据预处理
- 3.5.1.2 图像坐标系变为世界坐标系
- 3.5.1.3 地面检测算法
- 3.5.1.4 实验结果
- 3.5.1.5 结论
- 3.5.2 基于RGB-D Sensor的地面检测
-
- 3.5.2.1 提供的解决方案
- 3.5.2.2 俯仰角(Pitch)在不变场景下检测地平面
- 3..2.3 俯仰角(Pitch)和翻滚角(Roll)变化场景下检测地平面
- 3.5.2.4 实验结果
- 3.6 基于单个深度图精确位姿估计
- 3.7 基于超像素聚类人体姿态识别 (深度图)
-
- 3.7.1 深度图像中的人体特征点提取
-
- 3.7.1.1 点云数据的超像素处理
- 3.7.1.2 人体肢端点的提取
- 3.7.1.3 人体部位的提取
- 3.7.1.4 聚类特征点的提取
- 3.7.2 基于稀疏回归模型的骨骼点提取
-
- 3.7.2.1 基于拉格朗日乘子法的约束问题求解
- 3.7.2.2 稀疏回归模型的求解
- 参考
1. 背景
-
现有的大部分模型都是在PC(带有超级强大GPU)上进行的,所以在嵌入式设备上基本无法使用
-
- 人体姿态估计主要是指在图像或者视频中找到人体的重要关节的位置(比如头,手、脚、肩部、膝盖、肘部等)
-
- 利用各个关节点的位置进行适当的组合构造出的人体姿态特征
-
- 优化模型:大大地减少参数
- 使用ARM中的GPU和NEON
-
-
生成方法(Generative Methods)/有模型方法
- 先预定义身体部件模型,然后与输入的深度图像进行匹配
- 使用PSO, ICP最小化手工特征(hand-crafted)代价函数
- 通过将人体分为多个部件组合成模型,通过部件检测器检测部件的位置,进行部件之间的概率计算,从而对图像中的人体进行姿态估计
- :不需要建立庞大的数据库,同时在模型建立完毕以后对于符合模型视角的姿态具有较高的识别率
- :复杂的人体模型构建较为困难,并且在实际情况中由于人体姿态具有多样性,使得很难构建出具有很强代表性的人体模型;所以此方法很难面对具有庞大数据量的真实情况
-
- Therepresentationand matching of pictorial structures (1973)
- Cascaded models for articulated pose estimation (2010)
- Multi-view Pictorial Structures for 3D Human Pose Estimation (2013)
- Articulated part-based model for joint object detection and pose estimation (2013)
- Expanded parts model for human attribute and action recognition in still images (2013)
- 基于约束树形图结构外观模型的人体姿态估计 (2014)
- 一种基于图结构模型的人体姿态估计算法 (2013)
-
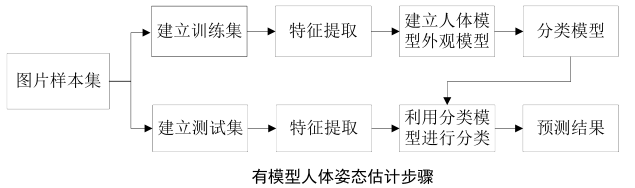
-
- 尺度不变特征变换法(SIFT:Scale Invariant Feature Transform)
- 梯度方向直方图特征(HOG:Histogram of Oriented Gradient)
-
判别方法(Discriminative Methods)/无模型方法
- 根据输入的深度图像,直接定位关节位置
- 大多数基于深度学习的方法
- 通过对每张图像的像素点进行分析,通过先进的特征提取方法来估计人体部件的位置
- :不需要建立复杂的人体模型,从而使用得此方法不受模型的约束,可以适用于真实应用场景中
- :
- 为适应现实生活中,需要建立庞大的数据库
- 对硬件条件具有较高的要求
-
- Real-time human pose recognition in parts from single depth images (2013, Kinect, Shotton)
- Efficient regression of general-activity human poses from dept images (2011)
- Accurate 3d pose estimation from a single depth images (2011)
-
- 人体部件尺度特征
- 赵文闯 《深度图像中基于的人体识别方法》 2012
- 四维特征向量 ( d 0 , d 45 , d 90 , d 135 ) (d_0, d_{45}, d_{90}, d_{135}) (d0,d45,d90,d135)通过除以图像中人体身高进行归一化
- :不同尺度下的人体姿态估计有着天然的优势
- :由于此特征没有很好的运用到部件在空间中处于不同位置,且不同部件的区分效果并不明显
- 深度图像偏移比较特征
- Shotton J (Kinect)
- :运算简单、效果较好
- :由于此特征维数较低、在部件内部反应较小,所以使用在实际应用中偏移比较特征的鲁棒性和准确性并不是很好
- 深度图像方向梯度特征
- 方向梯度特征:像素点所在平面与深度相机所在平面的夹角
- D G o D p ( x , y ) = t a n − 1 d y d x = t a n − 1 p ( x , y + 1 ) − p ( x , y − 1 ) p ( x + 1 , y ) − p ( x − 1 , y ) DGoD_{p(x,y)} = tan^{-1} \frac{dy}{dx} = tan^{-1}\frac{p(x,y+1) - p(x, y-1)}{p(x+1, y) - p(x-1, y)} DGoDp(x,y)=tan−1dxdy=tan−1p(x+1,y)−p(x−1,y)p(x,y+1)−p(x,y−1)
- p ( x , y ) p(x,y) p(x,y):是深度图像在x列y行处的深度值
- 方向梯度取值范围: [ 0 ° , 360 ° ] [0°, 360°] [0°,360°]
- d x = 0 a n d d y = 0 dx=0 \quad and \quad dy=0 dx=0anddy=0,则DGoD=0
- d x > 0 a n d d y = 0 dx > 0 \quad and \quad dy=0 dx>0anddy=0,则DGoD = 360°
- d x < 0 a n d d y = 0 dx < 0 \quad and \quad dy=0 dx<0anddy=0,则DGoD = 180°
- D G o D p ( x , y ) = t a n − 1 d y d x = t a n − 1 p ( x , y + i ) − p ( x , y − i ) p ( x + i , y ) − p ( x − i , y ) DGoD_{p(x,y)} = tan^{-1} \frac{dy}{dx} = tan^{-1}\frac{p(x,y+i) - p(x, y-i)}{p(x+i, y) - p(x-i, y)} DGoDp(x,y)=tan−1dxdy=tan−1p(x+i,y)−p(x−i,y)p(x,y+i)−p(x,y−i)
- i ∈ ( i m i n , i m a x ) i \in (i_{min}, i_{max}) i∈(imin,imax)
- 目的:解决dx=0或 dy=0过多的问题
- 不同部件可能位于同一平面,也可能位于不同平面,此方法不能区分位于同一平面但不同部件的点,量级梯度特征可解决此问题
- 深度图像量级梯度特征
- 传统的深度图像量级梯度(MGoD:Magnitude Gradient of Depth) M G o D p ( x , y ) = [ p ( x + 1 , y ) − p ( x − 1 , y ) ] 2 + [ p ( x , y + 1 ) − p ( x , y − 1 ) ] 2 MGoD_{p(x,y)} = \sqrt {[p(x+1, y) - p(x-1, y)]^2 + [p(x,y+1) - p(x, y-1)]^2} MGoDp(x,y)=[p(x+1,y)−p(x−1,y)]2+[p(x,y+1)−p(x,y−1)]2
- p(x,y):是深度图像在x列y行处的深度值
- 优化的深度图像量级梯度 M G o D ( I , x ) = d I ( x + u d I ( x ) ) − d I ( x + v d I ( x ) ) MGoD_{(I,x)} = d_I(x + \frac {u}{d_I(x)}) - d_I(x + \frac {v}{d_I(x)}) MGoD(I,x)=dI(x+dI(x)u)−dI(x+dI(x)v)
- $MGoD_{(I,x)} : 表 示 深 度 图 像 :表示深度图像 :表示深度图像I 中 位 置 为 中位置为 中位置为x$的像素点的量级梯度特征值
- d ( ⋅ ) d({\cdot}) d(⋅):此点的深度信息
- u 和 v u和v u和v:分别为 x x x点在水平和垂直方向的偏移量
- 传统的深度图像量级梯度(MGoD:Magnitude Gradient of Depth) M G o D p ( x , y ) = [ p ( x + 1 , y ) − p ( x − 1 , y ) ] 2 + [ p ( x , y + 1 ) − p ( x , y − 1 ) ] 2 MGoD_{p(x,y)} = \sqrt {[p(x+1, y) - p(x-1, y)]^2 + [p(x,y+1) - p(x, y-1)]^2} MGoDp(x,y)=[p(x+1,y)−p(x−1,y)]2+[p(x,y+1)−p(x,y−1)]2
- 人体部件尺度特征
-
混合方法(Hybrid Methods)
- 把生成方法和判别方法结合使用
- 使用自动编码器学习潜在空间
-
-
-
- 易受光照变化、背景、阴影和噪声等的影响
-
- 逐像素分类的方法
- 基于概率图模型的方法
- 基于特征点的方法
- 基于深度学习的方法
-
-
- 将深度图像上邻近区域内像素对的深度差值作为部位特征,来区分身体的不同部位,然后再结合随机决策森林的方法,将每一个像素进行分类
- 在逐像素分类的方法中,首次发表于2011 年的内置于Kinect 中使用的方法最具有代表性,该方法由Shotton 等提出,他们的做法是将一个区域内人体的像素对应的深度之间的差值作为特征,然后利用随机决策森林进行训练,对于每一个像素进行分类贴上部位标签,然后利用部位的信息再将这些特征回归到关节点。
- 这种方法实时性很好,并且在准确性上也有很好的表现,但是这种方法需要海量的带标签的数据进行很长时间的训练才能达到良好的效果。基于Shotton 等提出逐像素分类方法的开拓,越来越多的研究人员受到该方法的启发,并在该方向上取的了一定的进步。逐像素分类的方法目前只能应用于深度图像。
-
- 基本思想:设计像素或者像素对之间的特征,将人体像素通过分类方法对应到人体不同部位,然后再将人体对应部位信息优化到人体关节点信息。
- 这种方法的准确性比较高
-
- 需要大量的带标签的训练数据进行模型的训练才能达到能够接受的效果
- 训练时间也很长,工作量极大,只能应用在特定场景中
-
- Multi-task forest for human pose estimation in depth images (Lallemand J)
- 提出了一种新颖的方法,在进行随机森林训练时,除了将深度图像中人体的每一个像素对应到相应的三维关节点位置,还将每一个像素与人体的运动状态进行关联,将人体运动信息整合到目标函数中,改善了人体姿态预测的精度
- The Vitruvian manifold: inferring dense correspondences for one-shot human pose estimation (Taylor J)
- 使用回归森林来使深度图像与身体模型相对应,对于输入的深度图像,通过回归森林推断出对应的人体模型,然后优化模型参数,得到优化后的关节点位置,得到最终人体姿态
- An adaptable system for RGB-D based human body detection and pose estimation (Buys K)
- 使用随机森林将深度图像中每一个像素与身体部位联合起来,并通过在部位中聚类中以及人体关节点间的约束关系得到初始骨架模型,然后再结合外观模型,将人体从彩色图像中分割出来,逐步迭代得到最终人体姿态
- Human body part estimation from depth images via spatiallyconstrained deep learning (Jiu M)
- 基于卷积神经网络使用身体部位的空间特征进行逐像素分类,而且像素分类的性能有了极大提高
- Accurate realtime full-body motion capture using a single depth camera (Wei X)
- 使用混合动作捕捉系统将3D 姿态跟踪与人体检测结合,并做到 了实时人体姿态估计的效果
- Multi-task forest for human pose estimation in depth images (Lallemand J)
-
- 是指把人体模型用刚体或者非刚体的部件来表示,这些部件之间用相连接的边来约束,最终能够用人体部件分配的先验概率优化问题定位人体的每一个部件,识别人体姿态并达到识别人体每一个关节的目的
- 这种方法在彩色图像和深度图像中都可以应用,有许多的实现。
- 基于概率图模型来解决问题,实质上是指通过概率模型来推理结果,整个过程包括学习模型和基于模型进行推理两个部分。
- 概率图模型指的是结合了概率论和图论相关知识,用图形的方式去表达变量之间的关系的模型的一类总称
- 概率图模型中的图主要是由点和边构成:
- 点代表随机变量
- 边指的是与边连接的点之间的概率关系
- 常见的概率图模型主要包括:
- 马尔科夫模型
- 贝叶斯模型
- 隐马尔科夫模型
- 实际应用中为了克服有时候单个模型对于问题的描述不够准确的情况,出现了混合模型,这种模型由概率图模型与其他模型或者理论相结合而形成。
-
- Controlled human pose estimation from depth image streams (Zhu Y)
- 人使用飞行时间成像装置来获取深度图像,并在深度图像上提取特征来估计人体姿态。其中这些特征是基于概率推断的方法来进行检测和跟踪的
- Bayesian 3D human body pose tracking from depth image sequences (Fujimura K)
- 使用深度图像和人体模型之间的对应关系,进行局部优化得到身体部位,进而得到当前帧的人体关节点。并通过贝叶斯推断的方法来跟踪图像序列中的人体关节点
- (Ganapathi V)
- 通过结合生成模型和判别模型来表示身体部位,并使用爬山搜索来解决最大后验推理问题
- Real-time simultaneous pose and shape estimation for articulated objects using a single depth camera
- 将关节形变模型嵌入到高斯混合模型中,并提出了一种用于将模板形状映射到主体形状的形状自适应算法。
- Controlled human pose estimation from depth image streams (Zhu Y)
- 综合以上提到几种概率图模型的方法,在人体姿态估计领域使用范围最广的是,此外基于混合概率图模型的方法也比较常见。基于概率图模型的方法主要是基于样本数据进行训练,学习模型的参数以及模型的结构,也即模型中各个节点之间的关系和概率密度函数等。训练好模型后即可基于已知参数进行变量取值的推断。
-
-
是指在深度图像上找到人体的目标点(通常为在人体深度图像上求测地距离,并将求得的极值点作为感兴趣的目标点)
-
常常利用深度图像中像素点的空间几何特点,首先将深度图像数据转换成点云数据,再利用空间中相邻点之间约束关系等,将点连接成连通图,然后将中心点作为起始点计算测地距离[38],通常挑选最大测地距离的点或者其他特征的极值点作为特征点
-
:就是在曲面上从A点走到B点(不允许离开曲面)的最短距离, G e o d e s i c _ D i s t a n c e = d 12 + d 23 + d 34 + d 45 Geodesic\_Distance = d_{12} + d_{23} + d_{34} + d_{45} Geodesic_Distance=d
-