系列文章目录
文章目录
- 系列文章目录
- 【阅读笔记】【端侧AI】Smart at what cost? Characterising Mobile Deep Neural Networks in the wild
- 摘要
- 1 引言
- 2 研究问题&结果
- 3 Methodology
-
- 3.1 DNNs提取
- 3.2 离线DNN分析
- 3.3 模型评测
- 4 数据集收集&分析
-
- 4.1 数据集
- 4.2 设备上模型的分布
- 4.3 ML框架
- 4.4 模型类别
- 4.5 模型唯一性分析
- 4.6 跨快照时序分析
- 4.7 移动DNNs的层和运算
-
- DNN层和运算类型
- DNN运算和参数
- 5 端侧DNNs运行分析
-
-
- 5.1 On-Device DNN 延时
- 5.2 能耗
-
- 5.2.1 设备上的能耗和功耗
- 5.2.2 能耗由场景驱动
-
- 6 可用的优化
-
- 6.1 优化模型级别
-
- 权重聚类(weight clustering)
- 剪枝
- 量化
- 6.2 优化系统级别
-
- BatchSize的影响
- 线程数的影响
- 目标通用性和设备优化
- 特定加速硬件
- 优化机会
- 6.4 基于云的DNN模型
- 7 相关工作
- 8 讨论&之后工作
-
- 8.1 影响&趋势
- 8.2 局限性
- 9 结论
【阅读笔记】【端侧AI】Smart at what cost? Characterising Mobile Deep Neural Networks in the wild
阅读笔记,非全文翻译
- 了解NAS
- 什么是
- 什么是cloud offloading
摘要
- 本文对自然场景DNN通过跟踪模型和相应的移动设备,对其应用进行了全面研究。
- 分析了谷歌Play中超过16k个App使用和性能
- 测量模型的功耗
- 总结实验过程,开发gaugeNN,移动设备的自动部署、测量和分析DNN支持不同平台和框架的工具
- 本文的研究也研究差距,以及DNN优化动态和异构移动生态系统的必要性。
1 引言
- 把DNN对移动设备部署的相关研究:
- 由于移动设备太多,开发人员很难评估性能并优化硬件。
- 本文贡献:
- 设计了gaugeNN,自动提取、分析和评估(benchmark)最受欢迎的自然场景app中的DNN模型。
- 用gaugeNN分析了16k个app和DNN模型分析了云的使用、架构、层算子和优化DNN API的调用。
- 分析过去一年GooglePlay app分析结果。
- 数百种不同设备的不同能力DNN运行时测量模型并分析它们和。
- 分析了现有工具对模型和系统级别的优化方法,并提出了指导开发者如何优化的建议DNN。
2 研究问题&结果
三个研究问题:
- 考虑前沿ML在移动场景下,研究和部署了许多工具和设备的模型app上?被开发者用在哪个任务上?
- 这些模型是如何部署在各种智能手机生态系统中的?它们能有效地执行不同的任务和目标吗?
- 普通的模型优化和系统层面的优化是如何让手机在自然场景中推理得更快的?还能改进吗?
- 使用端侧开发者模型,或对某项任务进行微调,并依赖于大型任务 。
- 低档设备DNN相关任务明显较慢。
- 随着代际的增加,设备的代际增加,因为SoCs集成硬件加速。
- 但是电池技术没有这样的曲线。
- 使用主流框架的现成模型级优化往往不会带来推理延迟或内存延迟,而是关注模型的压缩能力。
- SoC厂商定制的工具能提供显着的运行时的帮助,但限制了使用的推广
- 针对特定目标的模型部署在自然场景中没有发现。
3 Methodology
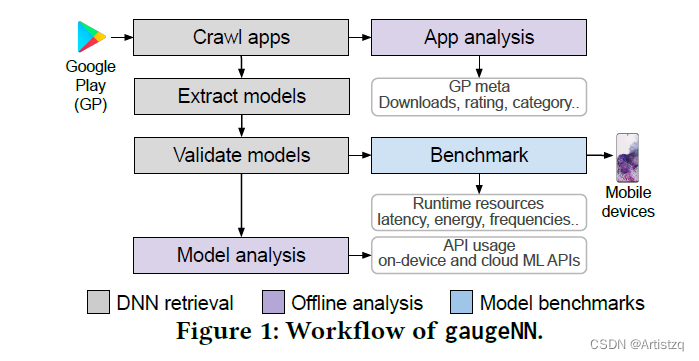
3.1 DNNs提取
find, extract, and validate
- 与69个已知框架已知框架进行比较。
- 移除非DNN模型的文件;加密和混淆模型没有被实验分析;程序自动从GP省略了下载模型;
3.2 离线DNN分析
App两种计算方法:①本地计算;②将计算转移到其他资源设备(云等)。
- DNN被表示有向无环图DAG,gaugeNN获取模型的权重,FLOPs,参数、推理延迟、能耗和内存占用。
- 反编译源码为smali文件,查看API调用,Google FireBase, Google Cloud and Amazon AWS ML services.
- 如图3。看不懂。
- 通过Monsoon power monitor。为了防止安卓电池省电机制杀后台,评测期间通过安卓电量管理服务保持屏幕常亮,屏幕的功耗也被测量了。
- 两个版本,20200214和20210404的Google Play
- 模型都是分布在主APK里的(就是没有通过扩展包之类的方法下载)
- 没有发现开发者选择使用某个设备专用的模型,开发人员更喜欢解决方案的通用性
- 这里的模型不是表2中的全部,剩下的是被加密和混淆的
- caffe已经被停止更新了,还能被用这么多,零人吃惊
- top:通讯和金融类别的,其次:图像和美颜,传统的DNN领域
- 作者人工地深入查看了名称,输入输出维度和层的类型,来判别其用途。
- 计算机视觉>89%,NLP17个模型,音频15个模型
- 有4个模型用到传感器数据
- 大多数CV:人脸,目标,轮廓检测;大多数音频:环境声音检测;大多数NLP:文本补全;大多数传感器:运动跟踪
- 只有318(表3中的19.1%)个模型是特制的。
- 最流行的模型:物体检测:FSSD;人脸检测:Blazeface。MobileNet是跨任务最流行的模型。
- 遇到了多次处理常见任务的模型,比如信用卡信息识别,姓名日期
- 排除掉重复的模型,剩下模型的9.02%,与至少一个其他模型,共用至少20%的权重。4.2%只有三层不同,证明开发者只微调了一小部分
- 没有检测到on-device的微调,因为计算要求太大,且,意识到这种的开发者也太少。
- DNN模型在安卓App中的部署翻倍了,快速增长
- TFLite从81.6%增长到86.1%,caffe和ncnn增长了,TF下降了,因为TFLite的存在
- 疫情期间通讯软件变得更加重要,开发者的重心转移到这上面来,金融也是。
- 生活方式等软件DNN减少了,因为人们在家里
- 使用DNN的App也在飞速增长,从236-377,2020.2-2021.4
- convolution layers being amongst the most popular layer types across modalities (34%, 10%, 20% for image, text and audio, respectively).
- on average the heaviest deployed vision models belong to .
- for NLP the heaviest tasks belong to .
- for audio the heaviest deployed task is .
- 以上结论只针对被跟踪分析的模型,不是普适的结果
- 图8,延时和FLOPs非线性的,不仅受模型架构影响,也受不同设备影响(显然如此)。
- 低端和中端的差距,比中端到高端差距更大
- 芯片(骁龙845、855、888)随着代际增加,延时有改善,76,58,35ms,但值得注意:,即使宣称说两代之间有着AI加速
- a图看出,消耗能量和负载相关,和设备无关
- b图看出,新代设备功耗更大,原因也很直接,做相近的功,但新代设备速度更快。
- c图看出,不同设备之间,推理效率()差不多,但新代设备稍有提升,表明更多的模型在新设备上可以运行得更有效率。
- 能耗似乎主要
- 这表明,是优化电池寿命的最大因素,不像推理速度,可以被多个因素比如制作商来改善。
- 作者没发现自然场景下有模型使用了weight clustering方法。
- TFLite为剪枝的层打上“prune_”前缀,但inference的时候通常会移除前缀。
- 同样没有发现这种层
- 但是检查了稀疏程度,3.15%的权重接近0,可能表明,基于权重大小的剪枝前景有限
- 10.3%的模型用了层,表明部署低精度模型作为模型压缩的一种方式
- 20.27%的模型使用了int8的权重张量,10.31%使用了int8的激活函数
- 现在有的硬件可以用NPU并行计算,multiple arithmetic precisions,但是
- 端侧AI开发者没有广泛使用这些优化方法
- 量化是最广泛使用的优化方法,但还有一些先进的混合量化方案有待支持
- 4个线程,只考虑了TFLite
- 吞吐量的规模是线性的,表明没有遇到瓶颈
- S21推理得最快,比A20和A70更快
- 作者认为继续调高batchsize会导致内存带宽瓶颈或内存错误,但是打算以后再研究…
- 线程亲和性参数
- 发现,不同设备的最优线程数是不一样的,分别是4,2,4个线程
- 8线程表现都不好,遇到瓶颈了
- 线程数超过核心数都会导致大幅性能退化,如4a2,8a4,因为线程等待
- 线程数设置为核心数并没有提高性能,让作者意外,因为本以为可以减少数据在核心之间的迁移
- 71个(23.8%)使用了NNAPI,1个用了SNNPACK,3个用了SNPE。
- 很多App没有按承诺所说,针对硬件加速,或使用的核操作
- 用XNNPACK更好
- NNAPI不行,可能是厂商的NN驱动没调好
- 使用SNPE的GPU和CPU比原厂GPU和CPU要好
- 厂商提供了没有优化的CPU
- DSP运行INT8,GPU、CPU全精度
- 共524个App,是2020的2.33倍;452用谷歌,72个app用亚马逊
- 开发者主要用云端API来进行图像和视频的任务
- 有相关工作分析手机上的DNN模型,但缺少对**“DNN优化技术怎么影响最新的使用DNN的App”**的动向的相关研究。
- 主要有两个工作研究了自然场景下的DNN使用。
- Xu等人分析了谁使用了DNN模型并且分析了端侧DNN的使用案例。
- 有人调查了端侧DNN的保护安全问题,发现很多安卓App没有保护它们的DNN模型,没进行性能分析。
- 以上两文为起点,本文分析了包括延时、能耗、系统和模型级别的参数及优化等,提供了更全面的理解。
- 很多开发者使用现成的模型
- 许多开发者没有使用特定硬件加速,而是把通用性当作目标,在普通CPU或者中间件上运行。
- 预计迟早能量(就是电池和功耗)会是智能移动设备的瓶颈
- 将来多个DNN并存运行?
- on-device data变多,以后将在设备上在线学习
- 只分析了安卓
- 被加密的、被混淆的、在主apk文件之外的DNN模型没有被分析
- 没有调查模型的调用路径和推理频率,有些模型应该被经常调用,有的会少调用
- 在调查云端DNN的API使用时,忽略了那些使用自定义API的开发者
- 一个针对最流行的DNN支持的移动App的综合的经验研究
- 给移动程序开发者和DNN框架开发者都能提供指导
3.3 模型评测
4 数据集收集&分析
对的回答。
4.1 数据集
4.2 模型在设备上的分布
4.3 ML框架
4.4 模型类别
同样见图4。
4.5 模型唯一性分析
4.6 跨快照的时序分析
比较了差了一年的GooglePlay快照的分析,考虑了疫情影响
按类别讨论
4.7 移动DNNs的层和运算
DNN层和运算的类型
DNN运算和参数
图中没说明横杠是什么
5 端侧DNNs的运行时分析
回答RQ2。
5.1 On-Device DNN 延时
5.2 能耗
5.2.1 设备上的能耗和功耗
5.2.2 场景驱动得能耗
6 可用的优化
6.1 模型级别的优化
权重聚类(weight clustering)
剪枝
量化
6.2 系统级别的优化
测试了系统外界参数对模型的影响。
BatchSize的影响
线程数的影响
目标通用性和针对设备优化
在三个后端NNAPI,XNNPACK,SNPE上测试TFLite和caffe模型,在骁龙845板上