目录
- DNC: A deep neural network-based clustering-oriented network embedding algorithm 2021
- (O2MAC)One2Multi graph autoencoder for multi-view graph clustering 2020
DNC: A deep neural network-based clustering-oriented network embedding algorithm 2021
问题:当前的网络嵌入方法通常与具体任务分离。
为了有效地解决这一问题,本文提出了基于深层神经网络聚类的非属性网络数据节点嵌入方法(DNC)。首先,提出了一种利用随机漫游模型直接获取图形结构信息的预处理方法。然后,我们建议学习一个深层聚类网络,它可以与学习节点嵌入和集群分配相结合。
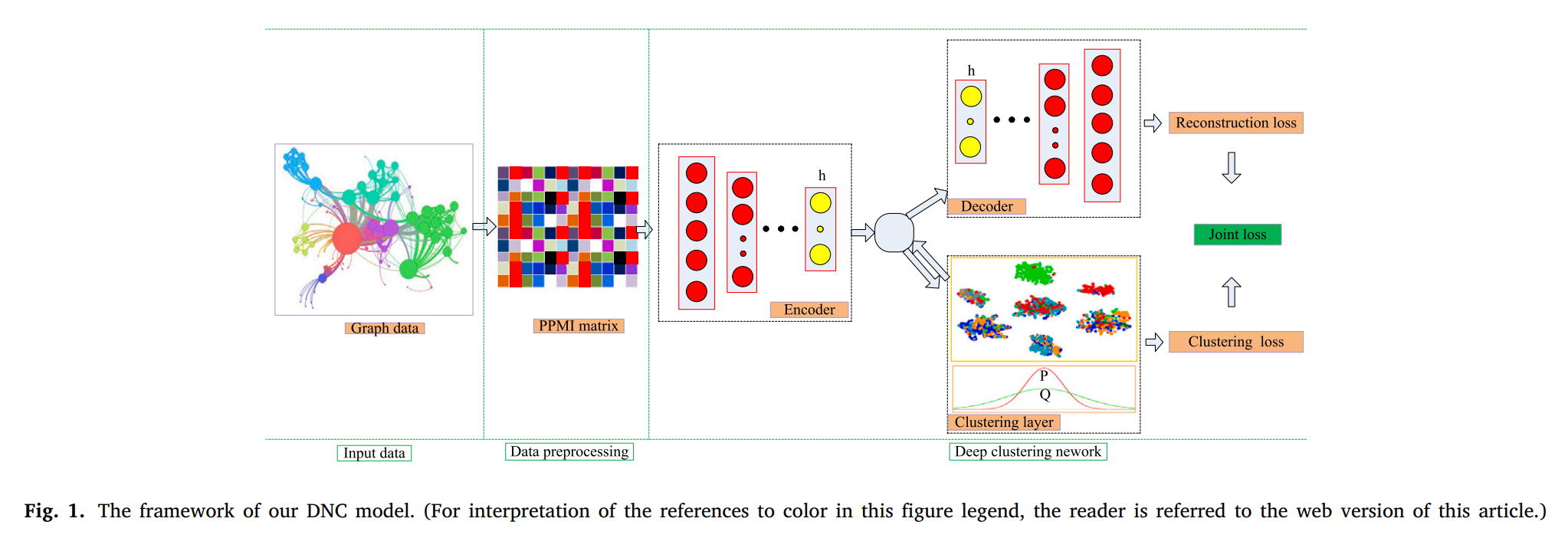
图1显示了 DNC 整体框架包括两部分: 数据预处理和深度节点聚类网络捕获结构信息。颜色的重要性分别代表聚类层PPMI不同簇数据点中的不同值属于聚类矩阵和聚类层。在第一个重量中,我们将给定的相邻矩阵转换为正点间互信息矩阵PPMI。在第二部分中,将得到的 PPMI 矩阵提供给由深层叠加自动编码器和聚类层组成的深层节点聚类网络,从而减少叠加自动编码器的重构损失和聚类损失。
为了获取网络的结构信息,借用了现有工作 DNGR 中计算 PPMI 矩阵法。 D对角矩阵,T转移矩阵(归一化A)。
然后,在 PageRank 在模型的激励下,采用随机冲浪模型计算 PPMI 矩阵。具体来说,重启时考虑随机漫游策略: 每次都有概率 μ,随机漫游将继续,概率1-μ,它将返回到原来的顶点,并重新启动过程。递推公式如下:
这里介绍了一个行向量 p k p_k pk, p k p_k pk第j项表示在k转换步骤后到达节点j的概率。 p 0 p_0 p0第一项为1,另一项为0,是独热向量。
k步后,概率矩阵M定义为: 然后计算PPMI,在自然语言处理中PPMI计算公式如下: 其中 ∣ F ∣ = ∑ s ∑ e # ( s , e ) |F| = \sum_s\sum_e \#(s,e) ∣F∣=∑s∑e#(s,e)(所有观察到的单词与上下文对集合个数),s和e表示当前单词和上下文单词。F表示观察到的单词和上下文对的集合。#(s,e)表示在F中出现的对(s,e)的次数。类似的,#(s)和#(e)表示F中s和e出现的次数。
因此,对于 N 个节点的网络,我们可以类比地确定 PPMI 矩阵的数学表达式,它被定义为: 其中 M ~ \tilde{M} M~是归一化的M矩阵。$\Theta 是 是 是\tilde M$中所有元素的和。col和row分别是每一行和每一列的和。
对网络数据进行处理后,将 PPMI 矩阵作为深层聚类网络的输入,深层聚类网络由深层叠加的自动编码器和聚类层组成。
Stacked autoencoder:
受自训练机制的启发 ,定义了基于聚类损失的聚类层,它最初是为了聚类图像数据而不是处理网络数据。
该机制可以将“有信心”(置信度高)的聚类分配作为软标签来指导优化过程。通过这种方式,可以迭代地优化集群性能。
损失的目标是最小化软聚类分布 Q和辅助目标分布P 之间的 Kullback-Leibler (KL)差异,Q是由 Student 的 t 分布测量的软标签分布。具体公式如下: 其中 q u v q_{uv} quv是节点嵌入表示 z u z_u zu和聚类中心 c v c_v cv之间的相似度。受到之前 t-SNE 模型的启发,我们使用 Student 的 t-distribution 作为核来度量这种相似性:
它可以看作是每个节点的软聚类分配分布。因此,我们可以直接从最后优化的 q 值中得到聚类结果。每个节点 i 的标签可以这样获取: 软聚类的概率越大,节点离聚类中心越近,越可能属于该社区。
目标分配 p u v p_{uv} puv可以定义为:
可以看到,目标分布P将Q提高到二次幂,以突出那些“自信的分配”。通过最小化P和Q两个分布之间的差异,聚类层在高置信度分配的指导下实现嵌入式学习。
一般情况下,当表示学习和聚类数据分离时,该算法只能得到节点聚类任务的次优解。因此,我们关联嵌入学习和聚类学习的框架。
因此,最终目标函数可以定义为:
类似的方法有一篇用于多视图聚类中
(O2MAC)One2Multi graph autoencoder for multi-view graph clustering 2020
本文首次尝试将深度学习技术引入到属性多视图聚类。
提出了一种新的任务引导的 One2Multi自动编码聚类框架。
One2Multi 图形自动编码器通过使用一个信息化的图形视图和内容数据来重建多个图形视图,从而学习节点嵌入。
因此,可以很好地捕获多个图的共享特征表示。在此基础上,提出了一种自训练聚类目标,迭代地改进聚类结果。
通过将自训练和自编码器重构集成到一个统一的框架中,该模型可以联合优化适合图形聚类的簇标记分配和嵌入。
图1显示了 O2MAC 的总体框架。该模型主要由两部分组成: one2Multi图自动编码器和自训练图聚类。一个多图自动编码器由一个信息图编码器和多视图解码器组成。采用启发式模块度方法,选择信息量最大的视图作为图形编码器的输入,将图结构和节点内容编码为节点表示。然后设计了一个多视图解码器来解码重建所有视图。由于 one2Multi图形自动编码器设计精巧,不仅可以学习共享表示,而且可以吸收不同视图的结构特征。此外,我们使用学习嵌入本身产生的软标签来监督编码器参数和簇中心的学习。在一个统一的框架内对多视图嵌入和聚类进行了优化,得到了更适合聚类任务的信息化编码器。
由于不同的图视图从不同的方面表示同一组节点之间的关系,而且内容信息由所有图视图共享,因此视图之间存在共享信息。此外,在许多场景中,通常存在一个信息量最大的视图支配社区表现。因此,可以从信息量最大的图视图和内容数据中提取信息量最大的视图和其他视图之间的共享信息,然后可以用于重构所有图形视图。
具体来说,首先将每个单视图的图邻接矩阵和内容信息分别提供给 GCN 层,以学习节点嵌入,然后对所学习的嵌入执行 k-means,以获得它们的聚类结果。基于聚类判别和邻接矩阵判别,我们计算每个图视图的模块度,并选择得分最高的图视图作为信息量最大的视图。使用模块度的原因是它提供了一个客观的度量来评价聚类结构
然后将选择的图结构 A ∗ A^* A∗和节点特征X输入自编码器,利用GCN作为图编码器。 这里是双层GCN:
除了优化重建损失之外,我们还将隐藏嵌入输入到一个自训练聚类目标中,从而最小化以下目标: Q 是软标签的分布,qij 用 Student 的 t 分布来表示节点 i 的嵌入子和簇中心 μj 之间的相似性: 它可以看作是每个节点的软聚类分配(隶属向量)。等式5中的 pij 是目标分布,定义为: 其中 f i = ∑ i q i j f_i = \sum_i q_{ij} fi=∑iqij 是软聚类频率,以规范每个中心的损失贡献。
首先预先训练 One2Multi 图形自动编码器,不需要自我训练的聚类部分,就可以得到一个训练有素的嵌入 z。然后执行自训练聚类目标来改进这种嵌入。为了初始化集群中心,我们在嵌入节点 z 上执行标准的 K-means算法,以获得 k 个初始质心
更新目标分布,作为“groundtruth”软标签的目标分布P 也依赖于预测的软标签。
因此,为了避免自训练过程中的不稳定性,每次 t 迭代都应使用所有嵌入节点更新 P。我们根据公式6和公式7更新 P。更新目标分布时,分配给 vi 的社区编号是: 其中 qij 是由 Eq.6计算得到的。如果目标分布的两次连续更新之间的标签分配变化(百分比)小于阈值 δ,则训练过程将停止。最后优化得到的 q 值可以得到聚类结果。