基于深度多模态网络的季节不变语义分割
(略读)
原文
摘要
对越野自主车辆的语义场景理解是一种有用的能力。虽然摄像头是语义分类中最常见的传感器,但由于照明、天气和季节的变化,使用摄像头图像的性能可能会降低。另一方面,主动传感器(如激光雷达)的3D这些因素的信息相对不变,这促使我们研究在这种情况下是否可以使用它来提高性能。本文提出了一种新的多模态卷积神经网络(CNN)结构由二维和三维流组成,通过将三维特征投影到图像空间中,实现鲁棒的像素语义分割。我们在新的越野地形分类基准中评估了我们提出的方法,结果表明,与纯图像相比baseline,导航相关语义类联合平均交叉度(IoU)提高了25%。
介绍
对于在非结构化越野环境中运行的自动驾驶车辆,按语义类别(如trail”、“grass”或“rock)了解其环境有助于安全仔细地导航。由于虚假信息可能导致碰撞或其他事故,必须有鲁棒的场景理解。 场景理解的一个重要步骤是语义图像分割,它在像素级对图像进行分类。近年来,深度卷积神经网络(CNN)超越传统计算机视觉算法,语义分割取得了最新进展[5、6、8、10、12、17、19]。
当训练集与测试集有明显的外观差异时,我们观察到,CNN由光照、天气和季节(图1)引起的分割性能受到影响。一个简单的解决方案是添加更多不同场景的培训数据,但由于需要收集数据并标记培训,这种方法很昂贵。 相反,解决这个问题的有效方法是使用额外的互补传感器,如激光雷达。相机在视觉范围和数据密度方面具有优势,而激光雷达在照明、天气和季节引起的外观变化方面具有优势。因此,激光雷达收集的图像和3D点云的组合方法是CNN利用其互补性创造机会。 但以下问题仍悬而未决:
1)如何联合使用两个传感器进行图像分割
2)对鲁棒分割有用的各种模式的特点是什么? 在本文中,我们提出了一个基于深度多模态网络的解决方案,该网络共同使用图像和三维点云数据,并输出分割图像。我们提出了一个带有投影模块的框架,使多模态网络能够学习二维和三维特征,并在培训过程中有效地结合不同领域的特征,以稳定地划分图像。 为了评估我们的方法对外观变化的鲁棒性,我们组装了一个标记图像和激光雷达数据集,从冬夏两个不同季节在越野位置行驶的改装全地形车辆中收集。 我们表明,我们提出的方法是高度准确的,有图像基线更能反映这种变化。
相关工作
一般来说,根据输入模式的数量,语义场景理解的相关方法大致分为两类:单模态(只有图像输入)或多模态(例如图像和三维点云)。
2.1基于单模态图像的方法
RGB图像的语义分割是一个活跃的研究课题。许多成功的方法使用图形模型,如马尔可夫或条件随机场(MRF或CRF)[1-4]。这些方法通常从过度分割图像到超像素开始,并从单个和相邻的片段中提取手工特征。图形模型使用提取的特性来确保相邻区域标签的一致性。 基于CNN该方法不再依赖于工程特征,而是通过从原始数据中学习强特征来实现最先进的分割性能[5、6、8]。CNN网络结构是方法之间的主要区别。Shelhamer等人[5]介绍了使用跳过层来细化所谓积层产生的分段。Badrinarayanan等人[6]提出了具有非冷却层的编码器-解码器系统结构。这些系统结构使用相对较慢VGG[7]系统结构。机器人学的一个重要目标是降低计算成本,Paszke在[9]的推动下,等人[8]采用瓶颈结构,构建一个参数少但精度相似的高效网络。基于这些架构,我们的网络图像部分。
2.2 Multimodal Approaches 多模态方法
研究人员使用图像和3D点云理解场景。Munoz等人[13]为我们的工作提供了一个主要启示,他们训练了两个经典级联,每个级联对应一个模态,并使用叠加方法在两个分类筛选器之间分层传播信息。纽曼艾尔。[14] 通过贝叶斯决策规则和支持向量机对单个激光雷达数据进行分类,并使用大多数共识来标记图像中的超像素。Cadena和Koseckˇa[15]提出了一个CRF该框架加强了从两个传感器覆盖范围中提取的独立特征之间的空间一致性。Alvis等人[16]从CRF从图像中提取外观特征,从3中提取外观特征D在点云中获取超像素集的全局约束。 还有几个基础CNN的方法使用RGB和深度(RGBD)通常来自三维或结构化照明传感器。Couprie来自等人[10]RGB-D的多尺度CNN特征图及来源RGB图像的超像素结合起来,以分割图像。Gupta等人[12]从颜色和编码深度中提取CNN检测室内物体的特征。它们在[11]中证明,基于对象检测计算的增强特性提高了分割性能。 Valada等人[17]最近提出了相关的建议RGBD方法。在这种方法中,首先学习相同的2D CNN分割不同的模态输入。然后,通过总结每一个CNN输出特征图,整合不同模式的特征,然后处理(后期整合卷积法)。尽管它们的融合发生在每个人身上CNN模型的输出(后期融合),但我们考虑从另一种模式中分层结合特征,因为美国有线电视新闻网学到的多个抽象层次被证明是有益的[ 19 ]。 我们使用RGBD方法的一个关键区别是,我们不仅学习2D特点,也学3D特征。3D特征包括2个有用的空间信息D中学难学。
3方法
为了在越野中安全导航,我们的目标是预测四个语义类别(高植被、崎岖不平、雨水、平坦地形和无信息)。相机是最常见的场景理解传感器,因为它在远距离(例如,可以检测到远处的障碍物)和密集数据方面具有优势。然而,当列车和测试图像集因照明、天气和季节变化而有显著差异时,基于图像CNN性能可能会受到影响。另一方面,激光雷达的三维信息对这些因素相对不变。另外,我们还使用3D点云数据帮助CNN了解一组更强大的功能来应对外观变化。
我们的深度多模网络(图2)联合使用来自相机的图像和来自激光雷达的3D点云并输出分割图像。我们的框架包括一个从图像中学习二维特征的图像网络,一个从点云中学习三维特征的点云网络,以及一个将学习到的三维特征传播到图像网络的投影模块。 3D特征的传播使图像网络与2相结合D/3D特征,并在训练期间学习更稳定的特征集。本节将详细介绍多式联运网络的这些主要组成部分。
3.1图像网络
图像网络的目标是从图像中学习二维特征θ2D,交叉熵损失分类最小化。网络应具有良好的分割性能,但也具有快速的预测时间和少量的参数,以便易于嵌入实时自治系统。基于这项工作,我们设计了它ENet该网络证明了其性能和现有模型(如[8]SegNet[6])相似,但推理时间更快,参数数量更少。ENet它包括初始、下采样、上采样和瓶颈模块,包括编码器部分(初始、阶段1-3)和解码器部分(阶段4-5)。瓶颈模块的系统结构是单个主分支和带卷积滤波器的分离分支。我们将在每个阶段多次使用它,使网络更深入,对网络退化的脆弱性更小[9]。图5(以上网络)描述ENet体系结构。请参考[8]了解更多关于网络的详细信息。
3.2点云网络
类似于图像网络,点云网络学习3D特征表示θ3D,损失函数是交叉熵,最小化分类的交叉损失。 在我们的实验中,我们使用图像网络(第三).1节),但在3D中使用3D卷积层、最大池层和上采样层。
(1考虑到性能,我们简化了点云网络,用规则卷积层代替膨胀层和不对称层。此外,我们用上采样层代替反褶积层,然后用3代替×3×3卷积层替换为步长1。简单来说,我们用同样的术语反褶积。
由于它们通常出现在越野中,我们希望预测高植被和地形的语义类别。
直观地说,地形区域应该比高植被区域更光滑;与地形区域相比,包括植被的空间相对不完全覆盖。Maturana和Scherer[18]利用这建一个3D CNN,将孔隙度作为输入,录着陆区检测。类似地,我们提供粗糙度和多孔特性(图4)作为网络的输入,而不是原始点云。我们的假设是,这些特征比原地表示所需的语义。 对于(i,j,k)索引的每个栅格体素2,我们通过计算从拟合平面到体素内每个点的平均残差来计算粗糙度特征R3Di,j,k[21]: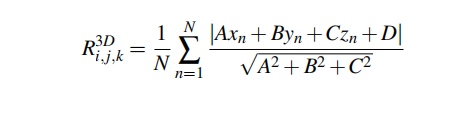
N是每个体素中的点数,x、y、z是每个点的位置,A、B、C、D拟合平面参数拟合平面参数(即Ax By Cy D=0)。对于空体素(即无点),我们将恒定的负粗糙度指定为0.1。 [外链图片存储失败,源站可能有防盗链机制,建议保存图片直接上传(img-BgzG7WBG-1642759031948)(C:\毕业设计\pic.PNG)]
3.3 投影模块
投影模块首先学习点云网络3D特征投影到2D在图像平面上。然后遵循图3中的瓶颈模块,以便向图像网络传播更好的特征。 在投影方面,我们通过针孔相机模型将每个元素的质地位置与激光雷达相比(x、y、z)映射到图像平面(u、v)上:
其中,fx、fy、cx、cy是相机的固有参数,R和t是从相机到激光雷达的3x3旋转矩阵和3x1平移矩阵。我们从原始点云维度(例如,图5中的16×4840)为每个体素大小采样(x,y,z)。这是为了解决由于3D maxpooling层减少了点云的维数而导致投影变得稀疏的问题。 我们应用z缓冲区技术来计算将多个激光雷达点投影到同一像素位置的像素。然后,我们使用最近邻插值对投影图像平面进行降采样,以匹配投影模块将合并到的图像网络层的大小(第3.4节)。 我们考虑一个固定体积的3D点云相对于激光雷达(秒4.3)。 因此,如果点云和图像的尺寸相同(例如,阶段1和阶段4的投影),则图像网络中的体素位置及其对应的投影位置是恒定的。在实践中,我们预先计算体素位置的索引及其对应的像素索引,并在网络中使用它们。
3.4多模态网络
图5总结了我们的多模网络架构:点云网络从粗糙和多孔点云学习3D特征,投影模块将3D特征传播到图像网络,图像网络将3D特征与从图像中提取的2D特征相结合。我们将投影模块应用于初始和第1-5阶段的输出,因为CNN学习的多层次特征是有益的[19]。
图5:多模式网络架构。上部2D部分是图像网络,
下部3D部分是点云网络。它们通过投影模块连接。ENet模块指的是图3中的模块。瓶颈模块下方的数字表示该模块的使用次数。