第1章 大数据概论
1.1 大数据概念
大数据(BigData):是指海量、高增长率、多元化的信息资产,不能在一定时间内用传统软件工具处理的数据集合,需要新的处理模式才能具有更强的决策能力、洞察力和流程优化能力。
主要解决海量数据存储和海量数据分析计算问题。
数据存储单数据存储单元:bit、Byte、KB、MB、GB、TB、PB、EB、ZB、YB、BB、NB、DB
1.2 大数据特点(4V)
1.2.1 Volume(大量)
大数据量很大,PB水平正常,增长速度快。
据IDC2018年11月发布的《数据时代2025》报告预测,2018年全球数据总量将为33ZB增至2025年的175ZB,相当于每天产生491EB的数据。
1.2.2 Velocity(高速)
这是大数据区别于传统数据挖掘的最明显的特征。大数据与大数据的重要区别在于两个方面:一方面,数据;另一方面,大数据对处理数据的响应速度有更严格的要求。例如,在实时分析场景中,对延迟的要求较低。数据的增长速度和处理速度是大数据高速度的重要体现。
1.2.3 Variety(多样)
多样性主要体现在三个方面、数据类型多、数据相关性强三个方面。 ① 互联网和物联网的发展带来了社交网站、传感器等多种数据来源。 由于数据来源于不同的应用系统和设备,决定了大数据形式的多样性。
② 有许多类型的数据,主要是非结构化数据。70%-85%的大数据是非结构化和半结构化的数据,如图片、音频、视频、网络日志和链接信息。
③ 数据之间的相关性强,交互频繁,如游客在旅途中上传的照片和日志,与游客的位置、行程等信息有很强的相关性。
1.2.4 Value(低价值密度)
隐藏在大数据背后的价值是巨大的。由于大数据中有价值的数据所占的比例很小,大数据的真正价值反映在大量不相关的数据中。通过机器学习、人工智能方法或数据挖掘方法对未来趋势和模式进行深入分析,挖掘和分析有价值的数据,并应用于农业、金融、医疗等领域,以创造更大的价值。
1.3 大数据应用场景
- 物流仓储:大数据分析系统帮助商家精细化运营,增加销量,节约成本。
- 零售:分析用户的消费习惯,方便用户购买商品,从而提高商品销售,如啤酒和尿布故事。
- 旅游业结合大数据能力和旅游需求,构建旅游业智能管理、智能服务和智能营销的未来。
- 商品广告推荐:给用户推荐可能喜欢的商品。
- 保险:数据挖掘和风险预测,帮助保险业精准营销,提高精细化和定价能力。
- 金融:多维度反映用户特征,帮助金融机构推荐优质客户,防范欺诈风险。
- 房地产:大数据全面帮助房地产行业,创造准确的投资政策和营销,选择更合适的土地,建造更合适的建筑,卖给更合适的人。
- 人工智能:大数据为人工智能提供数据支持。
第2章 从Hadoop讨论大数据生态的框架
2.1 Hadoop是什么
- Hadoop是一个由Apache基金会开发的分布式系统基础设施;
- 主要解决大量数据的存储、分析和计算问题;
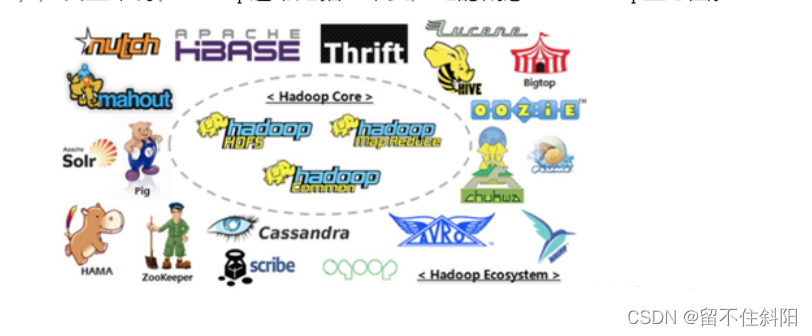
- 广义上说,Hadoop它通常指的是一个更广泛的概念-Hadoop生态圈;
2.2 Hadoop发展历史
- Lucene框架是Doug Cutting开发开发的开源软件Java写代码,实现和Google类似的全文检索功能,提供全文检索引擎架构,包括完整的查询引擎和搜索引擎。
- 2001年年底Lucene称为Apache基金会的子项目。
- 对于海量数据场景,Lucene面对与Google存储数据难,检索速度慢。
- 学习和模仿Google解决这些问题的方法:微版Nutch;
- 可以说Google是Hadoop的思想之源(Google三篇大数据论文):GFS—>HDFS; MapReduce—>MR; BigTable—>HBase;
- 2003-2004年,Google公开了部分GFS和MapReduce思想的细节,以此为基础Goug Cutting等待2年的业余时间实现DFS和MapReduce机制,使Nutch性能飙升;
- 2005年Hadoop作为Lucene的子项目Nutch部分正式引入Apache基金会;
- 2006年3月,MapReduce和Nutch Distributed File System(NDFS)分别纳入Hadoop项目中,Hadoop正式诞生标志着大数据时代的到来。
- 名字来源于Doug Cutting儿子的玩具大象。
2.3 Hadoop三个发行版本
Hadoop三大发行版:Apache、Cloudera、Hortonworks。
- Apache最原始(最基本)的版本最适合入门学习。
- Cloudera广泛应用于大型互联网企业。
- Hortonworks文档较好。
官网地址:http://hadoop.apache.org/releases.html 下载地址:https://archive.apache.org/dist/hadoop/common/
官网地址:https://www.cloudera.com/downloads/cdh/5-10-0.html 下载地址:http://archive-primary.cloudera.com/cdh5/cdh/5/
(1) 2008年成立的Cloudera是最早将Hadoop商业公司为合作伙伴提供服务Hadoop商业解决方案主要包括支持、咨询服务和培训。 (2) 2009年Hadoop的创始人Doug Cutting也加盟Cloudera公司。Cloudera产品主要为CDH,Cloudera Manager,Cloudera Support (3) CDH是Cloudera的Hadoop发行版,完全开源,比Apache Hadoop增强了兼容性、安全性和稳定性。 (4) Cloudera Manager它是一个集群软件分发和管理监控平台,可以在几个小时内部署Hadoop实时监控集群的节点和服务。Cloudera Support即是对Hadoop技术支持。 (5) Cloudera每年每节点4000美元。Cloudera可实时处理大数据的开发和贡献Impala项目。
官网地址:https://hortonworks.com/products/data-center/hdp/ 下载地址:https://hortonworks.com/downloads/#data-platform
(1) 2011年成立的Hortonworks雅虎和硅谷风险投资公司Benchmark Capital合资组建。 (2) 公司成立之初,吸收了约25至30项专项研究Hadoop2005年开始协助雅虎开发的雅虎工程师Hadoop,贡献了Hadoop 80%的代码。 (3) 雅虎工程副总裁雅虎工程Hadoop开发团队负责人Eric Baldeschwieler出任Hortonworks首席执行官。 (4) Hortonworks主要产品是Hortonworks Data Platform(HDP),也是100%开源产品,HDP除常见项目外,还包括常见项目Ambari,开源安装管理系统。 (5) HCatalog,元数据管理系统,HCatalog现已集成到Facebook开源的Hive中。Hortonworks的Stinger开创性的极大优化Hive项目。Hortonworks为入门提供了一个非常好、易用的沙盒。 (6) Hortonworks它开发了许多增强特性并提交给核心主干,这使得Apache Hadoop能够在包括Window Server和Windows Azure在内的Microsoft Windows本地运行在平台上。定价以集群为基础,每10个节点每年12500美元。
2.4 Hadoop优势(4高)
- 高扩展性:Hadoop它是一个高度可扩展的存储平台,可以存储和分发数百个并行运行的廉价服务器集群。与传统的关系数据库不同,它不能扩展到处理大量数据,Hadoop它可以为企业提供数百人TB运行在数据节点上的应用程序。
- 高效率:在MapReduce的思想下,adoop是并行工作的,以加快任务处理速度。
- 可靠性:Hadoop自动维护多份数据副本,假设计算任务失败,Hadoop能够针对失败的节点重新分配处理任务。
- 高容错性:Hadoop的一个关键优势就是容错能力强,当数据被发送到一个单独的节点,该数据也被复制到集群的其他节点上,这意味着故障发生时,存在另一个副本可供使用。
2.5 Hadoop组成(面试重点)
2.5.1 HDFS架构概述
HDFS(Hadoop Distributed File System)的架构概述,如图所示。 HDFS架构主要由四个部分组成,分别为HDFS Client、NameNode、DataNode和Secondary NameNode。
2.5.2 YARN架构概述
YARN架构概述,如图所示。
2.5.3 MapReduce架构概述
MapReduce将计算过程分为两个阶段:Map和Reduce, (1) Map阶段并行处理输入数据 (2) Reduce阶段对Map结果进行汇总
2.6 大数据技术生态体系
大数据技术生态体系如图所示。
图中涉及的技术名词解释如下: (1) Sqoop一款开源的工具,主要用于在Hadoop、Hive与传统的数据库(MySQL)进行数据的传递,可以将一个关系型数据库(MySQL,Oracle等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。 (2) Flume:Cloudera提供的一个高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。 (3) Kafka:一种高吞吐量的分布式发布订阅消息系统 (4) Storm:Storm用于“连续计算”,对数据流做连续查询,在计算时就将结果以流的形式输出给用户。 (5) Spark:Spark是当前最流行的开源大数据内存计算框架。可以基于Hadoop上存储的大数据进行计算。 (6) Oozie:Oozie是一个管理Hdoop作业(job)的工作流程调度管理系统。 (7) Hbase:HBase是一个分布式的、面向列的开源数据库。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。 (8) Hive:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。 (9) R语言:R是用于统计分析、绘图的语言和操作环境。R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。 (10) Mahout:Apache Mahout是个可扩展的机器学习和数据挖掘库。 (11) ZooKeeper:Zookeeper是Google的Chubby一个开源的实现。它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、 分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
第3章 Hadoop安装包目录结构
Hadoop-2.7.2目录结构
drwxr-xr-x. 2 test test 4096 5月 22 2017 bin
drwxr-xr-x. 3 test test 4096 5月 22 2017 etc
drwxr-xr-x. 2 test test 4096 5月 22 2017 include
drwxr-xr-x. 3 test test 4096 5月 22 2017 lib
drwxr-xr-x. 2 test test 4096 5月 22 2017 libexec
-rw-r--r--. 1 test test 15429 5月 22 2017 LICENSE.txt
-rw-r--r--. 1 test test 101 5月 22 2017 NOTICE.txt
-rw-r--r--. 1 test test 1366 5月 22 2017 README.txt
drwxr-xr-x. 2 test test 4096 5月 22 2017 sbin
drwxr-xr-x. 4 test test 4096 5月 22 2017 share
(1) bin目录:Hadoop最基本的管理脚本目录,这些脚本是sbin目录下管理脚本的基础实现。用户可以直接使用这些脚本来管理和使用Hadoop (2) etc目录:Hadoop的配置文件目录 (3) include目录:对外提供的编程库头文件(具体动态库和静态库在lib目录中),这些头文件均是用C++定义的,通常用于C++程序访问HDFS或者编写MapReduce程序。 (4) lib目录:该目录下存放的是Hadoop运行时依赖的jar包,Hadoop在执行时会把lib目录下面的jar全部加到classpath中。 (5) libexec目录:存放hadoop配置环境的一些文件,可用于配置日志输出、启动参数(比如JVM参数)等基本信息 (6) sbin目录:存放启动或停止Hadoop相关服务的脚本 (7) share目录:存放Hadoop的依赖jar包、文档、和官方案例 (8) logs目录:该目录存放的是Hadoop运行的日志,查看日志对寻找Hadoop运行错误非常有帮助。 :logs文件目录需要hadoop初始化之后才会自动生成。
第4章 Hadoop运行模式简介
(1) 本地模式:无需运行任何守护进程,所有程序都在单个JVM上执行,测试和开发时使用。 (2) 伪分布式模式:等同于完全分布式,只有一个节点。 (3) 完全分布式模式:多个节点一起运行。
第5章 Hadoop编译源码(面试重点)
5.1 前期工作准备
-
CentOS联网 配置CentOS能连接外网。Linux虚拟机ping www.baidu.com 是畅通的 注意:用root角色编译,减少文件夹权限出现问题
-
安装包准备(hadoop源码、JDK8、maven、ant 、protobuf) (1) hadoop-3.3.1-src.tar.gz (2) jdk-8u171-linux-x64.rpm (3) apache-ant-1.9.16-bin.tar.gz(build工具,打包用的) (4) apache-maven-3.6.3-bin.tar.gz (5) protobuf-2.5.0.tar.gz(序列化的框架) (6) cmake-3.14.5.tar.gz (7) yarn-v1.7.0.tar.gz(网络慢,下载不下来,可手动安装)
5.2 编译环境准备
:所有操作必须在root用户下完成
5.2.1 安装部署JDK
(1) JDK解压、配置环境变量 JAVA_HOME和PATH
[root@hadoop101 software] # rpm -ivh jdk-8u171-linux-x64.rpm
[root@hadoop101 software]# vi /etc/profile
#JAVA_HOME:
export JAVA_HOME=/usr/java/jdk1.8.0_171-amd64
export PATH=$PATH:$JAVA_HOME/bin
[root@hadoop101 software]#source /etc/profile
(2) 验证是否部署成功
java -version
5.2.2 安装部署Maven
(1) Maven解压、配置 MAVEN_HOME和PATH
[root@hadoop101 software]# tar -zxvf apache-maven-3.6.3-bin.tar.gz -C /opt/module/
[root@hadoop101 apache-maven-3.6.3]# vi conf/settings.xml
<mirrors>
<!-- mirror | Specifies a repository mirror site to use instead of a given repository. The repository that | this mirror serves has an ID that matches the mirrorOf element of this mirror. IDs are used | for inheritance and direct lookup purposes, and must be unique across the set of mirrors. | <mirror> <id>mirrorId</id> <mirrorOf>repositoryId</mirrorOf> <name>Human Readable Name for this Mirror.</name> <url>http://my.repository.com/repo/path</url> </mirror> -->
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>central</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>
</mirrors>
[root@hadoop101 apache-maven-3.6.3]# vi /etc/profile
#MAVEN_HOME
export MAVEN_HOME=/opt/module/apache-maven-3.6.3
export PATH=$PATH:$MAVEN_HOME/bin
[root@hadoop101 software]#source /etc/profile
(2) 验证是否部署成功
mvn -version
5.2.3 安装部署ant
(1) ant解压、配置 ANT _HOME和PATH
[root@hadoop101 software]# tar -zxvf apache-ant-1.9.16-bin.tar.gz -C /opt/module/
[root@hadoop101 apache-ant-1.9.16]# vi /etc/profile
#ANT_HOME
export ANT_HOME=/opt/module/apache-ant-1.9.16
export PATH=$PATH:$ANT_HOME/bin
[root@hadoop101 software]#source /etc/profile
(2) 验证是否部署成功
ant -version
5.2.4安装编译依赖包
(1) 安装glibc-headers、g++、gcc
[root@hadoop101 apache-ant-1.9.9]# yum install glibc-headers
[root@hadoop101 apache-ant-1.9.9]# yum install gcc gcc-c++
(2) 安装make和cmake 采用离线安装的方式 删除已安装的cmake
yum remove cmake -y
下载cmake-3.14.5
wget https://cmake.org/files/v3.14/cmake-3.14.5.tar.gz
解压后,进行配置
./configure --prefix=/usr/local/cmake
安装编译
make && make install
创建链接
ln -s /usr/local/cmake/bin/cmake /usr/bin/cmake
配置环境变量
vim /etc/profile
export CMAKE_HOME=/usr/local/cmake
export PATH=$PATH:$CMAKE_HOME/bin
使配置生效
source /etc/profile
验证是否部署成功
cmake -version
(3) 安装openssl库
[root@hadoop101 software]#yum install openssl-devel
(4) 安装 ncurses-devel库
[root@hadoop101 software]#yum install ncurses-devel
5.2.5 安装部署protobuf
(1) 解压protobuf ,进入到解压后protobuf主目录,/opt/module/protobuf-2.5.0,然后相继执行命令
[root@hadoop101 software]# tar -zxvf protobuf-2.5.0.tar.gz -C /opt/module/
[root@hadoop101 opt]# cd /opt/module/protobuf-2.5.0/
[root@hadoop101 protobuf-2.5.0]#./configure
[root@hadoop101 protobuf-2.5.0]# make
[root@hadoop101 protobuf-2.5.0]# make check
[root@hadoop101 protobuf-2.5.0]# make install
[root@hadoop101 protobuf-2.5.0]# ldconfig
[root@hadoop101 hadoop-dist]# vi /etc/profile
#LD_LIBRARY_PATH
export LD_LIBRARY_PATH=/opt/module/protobuf-2.5.0
export PATH=$PATH:$LD_LIBRARY_PATH
[root@hadoop101 software]#source /etc/profile
(2) 验证是否部署成功
protoc --version
5.2.6 安装部署yarn
(1) 下载yarn-v1.7.0.tar.gz
https://github.com/yarnpkg/yarn/releases/download/v1.7.0/yarn-v1.7.0.tar.gz
(2) 解压安装包、配置环境变量
export PATH=$PATH:/opt/module/yarn-v1.7.0/bin
(3) 验证是否部署成功
yarn -v
5.3 编译源码
(1) 解压源码到/opt/目录
[root@hadoop101 software]# tar -zxvf hadoop-3.3.1-src.tar.gz -C /opt/
(2) 进入到hadoop源码主目录
[root@hadoop101 hadoop-3.3.1-src]# pwd
/opt/hadoop-3.3.1-src
(3) 通过maven执行编译命令
[root@hadoop101 hadoop-3.3.1-src]#mvn package -Pdist,native -DskipTests -Dtar
等待时间30分钟左右,最终成功是全部SUCCESS,如下所示。
[INFO] Reactor Summary for Apache Hadoop Main 3.3.1: [INFO] [INFO] Apache Hadoop Main ................................. SUCCESS [ 1.030 s] [INFO] Apache Hadoop Build Tools .......................... SUCCESS [ 1.256 s] [INFO] Apache Hadoop Project POM .......................... SUCCESS [ 1.428 s] [INFO] Apache Hadoop Annotations .......................... SUCCESS [ 2.540 s] [INFO] Apache Hadoop Assemblies ........................... SUCCESS [ 0.093 s] [INFO] Apache Hadoop Project Dist POM ..................... SUCCESS [ 1.216 s] [INFO] Apache Hadoop Maven Plugins ........................ SUCCESS [ 3.588 s] [INFO] Apache Hadoop MiniKDC .............................. SUCCESS [ 1.588 s] [INFO] Apache Hadoop Auth ................................. SUCCESS [ 4.189 s] [INFO] Apache Hadoop Auth Examples ........................ SUCCESS [ 2.209 s] [INFO] Apache Hadoop Common ............................... SUCCESS [01:45 min] [INFO] Apache Hadoop NFS .................................. SUCCESS [ 3.716 s] [INFO] Apache Hadoop KMS .................................. SUCCESS [ 3.617 s] [INFO] Apache Hadoop Registry ............................. SUCCESS [ 4.302 s] [INFO] Apache Hadoop Common Project ....................... SUCCESS [ 0.036 s] [INFO] Apache Hadoop HDFS Client .......................... SUCCESS [ 29.727 s] [INFO] Apache Hadoop HDFS ................................. SUCCESS [01:30 min] [INFO] Apache Hadoop HDFS Native Client ................... SUCCESS [ 5.747 s] [INFO] Apache Hadoop HttpFS ............................... SUCCESS [ 5.463 s] [INFO] Apache Hadoop HDFS-NFS ............................. SUCCESS [ 2.853 s] [INFO] Apache Hadoop HDFS-RBF ............................. SUCCESS [ 34.599 s] [INFO] Apache Hadoop HDFS Project ......................... SUCCESS [ 0.043 s] [INFO] Apache Hadoop YARN ................................. SUCCESS [ 0.038 s] [INFO] Apache Hadoop YARN API ............................. SUCCESS [ 17.689 s] [INFO] Apache Hadoop YARN Common .......................... SUCCESS [ 37.159 s] [INFO] Apache Hadoop YARN Server .......................... SUCCESS [ 0.065 s] [INFO] Apache Hadoop YARN Server Common ................... SUCCESS [ 11.563 s] [INFO] Apache Hadoop YARN NodeManager ..................... SUCCESS [ 39.694 s] [INFO] Apache Hadoop YARN Web Proxy ....................... SUCCESS [ 3.030 s] [INFO] Apache Hadoop YARN ApplicationHistoryService ....... SUCCESS [ 5.204 s] [INFO] Apache Hadoop YARN Timeline Service ................ SUCCESS [ 4.539 s] [INFO] Apache Hadoop YARN ResourceManager ................. SUCCESS [ 29.506 s] [INFO] Apache Hadoop YARN Server Tests .................... SUCCESS [ 1.580 s] [INFO] Apache Hadoop YARN Client .......................... SUCCESS [ 6.155 s] [INFO] Apache Hadoop YARN SharedCacheManager .............. SUCCESS [ 2.723 s] [INFO] Apache Hadoop YARN Timeline Plugin Storage ......... SUCCESS [ 2.758 s] [INFO] Apache Hadoop YARN TimelineService HBase Backend ... SUCCESS [ 0.038 s] [INFO] Apache Hadoop YARN TimelineService HBase Common .... SUCCESS [ 4.042 s] [INFO] Apache Hadoop YARN TimelineService HBase Client .... SUCCESS [ 4.112 s] [INFO] Apache Hadoop YARN TimelineService HBase Servers ... SUCCESS [ 0.042 s] [INFO] Apache Hadoop YARN TimelineService HBase Server 1.2 SUCCESS [ 3.641 s] [INFO] Apache Hadoop YARN TimelineService HBase tests ..... SUCCESS [ 2.161 s] [INFO] Apache Hadoop YARN Router .......................... SUCCESS [ 4.146 s] [INFO] Apache Hadoop YARN TimelineService DocumentStore ... SUCCESS [ 2.776 s] [INFO] Apache Hadoop YARN Applications .................... SUCCESS [ 0.030 s] [INFO] Apache Hadoop YARN DistributedShell ................ SUCCESS [ 2.773 s] [INFO] Apache Hadoop YARN Unmanaged Am Launcher ........... SUCCESS [ 1.977 s] [INFO] Apache Hadoop MapReduce Client ..................... SUCCESS [ 0.249 s] [INFO] Apache Hadoop MapReduce Core ....................... SUCCESS [ 5.032 s]