作者丨OpenMMLab@知乎(已授权)
来源丨https://zhuanlan.zhihu.com/p/361101354
极市平台编辑
前言
torch 从 1.0 开始支持了 jit 模块可能包括以下部分:
在新计算图的中间表示 (Intermediate Representation),之后简称为 IR.
从 Python 代码导出IR两种方法,即 trace 与 script.
IR 优化以及 IR 解释器(翻译成具体操作 op).
本解释分为以下部分:
jit 简单介绍和两种导出方法的使用例子
jit 中 IR 的形式
导出 IR 两种方法,trace 与 script 的源码解读
IR 简单介绍优化
1 jit 简单介绍和使用例子
JIT 简介
就像前言一样,虽然这个解释的标题是 JIT,但真正可以称之为即时编译器的部分是导出 IR 后,即优化 IR 计算图并解释为相应的 operation 的过程,即 PyTorch jit 相关 code 优化通常是计算图级优化,如部分操作的集成,但对特定算子(如卷积)没有特定的优化,其依旧调用 torch 基本算子库.
也可以导出 IR 也就是 torchscript 之后,使用其他编译优化或解释器,如现在 script to a TensorRT engine, TRTtorch(https://github.com/NVIDIA/TRTorch) 转 tensorRT 的方案。
trace
给你一个简单的例子。
import torchvision.models as models resnet = torch.jit.trace(models.resnet18(), torch.rand(1、3、224、224) output=resnet(torch.ones(1,3,224,224)) print(output) output=resnet(torch.ones(1、3、224、224) resnet.save('resnet.pt')output 是我们导出的中间表示,它可以 save 使用其他框架
我们可以看看 output 中的 IR,即 torchscript 计算计算图是什么样子的。
graph(%self.1 : __torch__.torchvision.models.resnet.___torch_mangle_194.ResNet, %input.1 : Float(1:150528, 3:50176, 224:224, 224:1, requires_grad=0, device=cpu)): 72 : __torch__.torch.nn.modules.linear.___torch_mangle_193.Linear = prim::GetAttr[name="fc"](%self.1) 69 : __torch__.torch.nn.modules.pooling.___torch_mangle_192.AdaptiveAvgPool2d = prim::GetAttr[name="avgpool"](%self.1) 68 : __torch__.torch.nn.modulesjieshao.container.___torch_mangle_191.Sequential = prim::GetAttr[name="layer4"](%self.1) 22 : __torch__.torch.nn.modules.container.___torch_mangle_175.Sequential = prim::GetAttr[name="layer3"](%self.1) ... 56 : Tensor = prim::CallMethod[name="forward"](69, 55) 02 : int = prim::Constant[value=1]() 03 : int = prim::Constant[value=-1]() %input : Float(1:512, 512:1, requires_grad=1, device=cpu) = aten::flatten(56, 02, 03) 57 : Tensor = prim::CallMethod[name="forward"](72, %input) return (57)这便是 trace 使用方法的核心入口是torch.jit.trace,您需要导出的参数 model,合法输入 input,其一般原理与其名称相当,即跟踪模型 inference 过程中,逐一记录模型输入的操作,并对应 IR 从而获得原模型的操作 forward 的 IR。
:但这种实现方式有明显的缺陷,PyTorch 作为一个动态图网络,会有很多 input dependent 根据输入的不同,控制流语句可能会有所不同(if 或者 变长的 loop),这样就无法 trace 到完整的计算图。以下是一个 trace
失败的 case:
if x > 2.0: r = torch.tensor(1.0) else: r = torch.tensor(2.0) return r ftrace = torch.jit.trace(test, (torch.ones(1))) y = torch.ones(1) * 5 print(ftrace(y)) # results: tensor(2.) # 因为输入只离开分支,elsescript
@torch.jit.script def foo(x, y): if x.max() > y.max(): r = x else: r = y return r print(foo.graph) print(foo(torch.Tensor([0]), torch.Tensor([1]) print(foo(torch.Tensor([1]), torch.Tensor([0]) graph(%x.1 : Tensor, %y.1 : Tensor): %3 : Tensor = aten::max(%x.1) %5 : Tensor = aten::max(%y.1) # 可见控制语句确实被捕获, %6 : Tensor = aten::gt(%3, %5) %7 : bool = aten::Bool(%6) %r : Tensor = prim::If(%7) block0(): -> (%x.1) block1(): -> (%y.1) return (%r) tensor([1.]) tensor([1.])script 使用在你需要的地方 (fuction or nn.Module (默认追踪 forward )装饰装饰装置的吊装torch.jit.script,其转换方式跟进 trace 是完全不同的想法,script 直接解析你的 PyTorch 通过语法分析,将你的逻辑分析为语法树,然后转换为中间表示 IR。
虽然可以解决 trace 动态逻辑无法跟踪,但存在问题 Python 高度灵活的语法, 想完整支持解析各种 Python 操作几乎是不可能的,所以我们需要额外的时间来熟悉哪些写作方法可以分析,这大大降低了我们写代码的体验。
两者结合
两者各有优势,支持灵活集合。
import torch import torch.nn as nn import torch.nn.functional as F class MyModule(nn.Module): def __init__(self): super(MyModule, self).__init__() # torch.jit.trace produces a ScriptModule's conv1 and conv2 self.conv1 = torch.jit.trace(nn.Conv2d(1, 20, 5), torch.rand(1, 1, 16, 16)) self.conv2 = torch.jit.trace(nn.Con2d(20, 20, 5), torch.rand(1, 20, 16, 16))
def forward(self, input):
input = F.relu(self.conv1(input))
input = F.relu(self.conv2(input))
return input
scripted_module = torch.jit.script(MyModule())因此实际使用时候,可以有如下准则:
1 大部分情况 model 只有 tensor operation,就直接无脑 tracing2 带 control-flow (if-else, for-loop) 的,上 scripting3 碰上 scripting 不能 handle 的语法,要么重写,要么把 tracing 和 scripting 合起来用(比如说只在有 control-flow 的代码用 scripting,其他用 tracing)
如何扩展
trace 与 script 都不能转换第三方 Python 库中的函数,尽量所有代码都使用 PyTorch 实现, 自定义 op 需要注册成 jit 操作( torch 的 op 其实也注册了),最后转成 torchscript。
TORCH_LIBRARY(my_ops, m) {
m.def("warp_perspective", warp_perspective);
}更多可以参考官方教程
1 EXTENDING TORCHSCRIPT WITH CUSTOM C++ OPERATORS
https://pytorch.org/tutorials/advanced/torch_script_custom_ops.html
2 IR (torchscript)的基本表示
PyTorch 中的各种设计(parameter,计算节点等)在 torchscript 中是如何对应的呢?
这便是转换出的 IR 结果,torchscrip 以下结构组合。
名称
source code
简介
Modules |
module.h |
对标 nn.Module |
Parameters |
module.h |
对标 PyTorch 的 parameter |
Method |
Method.h |
包括 FunctionSchema 方法描述,Graph 实际计算图,GraphExecutor do the optimization and execution |
FunctionSchema |
function_schema.h |
描述参数与返回类型 |
Graph |
ir.h |
定义 function 的具体实现,包括 Nodes,Blocks,Values |
Nodes |
ir.h |
一个指令,如一次卷积运算,一次矩阵运算 |
Block |
ir.h |
控制语句 if,loop + list of nodes |
还有with,Value,Type等
# %x.1 value
graph(%x.1 : Tensor,
%y.1 : Tensor):
# aten::max 就是一个Node
# Tensor: Type-TensorType
%3 : Tensor = aten::max(%x.1)
%5 : Tensor = aten::max(%y.1)
%6 : Tensor = aten::gt(%3, %5)
%7 : bool = aten::Bool(%6)
%r : Tensor = prim::If(%7)
# Blocks
block0():
-> (%x.1)
block1():
-> (%y.1)
return (%r)3 导出 IR 的两种方式,trace 与 script
因为其具体实现颇为复杂,粘贴的源码也仅仅保留了简单 case 跑过的分支,并且省去了绝大部分细节,读者如有需要更多细节可以自行去源码查阅。
trace 实现
func,
example_inputs,
optimize=None,
check_trace=True,
check_inputs=None,
check_tolerance=1e-5,
strict=True,
_force_outplace=False,
_module_class=None,
_compilation_unit=_python_cu,
):
# 发现是nn.Module instacene forward, 追踪forward
if isinstance(func, torch.nn.Module):
return trace_module(
func,
{"forward": example_inputs},
None,
check_trace,
wrap_check_inputs(check_inputs),
check_tolerance,
strict,
_force_outplace,
_module_class,
)
# 传进来的是某个module instance的forward
if (
hasattr(func, "__self__")
and isinstance(func.__self__, torch.nn.Module)
and func.__name__ == "forward"
):
return trace_module(
func.__self__,
{"forward": example_inputs},
None,
check_trace,
wrap_check_inputs(check_inputs),
check_tolerance,
strict,
_force_outplace,
_module_class,
)
# 一个查找变量名的接口
var_lookup_fn = _create_interpreter_name_lookup_fn(0)
# C++ 入口
traced = torch._C._create_function_from_trace(
name, func, example_inputs, var_lookup_fn, strict, _force_outplace
)
# 检查traced 与 原func是否有差异
if check_trace:
if check_inputs is not None:
_check_trace(
check_inputs,
func,
traced,
check_tolerance,
strict,
_force_outplace,
False,
_module_class,
)
else:
_check_trace(
[example_inputs],
func,
traced,
check_tolerance,
strict,
_force_outplace,
False,
_module_class,
)
return traced我们发现经过简单的判断,代码便进入了 C++ 相关函数
traced = torch._C._create_function_from_trace(
name, func, example_inputs, var_lookup_fn, strict, _force_outplace
)我们去 C++ 中看下发生了什么
std::pair<std::shared_ptr<TracingState>, Stack> trace(
Stack inputs,
const std::function<Stack(Stack)>& traced_fn,
std::function<std::string(const Variable&)> var_name_lookup_fn,
bool strict,
bool force_outplace,
Module* self) {
try {
auto state = std::make_shared<TracingState>();
# setTracingState 将state 这个实例set下来,在之后计算节点get出来insert计算过程
setTracingState(state);
#state这个数据结构会在forward过程中存储trace到的计算过程
if (self) {
Value* self_value = state->graph->insertInput(0, "self")->setType(
self->_ivalue()->type());
gatherParametersAndBuffers(state, self_value, *self, {"__module"});
}
for (IValue& input : inputs) {
input = addInput(state, input, input.type(), state->graph->addInput());
}
auto graph = state->graph;
# 将python中的变量名解析函数绑定下来
getTracingState()->lookup_var_name_fn = std::move(var_name_lookup_fn);
getTracingState()->strict = strict;
getTracingState()->force_outplace = force_outplace;
# 开始forward,在计算发生时,会把计算记录到state中
auto out_stack = traced_fn(inputs);
// Exit a trace, treating 'out_stack' as the outputs of the trace. These
// are the variables whose values will be computed upon subsequent
// invocations of the trace.
size_t i = 0;
for (auto& output : out_stack) {
// NB: The stack is in "reverse" order, so when we pass the diagnostic
// number we need to flip it based on size.
state->graph->registerOutput(
state->getOutput(output, out_stack.size() - i));
i++;
}
setTracingState(nullptr);
if (getInlineEverythingMode()) {
Inline(*graph);
}
FixupTraceScopeBlocks(graph, self);
NormalizeOps(graph);
return {state, out_stack};
} catch (...) {
tracer::abandon();
throw;
}
}那么具体记录 operation 的过程发生在哪里呢?
pytorch/torch/csrc/jit/runtime/register_c10_ops.cpp
https://github.com/pytorch/pytorch/blob/4e976b9334acbcaa015a27d56540cd2115c2639b/torch/csrc/jit/runtime/register_c10_ops.cpp#L30
Operator createOperatorFromC10_withTracingHandledHere(
const c10::OperatorHandle& op) {
return Operator(op, [op](Stack& stack) {
const auto input_size = op.schema().arguments().size();
const auto output_size = op.schema().returns().size();
Node* node = nullptr;
std::shared_ptr<jit::tracer::TracingState> tracer_state;
// trace the input before unwrapping, otherwise we may lose
// the input information
if (jit::tracer::isTracing()) {
# 获取 tracer_state
tracer_state = jit::tracer::getTracingState();
auto symbol = Symbol::fromQualString(op.schema().name());
const auto& graph = tracer::getTracingState()->graph;
node = graph->create(symbol, 0);
tracer::recordSourceLocation(node);
const auto& args = op.schema().arguments();
int i = 0;
# 记录args
for (auto iter = stack.end() - input_size; iter != stack.end();
++iter, ++i) {
// TODO we need to refactor graph APIs (e.g., addInputs)
// appropriately; after that, we can get rid of the giant if-else
// block we will clean this tech debt together in the following PRs
auto type = args[i].type();
if (type->kind() == TypeKind::OptionalType) {
if (iter->isNone()) {
Value* none = graph->insertNode(graph->createNone())->output();
node->addInput(none);
continue;
} else {
type = type->expect<OptionalType>()->getElementType();
}
}
if (type->isSubtypeOf(TensorType::get())) {
AT_ASSERT(iter->isTensor());
tracer::addInputs(node, args[i].name().c_str(), iter->toTensor());
} else if (type->kind() == TypeKind::FloatType) {
AT_ASSERT(iter->isDouble());
tracer::addInputs(node, args[i].name().c_str(), iter->toDouble());
} else if (type->kind() == TypeKind::IntType) {
AT_ASSERT(iter->isInt());
tracer::addInputs(node, args[i].name().c_str(), iter->toInt());
} else if (type->kind() == TypeKind::BoolType) {
AT_ASSERT(iter->isBool());
tracer::addInputs(node, args[i].name().c_str(), iter->toBool());
} else if (type->kind() == TypeKind::StringType) {
AT_ASSERT(iter->isString());
tracer::addInputs(node, args[i].name().c_str(), iter->toStringRef());
} else if (type->kind() == TypeKind::NumberType) {
tracer::addInputs(node, args[i].name().c_str(), iter->toScalar());
} else if (type->kind() == TypeKind::ListType) {
const auto& elem_type = type->expect<ListType>()->getElementType();
if (elem_type->isSubtypeOf(TensorType::get())) {
AT_ASSERT(iter->isTensorList());
auto list = iter->toTensorVector();
tracer::addInputs(node, args[i].name().c_str(), list);
} else if (elem_type->kind() == TypeKind::FloatType) {
AT_ASSERT(iter->isDoubleList());
// NB: now, tracer doesn't support tracing double list. We add
// special handling here, since in our case, we assume that all the
// doubles in the list are constants
auto value = iter->toDoubleVector();
std::vector<Value*> info(value.size());
for (size_t value_index = 0; value_index < value.size();
++value_index) {
info[value_index] = graph->insertConstant(value[value_index]);
tracer::recordSourceLocation(info[value_index]->node());
}
node->addInput(
graph
->insertNode(graph->createList(jit::FloatType::get(), info))
->output());
} else if (elem_type->kind() == TypeKind::IntType) {
AT_ASSERT(iter->isIntList());
tracer::addInputs(
node, args[i].name().c_str(), iter->toIntVector());
} else if (elem_type->kind() == TypeKind::BoolType) {
AT_ASSERT(iter->isBoolList());
tracer::addInputs(
node, args[i].name().c_str(), iter->toBoolList().vec());
} else {
throw std::runtime_error(
"unsupported input list type: " + elem_type->str());
}
} else if (iter->isObject()) {
tracer::addInputs(node, args[i].name().c_str(), iter->toObject());
} else {
throw std::runtime_error("unsupported input type: " + type->str());
}
}
# node嵌入graph
graph->insertNode(node);
jit::tracer::setTracingState(nullptr);
}可以看到,在具体运算发生时,会使用 getTracingState() 得到 forward 开始去创建的 state,然后看到根据 op.schema().name() 得到计算类型(比如相加),根据计算类型通过 createNone 方法创建一个计算节点,然后创建计算输入,最后把计算 node insert 到 graph 中,完成一次对计算的记录。
script
因为 script 得到 IR 的方式是解析源码,因此对于不同的代码形式会略有不同(函数,class,nn.Module的instance):1 Python 函数 简化后 code
def script(obj, optimize=None, _frames_up=0, _rcb=None):
# fucntion 分支
if hasattr(obj, "__script_if_tracing_wrapper"):
obj = obj.__original_fn
_rcb = _jit_internal.createResolutionCallbackFromClosure(obj)
# 检查重载
_check_directly_compile_overloaded(obj)
# 是否之前被script过了
maybe_already_compiled_fn = _try_get_jit_cached_function(obj)
if maybe_already_compiled_fn:
return maybe_already_compiled_fn
# 得到ast语法树
ast = get_jit_def(obj, obj.__name__)
if _rcb is None:
_rcb = _jit_internal.createResolutionCallbackFromClosure(obj)
#c++ 入口,根据ast得到ir
fn = torch._C._jit_script_compile(
qualified_name, ast, _rcb, get_default_args(obj)
)
# Forward docstrings
fn.__doc__ = obj.__doc__
# cache起来
_set_jit_function_cache(obj, fn)
return fn我们看下 get_jit_def(https://github.com/pytorch/pytorch/blob/58eb23378f2a376565a66ac32c93a316c45b6131/torch/jit/frontend.py#L225) 是如何得到 jit 规定的 ast 语法树的
仅保留逻辑代码,细节删掉
def get_jit_def(fn, def_name, self_name=None):
# 得到源代码的一些信息
sourcelines, file_lineno, filename = get_source_lines_and_file(fn, torch._C.ErrorReport.call_stack())
sourcelines = normalize_source_lines(sourcelines)
source = dedent_src ''.join(sourcelines)
# dedent_src 为包含了要script函数的字符串
dedent_src = dedent(source)
# 调用python ast包将字符串解析为Python的ast
py_ast = ast.parse(dedent_src)
# 得到python类型注释
type_line = torch.jit.annotations.get_type_line(source)
#ctx中包含了函数所有原信息
ctx = SourceContext(source, filename, file_lineno, leading_whitespace_len, True)
fn_def = py_ast.body[0]
# build_def将python 的ast 转化为torchjit 使用的ast格式
return build_def(ctx, fn_def, type_line, def_name, self_name=self_name)用一个简单的例子给大家解释下 py_ast.body[0] 是什么
import ast
... func_def= \
... """def test(a):
... a = a + 2
... return a + 1"""
... results = ast.parse(func_def)Python 解析出的 AST
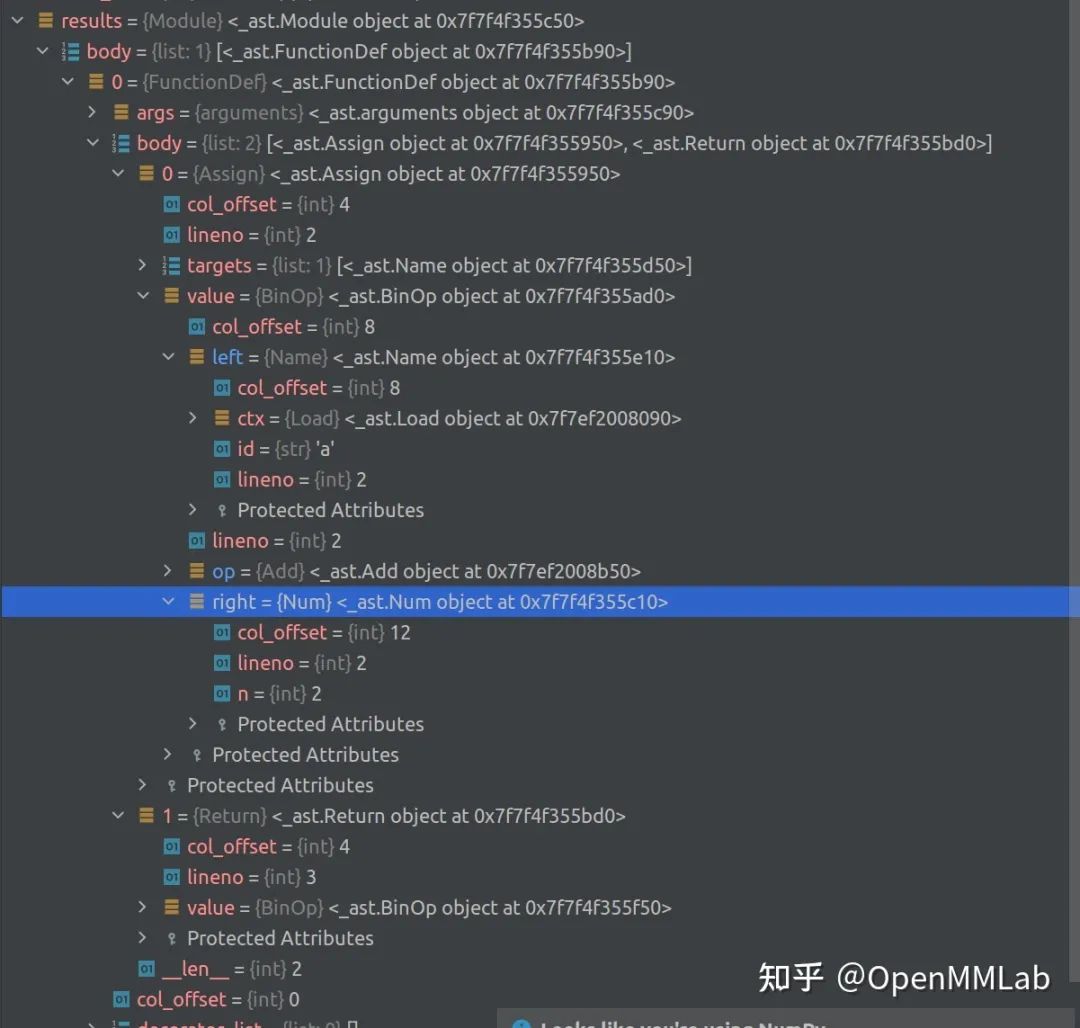
可见,ast.body 是一个 list,其长度等于解析的 string 中包含的函数的个数,我们看第一个元素,其中 value 是一个
Binop具体为一个Add,left 是Name类型,id为 `a,right是Num,也就是2,这个Binop即解析的a = a + 2。
因为我们 get_source_lines_and_file 返回的一定是一个 single top-level function, 因此我们直接取用第 0 个元素,即 py_ast.body[0] 就可以了。
接下来看build_def是如何将 Python 的 ast 转化为自己需要的 ast 的。
进入buid_def
def build_def(ctx, py_def, type_line, def_name, self_name=None):
....
return Def(Ident(r, def_name),
decl,
build_stmts(ctx, body))因为ctx 包含 source code 所有信息, body 是 Python ast 解析结果,那么build_stmts中应该包含我们想要的答案。
我们用例子中a+2为例看会怎么转换,这部分可见 frontend.py
https://github.com/pytorch/pytorch/blob/58eb23378f2a376565a66ac32c93a316c45b6131/torch/jit/frontend.py#L528
关于StmtBuilder
from torch._C._jit_tree_views import (
ClassDef, Ident, Stmt, Decl, Def, Var,
EmptyTypeAnnotation, Param, ExprStmt, Assign,
Delete, Return, Raise, Assert, AugAssign, While,
For, If, Pass, Break, Continue, Apply, Dots, Select,
TrueLiteral, FalseLiteral, NoneLiteral, Starred,
ListLiteral, TupleLiteral, DictLiteral, Const,
StringLiteral, ListComp, Attribute, BinOp, UnaryOp,
SliceExpr, Subscript, TernaryIf, With, WithItem, Property,
DictComp,
)
# jit中定义的ast基本结构
def build_stmts(ctx, stmts):
#发现其调用了`build_stmt`
stmts = [build_stmt(ctx, s) for s in stmts]
return list(filter(None, stmts))
#`build_stmt` 是一个StmtBuilder()的instance
build_stmt = StmtBuilder()
build_expr = ExprBuilder()
class Builder(object):
def __call__(self, ctx, node):
# 可见会根据解析出的ast的类型返回相应的build方法,从截图可以看到`a+2`是一个`Assign`类型
# 因此会调用build_Assign
method = getattr(self, 'build_' + node.__class__.__name__, None)
if method is None:
raise UnsupportedNodeError(ctx, node)
return method(ctx, node)
class StmtBuilder(Builder):
@staticmethod
def build_Assign(ctx, stmt):
# 截图可以看到stmt.value是一个Binop
# build_expr是ExprBuilder的INSTANCE,其会调用`build_BinOp`
rhs = build_expr(ctx, stmt.value)
lhs = [build_expr(ctx, x) for x in stmt.targets]
return Assign(lhs, rhs)
@staticmethod
def build_Expr(ctx, stmt):
# Binop
value = stmt.value
if value.__class__.__name__ == 'Str':
# If a statement is a string literal expression,
# then it is a docstring. Just ignore it.
return None
else:
return ExprStmt(build_expr(ctx, value))
class ExprBuilder(Builder):
binop_map = {
ast.Add: '+',
ast.Sub: '-',
ast.Mult: '*',
ast.Div: '/',
ast.Pow: '**',
ast.Mod: '%',
ast.FloorDiv: '//',
ast.BitAnd: '&',
ast.BitXor: '^',
ast.BitOr: '|',
ast.LShift: '<<',
ast.RShift: '>>',
}
@staticmethod
def build_BinOp(ctx, expr):
#expr.left是个`Name`调用build_Name
lhs = build_expr(ctx, expr.left)
rhs = build_expr(ctx, expr.right)
op = type(expr.op)
# 转化为约定的代表运算类型的string 符号
op_token = ExprBuilder.binop_map.get(op)
return BinOp(op_token, lhs, rhs)最终转化为的格式,类似于 S-expression.(https://en.wikipedia.org/wiki/S-expression)
(def
(ident test)
(decl
(list
(param
(ident a)
(option)
(option)
(False)))
(option))
(list
(assign
(list (variable (ident a)))
(option
(+
(variable (ident a))
(const 2)))
(option))
(return
(+
(variable (ident a))
(const 1)))))好的,我们已经得到得到jit约定的 AST 树了,接下来我们要进入 torch._C._jit_script_compile查看如何将这样的 ast 树转化为 IR.
C++ 入口为 script_compile_function
static StrongFunctionPtr script_compile_function(
const c10::QualifiedName& name,
const Def& def,
const FunctionDefaults& defaults,
const ResolutionCallback& rcb) {
# def 中包含ast,跟着它就能找到答案
auto cu = get_python_cu();
#看来是get_python_cu这个类中的define函数完成的
auto defined_functions = cu->define(
QualifiedName(name.prefix()),
/*properties=*/{},
/*propResolvers=*/{},
{def},
{pythonResolver(rcb)},
nullptr,
true);
TORCH_INTERNAL_ASSERT(defined_functions.size() == 1);
auto& defined = defined_functions[0];
defined->setSchema(getSchemaWithNameAndDefaults(
def.range(), defined->getSchema(), def.name().name(), defaults));
StrongFunctionPtr ret(std::move(cu), defined);
didFinishEmitFunction(ret);
return ret;
}
# 发现只是wapper了下CompilationUnit
inline std::shared_ptr<CompilationUnit> get_python_cu() {
return py::module::import("torch.jit._state")
.attr("_python_cu")
.cast<std::shared_ptr<CompilationUnit>>();
}
#关于compilation_unit
#/torch/csrc/jit/api/compilation_unit.h
// for historic reasons, these are defined in ir_emitter.cpp
// Returns the list of Functions just defined.
std::vector<Function*> define(
const c10::optional<c10::QualifiedName>& prefix,
const std::vector<Property>& properties,
const std::vector<ResolverPtr>& propResolvers,
const std::vector<Def>& definitions,
const std::vector<ResolverPtr>&
defResolvers, /* determines how we handle free
variables in each definition*/
// if non-null, the first argument to each def, is bound to this value
const Self* self,
// see [name mangling]
bool shouldMangle = false);
#实现在torch/csrc/jit/frontend/ir_emitter.cpp
std::unique_ptr<Function> CompilationUnit::define(
const c10::optional<QualifiedName>& prefix,
const Def& def,
const ResolverPtr& resolver,
const Self* self,
const std::unordered_map<std::string, Function*>& function_table,
bool shouldMangle) const {
auto _resolver = resolver;
.....
auto creator = [def, _resolver, self](Function& method) {
....
##核心代码to_ir
to_ir(def, _resolver, self, method);
};
auto fn = torch::make_unique<GraphFunction>(
std::move(name), std::make_shared<Graph>(), creator);
return fn;
}我们跟随 def,找到了一个转化为 IR 的关键的struct to_ir ,其输入中有 def,也就是 ast,_resolver 是 Python 中传过来的解析名字的函数,我们可以在内部找到关键部分
to_ir(
const Def& def,
ResolverPtr resolver_,
const Self* self,
Function& method) // method being constructed
: method(method),
graph(method.graph()),
resolver(std::move(resolver_)),
typeParser_(resolver),
environment_stack(nullptr) {
AT_ASSERT(resolver);
pushFrame(graph->block(), /*starts_def=*/true);
#emitDef 中会调用emitStatements
method.setSchema(emitDef(def, self, graph->block()));
ConvertToSSA(graph);
CanonicalizeModifiedLoops(graph);
NormalizeOps(graph);
runCleanupPasses(graph);
}
private:
#在to_ir 的private中我们可以看到Graph Function这些我们之前介绍的IR的组成部分
Function& method;
std::shared_ptr<Graph> graph;
ResolverPtr resolver;
std::unordered_map<int64_t, Value*> integral_constants;
#emitDef 中会调用emitStatements
FunctionSchema emitDef(const Def& def, const Self* self, Block* block) {
......
// body
auto stmts_list = def.statements();
emitStatements(stmts_list.begin(), stmts_list.end());
........
}
void emitStatements(
List<Stmt>::const_iterator begin,
List<Stmt>::const_iterator end) {
for (; begin != end; ++begin) {
auto stmt = *begin;
ErrorReport::CallStack::update_pending_range(stmt.range());
switch (stmt.kind()) {
case TK_IF:
emitIf(If(stmt));
break;
case TK_WHILE:
emitWhile(While(stmt));
break;
case TK_FOR:
emitFor(For(stmt));
break;
case TK_ASSIGN:
emitAssignment(Assign(stmt));
.................
break;
default:
throw ErrorReport(stmt)
<< "Unrecognized statement kind " << kindToString(stmt.kind());
}
// Found an exit statement in this block. The remaining statements aren't
// reachable so we don't emit them.
if (exit_blocks.count(environment_stack->block()))
return;
}
}
我们可以看到根据stmt.kind(),会进入而各种emit里面,其中一定可以找到
graph->insertNode(graph->create(.....));
类似的操作,对应我们建立IR graph以上是我们以一个 function 为例子,接下来我们以 script 一个 module 为例,其有一些独有的挑战,因为有一些变量的指代,是需要初始化后才知道的,同时,我们希望 script 完的 module 对外还能保持一样的接口,即可以正常访问原有 module 的属性,那么应该怎么做呢?
在 module 原有的 init 结束后随即开始完整的 script forward 函数,替换涉及到的所有函数为 script 后的函数
如何正常访问原有的属性
如何在一个类的 init 函数后面绑定行为呢,我们想到 metaclass,torch.jit 实现了 ScriptMeta这个 metaclass。
class MyModule(torch.jit.ScriptModule):
@torch.jit.script_method
def f(self.x):
return x * x
@torch.jit.script_method
def forward(self, x):
return x + self.f(x)
关于script_method
def script_method(fn):
_rcb = _jit_internal.createResolutionCallbackFromFrame(frames_up=2)
ast = get_jit_def(fn, fn.__name__, self_name="ScriptModule")
#暂时没有script,只是返回包含ast的nametuple
return ScriptMethodStub(_rcb, ast, fn)
ScriptMethodStub = collections.namedtuple('ScriptMethodStub', ('resolution_callback', 'def_', 'original_method'))
1 移除所有script_method属性被(@script_method修饰的方法),确保访问到的是script function
2 修改module的_init_,确保module的self.param或者self.module初始化后立即编译所有的script_method,
从而生成的instance的forward已经被替换
class ScriptMeta(type):
def __init__(cls, name, bases, attrs): # noqa: B902
# cls ScriptMeta的instance,是一个类如ScriptModule
cls._methods: Dict[str, Any] = {}
cls._constants_set = set(getattr(cls, "__constants__", ()))
for base in reversed(bases):
# 还记得吗trace的module也是有一个_methods的属性
for k, v in getattr(base, "_methods", {}).items():
cls._methods[k] = v
base_constants = getattr(base, "_constants_set", set())
cls._constants_set = cls._constants_set.union(base_constants)
# 找到现在所有被@script_method修饰的方法,放到_method,并删除原有attr
# init后之后统一script
for k, v in sorted(attrs.items()):
if isinstance(v, ScriptMethodStub):
delattr(cls, k)
cls._methods[v.original_method.__name__] = v
original_init = getattr(cls, "__init__", lambda self: None)
# 此处实现了init结束后,调用create_script_module进行script
@functools.wraps(original_init)
def init_then_script(self, *args, **kwargs):
# 此处的self为instance
num_methods = len(cls._methods)
original_init(self, *args, **kwargs)
added_methods_in_init = len(cls._methods) > num_methods
if type(self) == cls:
# 选取需要script的method
def make_stubs(module):
cls = type(module)
if hasattr(cls, "_methods"):
return [v for k, v in sorted(cls._methods.items())]
else:
# infer_methods_to_compile 是一个选取要script函数的函数
return infer_methods_to_compile(module)
# 讲所有script_method一块编译为_actual_script_module属性
self.__dict__[
"_actual_script_module"
] = torch.jit._recursive.create_script_module(self, make_stubs, share_types=not added_methods_in_init)
# Delete the Python attributes that now shadow the ScriptModule
# ones, so that __getattr__ and __setattr__ will properly find
# the scripted versions.
concrete_type = self._actual_script_module._concrete_type
for name in concrete_type.get_attributes():
delattr(self, name)
for name, _ in concrete_type.get_modules():
delattr(self, name)
for name in ("_parameters", "_buffers", "_modules"):
delattr(self, name)
cls.__init__ = init_then_script # type: ignore
return super(ScriptMeta, cls).__init__(name, bases, attrs)
class _CachedForward(object):
def __get__(self, obj, cls):
return self.__getattr__("forward") # type: ignore
class ScriptModule(with_metaclass(ScriptMeta, Module)): # type: ignore
def __init__(self):
super(ScriptModule, self).__init__()
forward = _CachedForward()
# 想访问module的attr,返回_actual_script_module的attr
def __getattr__(self, attr):
if "_actual_script_module" not in self.__dict__:
return super(ScriptModule, self).__getattr__(attr)
return getattr(self._actual_script_module, attr)
def __setattr__(self, attr, value):
if "_actual_script_module" not in self.__dict__:
# Unwrap torch.jit.Attribute into a regular setattr + recording
# the provided type in __annotations__.
#
# This ensures that if we use the attr again in `__init__`, it
# will look like the actual value, not an instance of Attribute.
if isinstance(value, Attribute):
if "__annotations__" not in self.__class__.__dict__:
self.__class__.__annotations__ = {}
self.__annotations__[attr] = value.type
value = value.value
return super(ScriptModule, self).__setattr__(attr, value)
setattr(self._actual_script_module, attr, value)
...关于 create_script_module 函数会 script method 然后返回一个 RecursiveScriptModule,但是其逻辑较为复杂,在此不再展开。
关于 vs
当访问某个实例属性时,getattribute 会被无条件调用,当这个属性不存在,则会调用 getattr,如未实现自己的 getattr 方法,会抛出 AttributeError 提示找不到这个属性,如果自定义了自己 getattr 方法的话方法会在这种找不到属性的情况下被调用。
4 IR优化的简单介绍
jit 一般涉及如下优化: loop unrolling peephole optimization constant propagation DCE fusion inlining... 我们看如下例子:
def test(x):
# Dead code Elimination
for i in range(1000):
y = x + 1
for i in range(100):
#peephole optimization
x = x.t()
x = x.t()
return x.sum()
opt_test = torch.jit.script(test)
s = time()
inputs = torch.ones(4,4).cuda()
s = time()
for i in range(10000):
test(inputs)
print(time()-s)
# 95s
s = time()
for i in range(10000):
opt_test(inputs)
print(time()-s)
# 0.13s
print(opt_test.graph)
print(opt_test.graph_for(inputs))
95.13823795318604
0.13010907173156738
graph(%x.1 : Tensor):
%22 : None = prim::Constant()
%13 : bool = prim::Constant[value=1]() # /home/SENSETIME/zhangshilong/PycharmProjects/pythonProject/opt.py:10:4
%10 : int = prim::Constant[value=100]() # /home/SENSETIME/zhangshilong/PycharmProjects/pythonProject/opt.py:10:19
%x : Tensor = prim::Loop(%10, %13, %x.1) # /home/SENSETIME/zhangshilong/PycharmProjects/pythonProject/opt.py:10:4
block0(%i : int, %x.10 : Tensor):
%x.4 : Tensor = aten::t(%x.10) # /home/SENSETIME/zhangshilong/PycharmProjects/pythonProject/opt.py:11:12
%x.7 : Tensor = aten::t(%x.4) # /home/SENSETIME/zhangshilong/PycharmProjects/pythonProject/opt.py:12:12
-> (%13, %x.7)
%23 : Tensor = aten::sum(%x, %22) # /home/SENSETIME/zhangshilong/PycharmProjects/pythonProject/opt.py:13:11
return (%23)
graph(%x.1 : Tensor):
%1 : None = prim::Constant()
%2 : Tensor = aten::sum(%x.1, %1) # /home/SENSETIME/zhangshilong/PycharmProjects/pythonProject/opt.py:13:11
return (%2)关于 IR 计算图优化
IR 的 Method 中内置 GraphExecutor object,创建于第一次执行的时候,负责优化。文件 pytorch-master/torch/csrc/jit/api/method.h scritp_method 的 C++ 原型里
GraphExecutor& get_executor() {
return function_->get_executor();
}GraphExecutor 的定义在/torch/csrc/jit/runtime/graph_executor.cpp,可见其由 graph 产生,定义了 run 方法执行
GraphExecutor::GraphExecutor(
const std::shared_ptr<Graph>& graph,
std::string function_name)
: pImpl(
IsNewExecutorEnabled()
? dynamic_cast<GraphExecutorImplBase*>(
new ProfilingGraphExecutorImpl(
graph,
std::move(function_name)))
: dynamic_cast<GraphExecutorImplBase*>(
new GraphExecutorImpl(graph, std::move(function_name)))) {}
std::shared_ptr<Graph> GraphExecutor::graph() const {
return pImpl->graph;
}
const ExecutionPlan& GraphExecutor::getPlanFor(
Stack& inputs,
size_t remaining_bailout_depth) {
return pImpl->getPlanFor(inputs, remaining_bailout_depth);
}
std::shared_ptr<GraphExecutorImplBase> pImpl;
.....
关于GraphExecutorImplBase,/torch/csrc/jit/runtime/graph_executor.cpp
const ExecutionPlan& getOrCompile(const Stack& stack) {
.....
auto plan = compileSpec(spec);
}
}
# compileSpec 会返回一个plan
ExecutionPlan compileSpec(const ArgumentSpec& spec) {
auto opt_graph = graph->copy();
GRAPH_DUMP("Optimizing the following function:", opt_graph);
arg_spec_creator_.specializeTypes(*opt_graph, spec);
// Phase 0. Inline functions, then clean up any artifacts that the inliner
// left in that may inhibit optimization
.....
runRequiredPasses(opt_graph);
GRAPH_DEBUG(
"After runRequiredPasses, before ConstantPropagation\n", *opt_graph);
// Phase 2. Propagate detailed information about the spec through the
// graph (enabled more specializations in later passes).
// Shape propagation sometimes depends on certain arguments being
// constants, and constant propagation doesn't need shape
// information anyway, so it's better to run it first.
ConstantPropagation(opt_graph);
GRAPH_DEBUG(
"After ConstantPropagation, before PropagateInputShapes\n", *opt_graph);
PropagateInputShapes(opt_graph);
GRAPH_DEBUG(
"After PropagateInputShapes, before PropagateRequiresGrad\n",
*opt_graph);
PropagateRequiresGrad(opt_graph);
GRAPH_DEBUG(
"After PropagateRequiresGrad, before runOptimization\n", *opt_graph);
// Phase 3. Run differentiable optimizations (i.e. simple graph rewrites
// that we can still execute using autograd).
runOptimization(opt_graph);
.....各种优化
return ExecutionPlan(opt_graph, function_name_);
}这些优化在 torch/csrc/jit/passes/ 文件夹 torch/csrc/jit/passes/dead_code_elimination.cpp /torch/csrc/jit/passes/fuse_linear.cpp torch/csrc/jit/passes/remove_dropout.cpp torch/csrc/jit/passes/fold_conv_bn.cpp
1. INTRODUCTION TO TORCHSCRIPT(https://pytorch.org/tutorials/beginner/Intro_to_TorchScript_tutorial.html)
2. PyTorch 部署_TorchScript(https://zhuanlan.zhihu.com/p/135911580)
3. pytorch_wiki(https://github.com/pytorch/pytorch/wiki)
4. PyTorch-JIT-Source-Code-Read-Note(https://zasdfgbnm.github.io/2018/09/20/PyTorch-JIT-Source-Code-Read-Note/)
5. Abstract_syntax_tree(https://en.wikipedia.org/wiki/Abstract_syntax_tree)
:因本人卑微的算法调参侠一枚,对于部署了解不深。如有纰漏,望评论区不吝指正。
本文仅做学术分享,如有侵权,请联系删文。
后台回复:即可下载国外大学沉淀数年3D Vison精品课件
后台回复:即可下载3D视觉领域经典书籍pdf
后台回复:即可学习3D视觉领域精品课程
1.面向自动驾驶领域的多传感器数据融合技术
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进4.国内首个面向工业级实战的点云处理课程5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
9.从零搭建一套结构光3D重建系统[理论+源码+实践]
10.单目深度估计方法:算法梳理与代码实现
11.自动驾驶中的深度学习模型部署实战
12.相机模型与标定(单目+双目+鱼眼)
13.重磅!四旋翼飞行器:算法与实战
14.ROS2从入门到精通:理论与实战
15.国内首个3D缺陷检测教程:理论、源码与实战
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在
也可申请加入我们的细分方向交流群,目前主要有、、、、、等微信群,请扫描下面微信号加群,备注:”研究方向+学校/公司+昵称“,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进去相关微信群。也请联系。
▲长按加微信群或投稿
▲长按关注公众号
:针对3D视觉领域的五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款
圈里有高质量教程资料、可答疑解惑、助你高效解决问题