无监督异常检测和诊断的深层神经网络
摘要
如今,越来越多的多变量时间序列数据被收集到电厂、可穿戴设备等各种现实世界系统中。多变量时间序列中的异常检测和诊断是指在特定时间步骤中识别异常状态并找出其根本原因。然而,建立这样一个系统是具有挑战性的,因为它不仅需要捕获每个时间序列中的时间依赖性,还需要编码不同时间序列之间的相互关联。此外,该系统应对噪声,并根据不同事件的严重程度为操作员提供不同级别的异常评分。尽管开发了许多无监督异常检测算法,但很少有算法能够共同应对这些挑战。本文提出了多尺度卷积循环编码器解码器(MSCRED),异常检测和诊断用于多变量时间序列数据。具体而言,MSCRED首先,构建多尺度(分辨率)特征矩阵,以表示不同时间步中的多个系统状态水平。然后,在给定特征矩阵的情况下,使用卷积编码器编码传感器间(时间序列)的相关性,并开发基于注意的卷积长度记忆(CONVLSM)网络捕获时间模式。最后,基于编码传感器之间的相关性和时间信息的特征映射,采用卷积解码器重建输入特征矩阵,进一步利用剩余特征矩阵进行异常检测和诊断。大量基于合成数据集和真实电厂数据集的实证研究表明,MSCRED性能优于最先进的基线方法。
介绍
复杂的系统在现代制造业和信息服务业无处不在。监控这些系统的行为会产生大量的多变量时间序列数据,如发电厂的网络传感器(如温度和压力)读数,或信息技术(IT)系统中的连接组件(如CPU使用和磁盘I/O)。 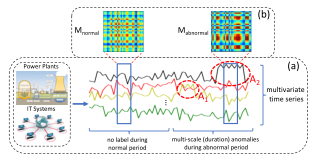 图1:(a)无监督异常检测和诊断的多变量时间序列数据。(b) 系统特征矩阵不同于正常周期和异常周期。 管理这些系统的关键任务之一是检测特定时间内的异常情况,以便操作员能够采取进一步措施解决潜在问题。例如,异常评分可以根据传感器数据生成,并作为电厂故障的指标(Len、Vittal和Manimaran 2007)。准确的检测对避免严重的财务和商业损失至关重要,因为据报道,汽车制造商可能每分钟停工2万美元(Djurdjanovic、Lee和Ni 2003)。此外,查明根本原因,即确定哪些传感器(系统部件)是导致异常的原因,可以帮助系统操作员及时进行系统诊断和维修。在实际应用中,由于现代系统的自动恢复能力和鲁棒性,由时间湍流或系统状态切换引起的短期异常最终可能不会导致真正的系统故障,这是很常见的。因此,如果异常检测算法能够根据各种事件的严重程度为操作提供不同层次的异常分数,这将是理想的。简单地说,我们假设事件的严重性与工作中的异常持续时间成正比。图1(a)在多变量时间序列数据中显示两个异常,即A1和A2.用红色虚线圈标记。根本原因是黄黑时间序列。A2的持续时间(严重程度)大于A1。 为了建立一个能够自动检测和诊断异常的系统,一个主要问题是历史数据中很少甚至没有异常标签,这使得监督算法(G?rnitz et al.2013)不可行。在过去的几年里,开发了大量的无监督异常检测方法。最突出的技术包括距离/聚类法(He、Xu和Deng 2003;Hautama–ki、Ka–rkka–?nen和Fra–nti 2004;Idé、Papadimitriou和Vlachos 2007;Campello等人2015)(Chandola、Banerjee和Kumar 2009);密度估计方法(Manevitz和Y ousef 2001)时间预测方法(Chen等人,2008年;Günnemann、Günnemann和Faloutsos,2014年),以及最新的深度学习技术(Malhotra等人,2016年;Qin等人,2017年;Zhou和Paffenroth,2017年;Wu等人,2018年;Zong等人,2018年)。尽管采用了内部无监督设置,但由于以下原因,大多数设备仍无法有效检测异常: ?多元时间序列数据存在时间依赖性。因此,距离/聚类法,如k-最近邻(kNN)(Hautama–ki、Ka–rkka–?nen和Fra–nti 2004),分类方法,如一类支持向量机(Manevitz和Y-Usef 2001)和密度估计方法,如深度自编码高斯混合模型(DAGMM)(Zong等人,2018),可能无法很好地执行,因为它们无法捕获跨不同时间步的时间依赖关系。 ?在实词应用中,多变量时间序列数据通常包含噪声。当噪声变得相对严重时,可能会影响自回归平均滑动等时间预测模型的泛化能力(ARMA)(Hamilton 1994)和LSTM编码器(Malhotra et al.2016;Qin et al.2017)并增加假阳性检测。 ?在实际应用中,根据不同事件的严重程度,为操作员提供不同级别的异常分数是有意义的。如果排名异常,现有的根本原因分析方法(RCA)(Cheng等人,2016),对噪音敏感,无法处理。
图1:(a)无监督异常检测和诊断的多变量时间序列数据。(b) 系统特征矩阵不同于正常周期和异常周期。 管理这些系统的关键任务之一是检测特定时间内的异常情况,以便操作员能够采取进一步措施解决潜在问题。例如,异常评分可以根据传感器数据生成,并作为电厂故障的指标(Len、Vittal和Manimaran 2007)。准确的检测对避免严重的财务和商业损失至关重要,因为据报道,汽车制造商可能每分钟停工2万美元(Djurdjanovic、Lee和Ni 2003)。此外,查明根本原因,即确定哪些传感器(系统部件)是导致异常的原因,可以帮助系统操作员及时进行系统诊断和维修。在实际应用中,由于现代系统的自动恢复能力和鲁棒性,由时间湍流或系统状态切换引起的短期异常最终可能不会导致真正的系统故障,这是很常见的。因此,如果异常检测算法能够根据各种事件的严重程度为操作提供不同层次的异常分数,这将是理想的。简单地说,我们假设事件的严重性与工作中的异常持续时间成正比。图1(a)在多变量时间序列数据中显示两个异常,即A1和A2.用红色虚线圈标记。根本原因是黄黑时间序列。A2的持续时间(严重程度)大于A1。 为了建立一个能够自动检测和诊断异常的系统,一个主要问题是历史数据中很少甚至没有异常标签,这使得监督算法(G?rnitz et al.2013)不可行。在过去的几年里,开发了大量的无监督异常检测方法。最突出的技术包括距离/聚类法(He、Xu和Deng 2003;Hautama–ki、Ka–rkka–?nen和Fra–nti 2004;Idé、Papadimitriou和Vlachos 2007;Campello等人2015)(Chandola、Banerjee和Kumar 2009);密度估计方法(Manevitz和Y ousef 2001)时间预测方法(Chen等人,2008年;Günnemann、Günnemann和Faloutsos,2014年),以及最新的深度学习技术(Malhotra等人,2016年;Qin等人,2017年;Zhou和Paffenroth,2017年;Wu等人,2018年;Zong等人,2018年)。尽管采用了内部无监督设置,但由于以下原因,大多数设备仍无法有效检测异常: ?多元时间序列数据存在时间依赖性。因此,距离/聚类法,如k-最近邻(kNN)(Hautama–ki、Ka–rkka–?nen和Fra–nti 2004),分类方法,如一类支持向量机(Manevitz和Y-Usef 2001)和密度估计方法,如深度自编码高斯混合模型(DAGMM)(Zong等人,2018),可能无法很好地执行,因为它们无法捕获跨不同时间步的时间依赖关系。 ?在实词应用中,多变量时间序列数据通常包含噪声。当噪声变得相对严重时,可能会影响自回归平均滑动等时间预测模型的泛化能力(ARMA)(Hamilton 1994)和LSTM编码器(Malhotra et al.2016;Qin et al.2017)并增加假阳性检测。 ?在实际应用中,根据不同事件的严重程度,为操作员提供不同级别的异常分数是有意义的。如果排名异常,现有的根本原因分析方法(RCA)(Cheng等人,2016),对噪音敏感,无法处理。
本文提出了一种多尺度卷积递归编码器解码器(MSCRD)考虑上述问题。具体地说,MSCRED首先构建多尺度(分辨率)特征矩阵,描述跨越不同时间步的多层次系统状态。特别是,不同级别的系统状态用于指示不同异常事件的严重程度。然后,在给定特征矩阵的情况下,用卷积编码器编码传感器间(时间序列)的相关模式,并开发基于注意的卷积长度记忆(CONVLSM)网络捕获时间模式。最后,利用编码传感器之间的相关性和时间信息映射,利用卷积解码器重建特征矩阵,进一步利用剩余特征矩阵进行异常检测和诊断。如果,直觉是MSCRED以前从未观察过类似的系统状态,它可能无法很好地重征矩阵。例如,图1(b)在正常和异常期间显示两个特征矩阵Mnormal和Mabnormal。理想情况下,MSCRED不能重建Mabnormal,因为训练矩阵(例如Mnormal)不同于Mabnormal。总之,我们工作的主要贡献是: ?我们将异常检测和诊断问题描述为三个基本任务,即异常检测、根本原因识别和异常严重程度(持续时间)的解释。与以往对每个问题的独立研究不同,我们共同解决了这些问题。 ?我们了系统特征码矩阵的概念,开发了MSCRED,传感器之间的相关性是通过卷积编码器编码的,基于注意的时间模式和CONVLTM网络结合,特征码矩阵通过卷积解码器重建。据我们所知,MSCRED它是第一个考虑多变时间序列之间相关性的异常检测模型,可以共同解决这三个任务。 ?对合成数据集和发电厂数据集进行了广泛的实证研究。结果表明,MSCRED的性能优于最先进的基线方法。
相关工作
多变时间序列数据的无监督异常检测是一项具有挑战性的任务,在过去几年中发展了各种方法。 传统的距离法是距离法(Hautama–ki、Ka–rkka–?nen和Fra–nti 2004;Idé、Papadimitriou和Vlachos 2007)。例如,k近邻(kNN)算法(Hautama¨ki、Ka¨rkka¨?nen和Fra¨nti 2004)每个数据样本的异常分数邻的平均距离计算的。类似地,聚类模型(He、Xu和Deng 2003;Campello et al.2015)聚类不同的数据样本,通过预定义的异常值得分发现异常。此外,单类支持向量机等分类方法(Manevitz和Y ousef 2001)建模训练数据的密度分布,将新数据分类为正常或异常。虽然这些方法已经在各种应用中证明了它们的有效性,但它们可能无法在多变量时间序列上很好地工作,因为它们无法恰当地捕捉时间依赖关系。为了解决这个问题,时间预测方法,如自回归平均移动(ARMA)(Hamilton 1994)及其变体(Brockwell和Davis 2013)已用于建模时间相关性和异常检测。然而,这些模型对噪声非常敏感,因此当噪声严重时,假阳性结果可能会增加。其他传统方法包括相关方法(Kriegel et al.2012年集成方法(Lazarevic和Kumar 2005)等。 除传统方法外,基于深度学习的无监督异常检测算法(Malhotra等等,2016;翟等,2016;Zhou and Paffenroth 2017;Zong等等,2018)最近也引起了广泛关注。例如,Deep Autoencoding Gaussian Mixed Model(DAGMM)(Zong et al.2018年)联合考虑Deep Autoencoding和Gaussian Mixed Model建模多维数据的密度分布。LSTM编码器-解码器(Malhotra et al.2016;Qin et al.2017)通过LSTM网络建模了时间序列的时间依赖性,实现了比传统方法更好的泛化能力。尽管它们的有效性,但它们不能共同考虑时间依赖性、抗噪声解释异常的严重性。 此外,我们的模型设计受到完全卷积神经网络(Long、Shelhamer和Darrell 2015)、卷积LSTM网络(Shi2015年等人(Bahdanaau、Cho和Bengio 2014;Y ang2016年等人启发。本文还涉及其他时间序列应用,如聚类/分类(Li and Prakash 2011;Hallac et al.2017;Karim et al.2018)、分段(Keogh et al.2001;Lemire 2007)等。
MSCRED框架
在这一部分中,我们首先介绍了我们需要研究的问题,然后详细介绍了多尺度卷积循环编码器-解码器(MSCRED)。具体来说,我们首先展示了如何生成多尺度(分辨率)系统签名矩阵。然后,我们将空间信息编码到签名矩阵,并基于注意CONVLSM建模时间信息。最后,我们重建了基于卷积解码器的签名矩阵,并利用平方损失进行端到端学习。
问题陈述
给定长度为T的n时间序列的历史数据,即X=(x1,··,xn)T∈ Rn×T,假设数据中没有异常,我们的目标是实现两个目标: ?异常检测,即T后特定时间步检测异常事件。 ?异常诊断,即根据检测结果,确定有可能导致每个异常的时间序列,并定性解释异常的严重程度(持续时间尺度)。
h5> 用特征矩阵刻画状态之前的研究(Hallac et al.2017;Song et al.2018)表明,不同时间序列对之间的相关性对于描述系统状态至关重要。表示多元时间序列段中不同时间序列对之间的相互关系− 从w到t,我们基于这段时间内两个时间序列的成对内积构造了一个n×n签名矩阵mt。签名矩阵的两个示例如图1(b)所示。具体来说,给定两个时间序列xwi=(xt−w i,xt−W−1 i,··,xti)和xwj=(xt)−w j,xt−W−1 j,··,xtj)在多变量时间序列段Xw中,它们的相关性mtij∈ M t的计算公式为: 其中,κ是一个重缩放因子(κ=w)。特征矩阵即mt,不仅可以捕捉两个时间序列之间的形状相似性和值尺度相关性,而且由于特定时间序列的湍流对特征矩阵的影响很小,因此对输入噪声具有鲁棒性。在这项工作中,两段之间的间隔设置为10。此外,为了在不同尺度下表征系统状态,我们在每个时间步构造了不同长度(w=10,30,60)的s(s=3)特征矩阵。
卷积编码器
我们使用完全卷积编码器(Long、Shelhamer和Darrell 2015)对系统签名矩阵的空间模式进行编码。具体来说,我们在不同的尺度上把mt连接成张量xt,0∈ Rn×n×s,然后将其馈送到多个卷积层。假设X t,l−1.∈ Rnl−1×nl−1×dl−1表示(l)中的特征映射− 1) -th层,第l层的输出由下式给出: 哪里∗ 表示卷积运算,f(·)表示激活函数,WL∈ Rkl×kl×dl−1×dl表示大小为kl×kl×dl的dl卷积核−1,基本法∈ Rdl是一个偏差项,X t,l∈ Rnl×nl×dl表示第l层的输出特征图。在这项工作中,我们使用缩放指数线性单元(SELU)(Klambauer et al.2017)作为激活函数和4个卷积层,即具有32个大小为3×3×3的核的Conv1-Conv4、64个大小为3×3×32的核、128个大小为2×2×64的核和256个大小为2×2×128的核,以及1×1、2×2、2×2和2×2的步长,分别地请注意,形成签名矩阵所基于的时间序列的确切顺序并不重要,因为对于任何给定的排列,产生的局部模式都可以由卷积编码器捕获。图2(a)说明了签名矩阵的详细编码过程。
基于注意力的ConvLSTM
卷积编码器生成的空间特征图在时间上依赖于之前的时间步长。尽管ConvlTM(Shi等人,2015)已被开发用于捕获视频序列中的时间信息,但其性能可能会随着序列长度的增加而恶化。为了解决这个问题,我们开发了一个基于注意的ConvLSTM,它可以在不同的时间步长上自适应地选择相关的隐藏状态(特征映射)。具体来说,给定来自第l卷积层和先前隐藏状态Ht的特征映射X t、l−1,l∈ Rnl×nl×dl,当前隐藏状态Ht,l用Ht更新,l=ConvLSTM(X t,l,Ht−1,l),其中ConvLSTM单元(Shi等人,2015)的公式如下: 哪里∗ 表示卷积算子,◦ 代表哈达玛积,σ是S形函数, 是第l层CONVLSM的偏置参数。 图2:拟议模型的框架:(a)通过完全卷积神经网络编码的特征矩阵。(b) 通过基于注意的卷积LSTM网络进行时间模式建模。(c) 通过反褶积神经网络解码特征矩阵。(d) 损失函数。
在我们的工作中,我们在每一层保持与卷积编码器相同的卷积内核大小。请注意,所有输入X t,l,单元输出Ct,l,隐藏状态Ht−1,l和门zt,l,rt,l,ot,l是3D张量,这与LSTM不同。我们调整步长h(即之前分段的数量),并将其设置为5,因为它具有最佳的经验性能。此外,考虑到并非所有之前的步骤都与当前状态Ht,l同等相关,我们采用时间注意机制自适应地选择与当前步骤相关的步骤,并聚合这些信息性特征图的表示,以形成特征图ˆHt,l的精化输出,其由下式给出: 式中,V ec(·)表示向量,χ表示重缩放因子(χ=5.0)。也就是说,我们将最后一个隐藏状态Ht,l作为组级上下文向量,并通过softmax函数测量前面步骤的重要性权重αi。与引入转换和上下文参数的一般注意机制(Bahdanau、Cho和Bengio 2014)不同,上述公式纯粹基于学习到的隐藏特征映射,实现了与前者类似的功能。本质上,基于注意的ConvLSTM利用每个卷积层的时间信息联合建模特征矩阵的空间模式。图2(b)说明了时间建模过程 。
卷积解码器
为了解码前一步获得的特征映射并获得重构的特征矩阵,我们设计了一个卷积解码器,其公式如下: 其中~表示反褶积操作,⊕ 是串联操作,f(·)是激活单元(与编码器相同),ˆW l∈ Rˆkl׈kl׈dl׈dl−1和ˆbl∈ Rˆdl是第l反褶积层的滤波核和偏移参数。具体地说,我们遵循相反的顺序,将第l个ConvLSTM层的ˆHt,l馈送到反褶积神经网络。输出特征映射ˆX t,l−1.∈ Rˆnl−1×nl−1׈dl−1与前一个ConvLSTM层的输出串联,使解码器进程堆叠起来。连接的表示被进一步送入下一个反褶积层。最终输出ˆX t,0∈ Rn×n×s(输入矩阵的大小相同)表示重构签名矩阵的表示。因此,我们使用了4个反褶积层:DeConv4-DeConv1,128个大小为2×2×256的核,64个大小为2×2×128的核,32个大小为3×3×64的核,以及3个大小为3×3×64的核,以及分别为2×2、2×2、2×2和1×1的步长。解码器能够在不同的反卷积层和ConvLSTM层合并特征映射,这对于提高异常检测性能是有效的,我们将在实验中演示。图2(c)说明了解码过程。
损失函数
对于MSCRED,目标定义为特征矩阵上的重建误差,即:。, 其中X t,0:,:,c∈ Rn×n。我们采用小批量随机梯度下降法和Adam优化器(Kingma和Ba 2014)来最小化上述损失。经过足够多的训练周期后,利用学习到的神经网络参数推断验证和测试数据的重构特征矩阵。最后,我们基于残差特征矩阵进行异常检测和诊断,这将在下一节详细介绍。
实验
在本节中,我们进行了大量实验,以回答以下研究问题: •异常检测。MSCRED在多变量时间序列(RQ1)异常检测方面是否优于基线方法?MSCRED的每个组件如何影响其性能(RQ2)? •异常诊断。MSCRED能否有效地进行根本原因识别(RQ3)和异常严重程度(持续时间)解释(RQ4)? •对噪音的鲁棒性。与基线方法相比,MSCRED是否对输入噪声更具鲁棒性(RQ5)?
实验装置
我们使用合成数据集和真实电厂数据集进行实证研究。这两个数据集的详细统计和设置如表1所示。 •合成数据。每个时间序列的公式如下: 其中srand是0或1个随机种子。上述公式捕捉了多元时间序列的三个属性:(a)三角函数(C1)模拟时间模式;(b) 延时t0∈ [50,100]和频率ω∈ [40,50](C2)模拟各种周期性循环;(c) 随机高斯噪声?∼ N(0,1)按系数λ=0.3(C3)缩放,模拟数据噪声以及各种形状。此外,如果两个正弦波的频率相似且几乎同相,则它们具有很高的相关性。通过随机选择每个时间序列的频率和相位,我们期望一些对具有高相关性,而一些具有低相关性。我们随机生成30个时间序列,每个序列包含20000个点。此外,在测试期间,将5个冲击波样异常(具有与正常数据类似的值范围,如图1(a)中的示例)随机注入3个随机时间序列(根本原因)。每个异常的持续时间属于三个尺度之一,即30、60、90。 表1:两个数据集的详细统计和设置。 •发电厂数据。这个数据集是在一个真正的发电厂上收集的。它包含由分布在发电厂系统中的传感器生成的36个时间序列。它有23040个时间步,包含一个由系统操作员识别的异常。此外,我们在测试期间随机注入4个额外的异常(类似于我们在合成数据中所做的),以进行全面评估。 我们将MSCRED与四类八种基线方法进行比较,即分类模型、密度估计模型、时间预测模型和MSCRED变体。 •分类模型。它学习一个决策函数,并将测试数据分类为与训练集相似或不同的数据。我们使用单类支持向量机模型(OC-SVM)(Manevitz和Yousef 2001)进行比较。 •密度估计模型。它为异常值检测建模数据密度。我们使用深度自动编码高斯混合模型(DAGMM)(Zong等人2018),并将能量分数(Zong等人2018)作为异常分数。 •预测模型。它对训练数据的时间依赖性进行建模,并预测测试数据的价值。我们采用了三种方法:历史平均(HA)、自回归移动平均(ARMA)(Hamilton 1994)和LSTM编码器-解码器(LSTM-ED)(Cho等人,2014)。异常分数定义为所有时间序列的平均预测误差。 MSCRED变异。除上述基线方法外,我们还考虑了三个MSCRD的变体来证明每个组件的有效性:(1)CNND(4)VALLSTM是注意模块的MCRDD,第一个三个VLSLSTM层被移除。(2) CNNED(3,4)ConvLSTM是MSCRED,带有注意模块,前两个ConvLSTM层已被移除。(3) CNNEDConvLSTM已被删除,注意模块已被删除。 我们使用Tensorflow来实现MSCRED及其变体,并在带有Intel(R)Xeon(R)CPU E5-2637 v4 3.50GHz和4个NVIDIA GTX 1080 Ti图形卡的服务器上对其进行培训。MSCRED的参数设置在模型部分进行了说明。此外,异常分数被定义为重建较差的成对相关数。换句话说,在不同的数据集上,根据经验确定剩余特征矩阵和θ中的元素数量,其值大于给定阈值θ。 我们使用三个指标,即,来评估每种方法的异常检测性能。为了检测异常,我们按照领域专家的建议,设置阈值τ=β·max{s(t)valid},其中s(t)valid是验证期间的异常分数和β∈ [1,2]设置为在验证期间最大化F1分数。根据该阈值计算测试期间的回忆和准确度分数。两个数据集上的实验重复5次,并报告平均结果进行比较。请注意,MSCRED的输出包含三个通道的剩余特征矩阵w.r。t、 不同的段长度。我们使用最小值(w=10)进行以下异常检测和根本原因识别评估。三通道结果的性能比较也将用于异常严重性解释。
绩效评估
表2中报告了不同异常检测方法的性能,其中最佳分数用粗体突出显示,最佳基线分数用下划线表示。最后一行报告了MSCRED相对于最佳基线方法的改善(%)。 **•(RQ1:与基线的比较)**在表2中,我们观察到(a)时间预测模型比分类和密度估计模型表现更好,表明两个数据集都具有时间依赖性;(b) LSTMED的性能优于ARMA,表明深度学习模型比传统方法能捕捉到更复杂的数据关系;(c) MSCRED在所有设置下都表现最佳。与最佳基线相比,改善幅度在13.3%到30.0%之间。换句话说,MSCRED比基线方法好得多,因为它可以有效地建模多变量时间序列的传感器间相关性和时间模式。 为了详细展示比较,图3提供了MSCRED的案例研究和两种最佳基线方法,即ARMA和LSTM-ED,用于两种数据集。我们可以观察到,ARMA的异常评分并不稳定,结果包含许多假阳性和假阴性。同时,LSTM-ED的异常评分比ARMA平滑,但仍包含多个假阳性和假阴性。MSCRED可以检测所有异常,没有任何假阳性和假阴性。为了证明更具说服力的评估,我们对另一个包含10个异常的合成数据进行了实验(很容易生成包含更多异常的更大数据)。MSCRED的平均回忆和准确度得分(5次重复实验)为(0.84,0.95),而LSTM-ED的值为(0.64,0.87)。此外,我们还对另一个大型电厂的数据进行了实验,其中有920个传感器和11个标记异常。MSCRED的召回率和准确度得分为(7/11,7/13),而LSTMED的值为(5/11,5/17)。所有的评估结果都表明了我们模型的有效性。 **•(RQ2:与模型变体的比较)**在表2中,我们还观察到,通过增加CONVLSM层的数量,MSCRED的性能得到改善。具体而言,CNNEDConvLSTM优于CNNED(3,4)ConvLSTM,CNNED(3,4)ConvLSTM的性能优于CNNED(4)ConvLSTM,表明了ConvLSTM层和堆叠解码过程对模型细化的有效性。我们还观察到,CNNEDConvLSTM比MSCRED更差,这表明基于注意的ConvLSTM可以进一步提高异常检测性能。 表2:两个数据集的异常检测结果。 图3:异常检测的案例研究。阴影区域代表异常周期。红色虚线是异常的切割阈值。 作为异常诊断任务之一,根本原因识别依赖于良好的异常检测性能。因此,我们比较了MSCRED和最佳基线(即LSTM-ED)的性能。具体而言,对于LSTM-ED,我们使用每个时间序列的预测误差来表示该序列的异常分数。MSCRED的相同值定义为残差特征矩阵的特定行/列中重建不良的成对相关性的数量,因为每行/列表示一个时间序列。对于每个异常事件,我们根据其异常分数对所有时间序列进行排序,并确定top-k序列为根本原因。图5显示了平均值recall@k(k=3)在5个重复实验中。MSCRED在合成数据和发电厂数据方面分别比LSTM-ED高出25.9%和32.4%。 图4:电厂数据中最后两个CONVLSM层的注意力权重平均分布。
图5:根本原因识别的性能 异常严重程度(持续时间)解释(RQ4)。MSCRED的特征矩阵包括s通道(在当前实验中为s=3),这些通道捕捉不同尺度下的系统状态。为了解释异常严重性,我们首先根据三个通道的剩余特征矩阵计算不同的异常分数,即小通道、中通道和大通道,段大小分别为w=10、30和60,并将它们表示为MSCRED(S)、MSCRED(M)和MSCRED(L)。然后,我们独立评估了他们在三种类型的异常上的表现,即短期、中期和长期,持续时间分别为10、30和60。图6显示了两个数据集上5次重复实验的平均回忆分数。我们可以观察到,MSCRED(S)可以检测所有类型的异常,MSCRED(M)可以检测中长期异常。相反,MSCRED(L)只能检测长持续时间异常。因此,我们可以通过综合考虑三个异常分数来解释异常严重性。如果能在所有三个通道中检测到异常,则异常更可能持续很长时间。否则,它可能是短期或中期异常。为了更好地展示MSCRED的有效性,图7提供了发电厂数据异常诊断的案例研究。在这种情况下,MSCRED检测所有5种异常,包括3种短期、1种中期和1种长期异常。MSCRED(M)未检测到两个短期异常,MSCRED(L)仅检测到长期异常。此外,注入异常事件的四个残差特征矩阵显示了根本原因识别结果。在这种情况下,我们可以准确地找出超过一半的异常根本原因(用红色矩形突出显示的行/列)。 图6:MSCRED三个通道在不同类型异常上的性能。 图8:数据噪声对异常检测的影响。 在实际应用中,多变量时间序列往往含有噪声,因此异常检测算法对输入噪声的鲁棒性非常重要。为了研究MSCRED对异常检测的鲁棒性,我们通过在方程7中添加各种噪声因子λ,在不同的合成数据集中进行实验。图8显示了λ对MSCRED、ARMA和LSTM-ED性能的影响。与之前的评估类似,我们根据优化的切割阈值计算精度和召回分数,并报告5个重复实验的平均值进行比较。我们可以观察到,当噪声等级在0.2到0.45之间变化时,MSCRED始终优于ARMA和LSTM-ED。这表明,与ARMA和LSTMED相比,MSCRED对输入噪声的鲁棒性更强。
结论
在本文中,我们提出了异常检测和诊断问题,并开发了一个创新模型,即MSCRED来解决该问题。MSCRED采用多尺度(分辨率)系统特征矩阵来表征不同时间段的整个系统状态,并采用深度编码器-解码器框架来生成重构的特征矩阵。该框架能够对多变量时间序列的传感器间相关性和时间依赖性进行建模。残差特征矩阵被进一步用于检测和诊断异常。对合成数据集和电厂数据集进行的大量实证研究表明,MSCRED的性能优于最先进的基线方法。 References [Bahdanau, Cho, and Bengio 2014] Bahdanau, D.; Cho, K.; and Bengio, Y . 2014. Neural machine translation by jointly learning to align and translate. In ICLR. [Brockwell and Davis 2013] Brockwell, P . J., and Davis, R. A. 2013. Time series: theory and methods. Springer Science & Busi- ness Media. [Campello et al. 2015] Campello, R. J.; Moulavi, D.; Zimek, A.; and Sander, J. 2015. Hierarchical density estimates for data clus- tering, visualization, and outlier detection. ACM Trans. Knowl. Discov. Data. 10(1):5. [Chandola, Banerjee, and Kumar 2009] Chandola, V .; Banerjee, A.; and Kumar, V . 2009. Anomaly detection: A survey. ACM Comput. Surv. 41(3):15. [Chen et al. 2008] Chen, H.; Cheng, H.; Jiang, G.; and Y oshihira, K. 2008. Exploiting local and global invariants for the management of large scale information systems. In ICDM, 113–122. [Cheng et al. 2016] Cheng, W.; Zhang, K.; Chen, H.; Jiang, G.; Chen, Z.; and Wang, W. 2016. Ranking causal anomalies via tem- poral and dynamical analysis on vanishing correlations. In KDD, 805–814. [Cho et al. 2014] Cho, K.; V an Merriënboer, B.; Gulcehre, C.; Bah- danau, D.; Bougares, F.; Schwenk, H.; and Bengio, Y . 2014. Learn- ing phrase representations using rnn encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078. [Djurdjanovic, Lee, and Ni 2003] Djurdjanovic, D.; Lee, J.; and Ni, J. 2003. Watchdog agentan infotronics-based prognostics approach for product performance degradation assessment and prediction. Adv. Eng. Inform. 17(3-4):109–125. [Görnitz et al. 2013] Görnitz, N.; Kloft, M.; Rieck, K.; and Brefeld, U. 2013. Toward supervised anomaly detection. J. Artif. Intell. Res. 46:235–262. [Günnemann, Günnemann, and Faloutsos 2014] Günnemann, N.; Günnemann, S.; and Faloutsos, C. 2014. Robust multivariate autoregression for anomaly detection in dynamic product ratings. In WWW, 361–372. [Hallac et al. 2017] Hallac, D.; V are, S.; Boyd, S.; and Leskovec, J. 2017. Toeplitz inverse covariance-based clustering of multivariate time series data. In KDD, 215–223. [Hamilton 1994] Hamilton, J. D. 1994. Time series analysis, vol- ume 2. Princeton university press Princeton, NJ. [Hautama¨ki, Ka¨rkka¨ınen, and Fra¨nti 2004] Hautama¨ki, V .; Ka¨rkka¨ınen, I.; and Fra¨nti, P . 2004. Outlier detection using k-nearest neighbour graph. In ICPR, 430–433. [He, Xu, and Deng 2003] He, Z.; Xu, X.; and Deng, S. 2003. Dis- covering cluster-based local outliers. Pattern Recognit. Lett. 24(9- 10):1641–1650. [Idé, Papadimitriou, and Vlachos 2007] Idé, T.; Papadimitriou, S.; and Vlachos, M. 2007. Computing correlation anomaly scores using stochastic nearest neighbors. In ICDM, 523–528. [Karim et al. 2018] Karim, F.; Majumdar, S.; Darabi, H.; and Chen, S. 2018. Lstm fully convolutional networks for time series classi- fication. IEEE Access 6:1662–1669. [Keogh et al. 2001] Keogh, E.; Chu, S.; Hart, D.; and Pazzani, M. 2001. An online algorithm for segmenting time series. In ICDM, 289–296. [Kingma and Ba 2014] Kingma, D. P ., and Ba, J. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980. [Klambauer et al. 2017] Klambauer, G.; Unterthiner, T.; Mayr, A.; and Hochreiter, S. 2017. Self-normalizing neural networks. In NIPS, 971–980. [Kriegel et al. 2012] Kriegel, H.-P .; Kroger, P .; Schubert, E.; and Zimek, A. 2012. Outlier detection in arbitrarily oriented subspaces. In ICDM, 379–388. [Lazarevic and Kumar 2005] Lazarevic, A., and Kumar, V . 2005. Feature bagging for outlier detection. In KDD, 157–166. [Lemire 2007] Lemire, D. 2007. A better alternative to piecewise linear time series segmentation. In SDM, 545–550. [Len, Vittal, and Manimaran 2007] Len, R. A.; Vittal, V .; and Man- imaran, G. 2007. Application of sensor network for secure electric energy infrastructure. IEEE Trans. Power Del. 22(2):1021–1028. [Li and Prakash 2011] Li, L., and Prakash, B. A. 2011. Time series clustering: Complex is simpler! In ICML, 185–192. [Long, Shelhamer, and Darrell 2015] Long, J.; Shelhamer, E.; and Darrell, T. 2015. Fully convolutional networks for semantic seg- mentation. In CVPR, 3431–3440. [Malhotra et al. 2016] Malhotra, P .; Ramakrishnan, A.; Anand, G.; Vig, L.; Agarwal, P .; and Shroff, G. 2016. Lstm-based encoder- decoder for multi-sensor anomaly detection. In ICML Workshop. [Manevitz and Y ousef 2001] Manevitz, L. M., and Y ousef, M. 2001. One-class svms for document classification. J. Mach. Learn. Res. 2(Dec):139–154. [Qin et al. 2017] Qin, Y .; Song, D.; Chen, H.; Cheng, W.; Jiang, G.; and Cottrell, G. 2017. A dual-stage attention-based recurrent neu- ral network for time series prediction. In IJCAI. [Shi et al. 2015] Shi, X.; Chen, Z.; Wang, H.; Yeung, D.-Y .; Wong, W.-K.; and Woo, W.-c. 2015. Convolutional lstm network: A ma- chine learning approach for precipitation nowcasting. In NIPS, 802–810. References [Bahdanau, Cho, and Bengio 2014] Bahdanau, D.; Cho, K.; and Bengio, Y . 2014. Neural machine translation by jointly learning to align and translate. In ICLR. [Brockwell and Davis 2013] Brockwell, P . J., and Davis, R. A. 2013. Time series: theory and methods. Springer Science & Busi- ness Media. [Campello et al. 2015] Campello, R. J.; Moulavi, D.; Zimek, A.; and Sander, J. 2015. Hierarchical density estimates for data clus- tering, visualization, and outlier detection. ACM Trans. Knowl. Discov. Data. 10(1):5. [Chandola, Banerjee, and Kumar 2009] Chandola, V .; Banerjee, A.; and Kumar, V . 2009. Anomaly detection: A survey. ACM Comput. Surv. 41(3):15. [Chen et al. 2008] Chen, H.; Cheng, H.; Jiang, G.; and Y oshihira, K. 2008. Exploiting local and global invariants for the management of large scale information systems. In ICDM, 113–122. [Cheng et al. 2016] Cheng, W.; Zhang, K.; Chen, H.; Jiang, G.; Chen, Z.; and Wang, W. 2016. Ranking causal anomalies via tem- poral and dynamical analysis on vanishing correlations. In KDD, 805–814. [Cho et al. 2014] Cho, K.; V an Merriënboer, B.; Gulcehre, C.; Bah- danau, D.; Bougares, F.; Schwenk, H.; and Bengio, Y . 2014. Learn- ing phrase representations using rnn encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078. [Djurdjanovic, Lee, and Ni 2003] Djurdjanovic, D.; Lee, J.; and Ni, J. 2003. Watchdog agentan infotronics-based prognostics approach for product performance degradation assessment and prediction. Adv. Eng. Inform. 17(3-4):109–125. [Görnitz et al. 2013] Görnitz, N.; Kloft, M.; Rieck, K.; and Brefeld, U. 2013. Toward supervised anomaly detection. J. Artif. Intell. Res. 46:235–262. [Günnemann, Günnemann, and Faloutsos 2014] Günnemann, N.; Günnemann, S.; and Faloutsos, C. 2014. Robust multivariate autoregression for anomaly detection in dynamic product ratings. In WWW, 361–372. [Hallac et al. 2017] Hallac, D.; V are, S.; Boyd, S.; and Leskovec, J. 2017. Toeplitz inverse covariance-based clustering of multivariate time series data. In KDD, 215–223. [Hamilton 1994] Hamilton, J. D. 1994. Time series analysis, vol- ume 2. Princeton university press Princeton, NJ. [Hautama¨ki, Ka¨rkka¨ınen, and Fra¨nti 2004] Hautama¨ki, V .; Ka¨rkka¨ınen, I.; and Fra¨nti, P . 2004. Outlier detection using k-nearest neighbour graph. In ICPR, 430–433. [He, Xu, and Deng 2003] He, Z.; Xu, X.; and Deng, S. 2003. Dis- covering cluster-based local outliers. Pattern Recognit. Lett. 24(9- 10):1641–1650. [Idé, Papadimitriou, and Vlachos 2007] Idé, T.; Papadimitriou, S.; and Vlachos, M. 2007. Computing correlation anomaly scores using stochastic nearest neighbors. In ICDM, 523–528. [Karim et al. 2018] Karim, F.; Majumdar, S.; Darabi, H.; and Chen, S. 2018. Lstm fully convolutional networks for time series classi- fication. IEEE Access 6:1662–1669. [Keogh et al. 2001] Keogh, E.; Chu, S.; Hart, D.; and Pazzani, M. 2001. An online algorithm for segmenting time series. In ICDM, 289–296. [Kingma and Ba 2014] Kingma, D. P ., and Ba, J. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980. [Klambauer et al. 2017] Klambauer, G.; Unterthiner, T.; Mayr, A.; and Hochreiter, S. 2017. Self-normalizing neural networks. In NIPS, 971–980. [Kriegel et al. 2012] Kriegel, H.-P .; Kroger, P .; Schubert, E.; and Zimek, A. 2012. Outlier detection in arbitrarily oriented subspaces. In ICDM, 379–388. [Lazarevic and Kumar 2005] Lazarevic, A., and Kumar, V . 2005. Feature bagging for outlier detection. In KDD, 157–166. [Lemire 2007] Lemire, D. 2007. A better alternative to piecewise linear time series segmentation. In SDM, 545–550. [Len, Vittal, and Manimaran 2007] Len, R. A.; Vittal, V .; and Man- imaran, G. 2007. Application of sensor network for secure electric energy infrastructure. IEEE Trans. Power Del. 22(2):1021–1028. [Li and Prakash 2011] Li, L., and Prakash, B. A. 2011. Time series clustering: Complex is simpler! In ICML, 185–192. [Long, Shelhamer, and Darrell 2015] Long, J.; Shelhamer, E.; and Darrell, T. 2015. Fully convolutional networks for semantic seg- mentation. In CVPR, 3431–3440. [Malhotra et al. 2016] Malhotra, P .; Ramakrishnan, A.; Anand, G.; Vig, L.; Agarwal, P .; and Shroff, G. 2016. Lstm-based encoder- decoder for multi-sensor anomaly detection. In ICML Workshop. [Manevitz and Y ousef 2001] Manevitz, L. M., and Y ousef, M. 2001. One-class svms for document classification. J. Mach. Learn. Res. 2(Dec):139–154. [Qin et al. 2017] Qin, Y .; Song, D.; Chen, H.; Cheng, W.; Jiang, G.; and Cottrell, G. 2017. A dual-stage attention-based recurrent neu- ral network for time series prediction. In IJCAI. [Shi et al. 2015] Shi, X.; Chen, Z.; Wang, H.; Yeung, D.-Y .; Wong, W.-K.; and Woo, W.-c. 2015. Convolutional lstm network: A ma- chine learning approach for precipitation nowcasting. In NIPS, 802–810.