**前言:**2022年7月26日使用cephadm进行ceph集群、使用集群ceph octopus版本,v15.2.16。
一、cephadm简介
Cephadm通过manager daemon SSH连接到主机的部署和管理Ceph添加、删除或更新集Ceph daemon containers。它不依赖于诸如Ansible,Rook或Salt外部配置或安排工具。
Cephadm管理Ceph集群的整个生命周期。它首先引导一个小节点Ceph集群(one monitor and one manager),然后自动将集群扩展到多个主机节点,并提供一切Ceph守护程序和服务。这可以通过Ceph命令行界面(CLI)或仪表板(GUI)执行。Cephadm是Octopus v15.2.0版本中的新功能不支持旧版本Ceph。
二、节点规划
| cephadm、mon、mds、rgw、osd、mgr | 192.168.18.137 | node1 |
| mon、mds、rgw、osd、mgr | 192.168.18.138 | node2 |
| mon、mds、rgw、osd、mgr | 192.168.18.139 | node3 |
三、操作
1. 前期准备
1.1 配置主机名
#提前规划各节点配置的主机名称
hostnamectl set-hostname node1 && bash 1.2 关闭selinux
sed -i s/SELINUX=.*/SELINUX=disabled/g /etc/selinux/config setenforce 0 1.3 关闭firewalld
systemctl stop firewalld && systemctl disable firewalld 1.4 配置免密登录
#这一步只有cephadm节点执行
ssh-keygen ssh-copy-id root@192.168.18.138 ssh-copy-id root@192.168.18.139 1.5 配置hosts解析
#在cephadm使用完成节点配置scp传输到每个节点
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.18.137 node1 192.168.18.138 node2 192.168.18.139 node3 1.6 同步配置时间
yum -y install chrony systemctl start chronyd && systemctl enable chronyd chronyc sources -v #查看同步时间源服务器 1.7安装docker并配置加速源
所有节点都需要安装
yum -y install docker-ce [root@node1 ~]# cat /etc/docker/daemon.json { "registry-mirrors": ["https://p4s6awgf.mirror.aliyuncs.com"] } 2. 部署集群
2.1 安装cephadm
#从github下载cephadm脚本
curl --silent --remote-name --location https://github.com/ceph/ceph/raw/quincy/src/cephadm/cephadm #安装cephadm,ceph需要python3和epel源;安装步骤的执行有时会报错无效gpg密钥,可以ceph.repo文件中gpgcheck参数改为0,表示密钥验证不适用 #python3和epel源每个节点都需要安装,否则后续添加集群会报错
chmod x cephadm yum install -y epel-release yum install -y python3 ./cephadm add-repo --release octopus #使用cephadm需要生成脚本yum(可替代国内源提高下载速度) sed -i 's#download.ceph.com#mirrors.aliyun.com/ceph#' /etc/yum.repos.d/ceph.repo ##可以选择是否替换国内来源 ./cephadm install #安装cephadm 2.2 引导新集群
#这个命令的作用
在本地主机上创建新集群monitor 和 manager daemon守护程序。
为Ceph生成一个新的集群SSH并添加密钥root用户的/root/.ssh/authorized_keys文件中。
保存与新群集通信所需的最小配置文件/etc/ceph/ceph.conf。
向/etc/ceph/ceph.client.admin.keyring写入client.admin管理(特权!secret key的副本。
将public key写入/etc/ceph/ceph.pub。
cephadm bootstrap --mon-ip 192.168.18.137 #执行上述后Pulling container image quay.io/ceph/ceph:v15…步骤需要很长时间,因为它会拉很多docker镜像,这里需要注意的是,下面的返回表示安装成功
Verifying podman|docker is present... Verifying lvm2 is present... Verifying time synchronization is in place... Unit chronyd.service is enabled and running Repeating the final host check... podman|docker (/usr/bin/docker) is present systemctl is present lvcreate is present Unit chronyd.service is enabled and running Host looks OK Cluster fsid: 8e95f1ea-0cc2-11ed-8c01-000c298f2653 Verifying IP 192.168.18.137 port 3300 ... Verifying IP 192.168.18.137 port 6789 ... Mon IP 192.168.18.137 is in CIDR network 192.168.18.0/24 Pulling containerimage quay.io/ceph/ceph:v15...
Extracting ceph user uid/gid from container image...
......
Ceph Dashboard is now available at: #dashboard登录方式,注意保存好,第一次登录会提示改密码
URL: https://node1:8443/
User: admin
Password: y3244gzrbw
You can access the Ceph CLI with:
sudo /usr/sbin/cephadm shell --fsid 8e95f1ea-0cc2-11ed-8c01-000c298f2653 -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyring
Please consider enabling telemetry to help improve Ceph:
ceph telemetry on
For more information see:
https://docs.ceph.com/docs/master/mgr/telemetry/
#查看拉取的那些镜像
[root@node1 ceph]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
quay.io/ceph/ceph v15 296d7fe77d4e 6 weeks ago 1.12GB
quay.io/ceph/ceph-grafana 6.7.4 557c83e11646 11 months ago 486MB
ubuntu latest f643c72bc252 20 months ago 72.9MB
quay.io/prometheus/prometheus v2.18.1 de242295e225 2 years ago 140MB
quay.io/prometheus/alertmanager v0.20.0 0881eb8f169f 2 years ago 52.1MB
quay.io/prometheus/node-exporter v0.18.1 e5a616e4b9cf 3 years ago 22.9MB
#查看目前启动的容器
[root@node1 ceph]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
b0d18a45272b quay.io/ceph/ceph-grafana:6.7.4 "/bin/sh -c 'grafana…" 12 minutes ago Up 12 minutes ceph-8e95f1ea-0cc2-11ed-8c01-000c298f2653-grafana.node1
7f95dd95cb73 quay.io/prometheus/alertmanager:v0.20.0 "/bin/alertmanager -…" 12 minutes ago Up 12 minutes ceph-8e95f1ea-0cc2-11ed-8c01-000c298f2653-alertmanager.node1
0569b1efbef8 quay.io/prometheus/prometheus:v2.18.1 "/bin/prometheus --c…" 12 minutes ago Up 12 minutes ceph-8e95f1ea-0cc2-11ed-8c01-000c298f2653-prometheus.node1
677250e756c1 quay.io/prometheus/node-exporter:v0.18.1 "/bin/node_exporter …" 13 minutes ago Up 13 minutes ceph-8e95f1ea-0cc2-11ed-8c01-000c298f2653-node-exporter.node1
7f92939465a8 quay.io/ceph/ceph:v15 "/usr/bin/ceph-crash…" 18 minutes ago Up 18 minutes ceph-8e95f1ea-0cc2-11ed-8c01-000c298f2653-crash.node1
24da9032674d quay.io/ceph/ceph:v15 "/usr/bin/ceph-mgr -…" 19 minutes ago Up 19 minutes ceph-8e95f1ea-0cc2-11ed-8c01-000c298f2653-mgr.node1.nsnfhq
34c6f29c15f7 quay.io/ceph/ceph:v15 "/usr/bin/ceph-mon -…" 19 minutes ago Up 19 minutes ceph-8e95f1ea-0cc2-11ed-8c01-000c298f2653-mon.node1
2.3 启用ceph命令
2.3.1 切换ceph命令模式
#cephadm安装完成稍微有些不一样,需要切换shell才可以使用ceph命令
[root@node1 ~]# cephadm shell #切换模式
Inferring fsid 8e95f1ea-0cc2-11ed-8c01-000c298f2653
Inferring config /var/lib/ceph/8e95f1ea-0cc2-11ed-8c01-000c298f2653/mon.node1/config
Using recent ceph image quay.io/ceph/ceph@sha256:c3336a5b10b069b127d1a66ef97d489867fc9c2e4f379100e5a06f99f137a420
[ceph: root@node1 /]# ceph -s
cluster:
id: 8e95f1ea-0cc2-11ed-8c01-000c298f2653
health: HEALTH_WARN
OSD count 0 < osd_pool_default_size 3
services:
mon: 1 daemons, quorum node1 (age 29m)
mgr: node1.nsnfhq(active, since 28m)
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
[ceph: root@node1 /]# ceph orch ps #查看目前集群内运行的组件(包括其他节点)
NAME HOST STATUS REFRESHED AGE VERSION IMAGE NAME IMAGE ID CONTAINER ID
alertmanager.node1 node1 running (22m) 2m ago 27m 0.20.0 quay.io/prometheus/alertmanager:v0.20.0 0881eb8f169f 7f95dd95cb73
crash.node1 node1 running (27m) 2m ago 27m 15.2.16 quay.io/ceph/ceph:v15 296d7fe77d4e 7f92939465a8
grafana.node1 node1 running (22m) 2m ago 23m 6.7.4 quay.io/ceph/ceph-grafana:6.7.4 557c83e11646 b0d18a45272b
mgr.node1.nsnfhq node1 running (29m) 2m ago 29m 15.2.16 quay.io/ceph/ceph:v15 296d7fe77d4e 24da9032674d
mon.node1 node1 running (29m) 2m ago 29m 15.2.16 quay.io/ceph/ceph:v15 296d7fe77d4e 34c6f29c15f7
node-exporter.node1 node1 running (23m) 2m ago 23m 0.18.1 quay.io/prometheus/node-exporter:v0.18.1 e5a616e4b9cf 677250e756c1
prometheus.node1 node1 running (22m) 2m ago 22m 2.18.1 quay.io/prometheus/prometheus:v2.18.1 de242295e225 0569b1efbef8
[ceph: root@node1 /]# ceph orch ps --daemon-type mon #查看某一组件的状态
NAME HOST STATUS REFRESHED AGE VERSION IMAGE NAME IMAGE ID CONTAINER ID
mon.node1 node1 running (30m) 2m ago 30m 15.2.16 quay.io/ceph/ceph:v15 296d7fe77d4e 34c6f29c15f7
[ceph: root@node1 /]# exit #推出命令模式
2.3.2 ceph命令的第二种应用
[root@node1 ~]# cephadm shell -- ceph -s
Inferring fsid 8e95f1ea-0cc2-11ed-8c01-000c298f2653
Inferring config /var/lib/ceph/8e95f1ea-0cc2-11ed-8c01-000c298f2653/mon.node1/config
Using recent ceph image quay.io/ceph/ceph@sha256:c3336a5b10b069b127d1a66ef97d489867fc9c2e4f379100e5a06f99f137a420
cluster:
id: 8e95f1ea-0cc2-11ed-8c01-000c298f2653
health: HEALTH_WARN
OSD count 0 < osd_pool_default_size 3
services:
mon: 1 daemons, quorum node1 (age 33m)
mgr: node1.nsnfhq(active, since 32m)
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
2.3.3 下载ceph-common包提供ceph命令
#安装ceph-common包
cephadm install ceph-common
[root@node1 ~]# ceph -v #安装完成后测试是否可以直接使用ceph命令
ceph version 15.2.16 (d46a73d6d0a67a79558054a3a5a72cb561724974) octopus (stable)
2.4 启用ceph组件
#首先在新主机的根用户authorized_keys文件中安装集群的公共SSH密钥
ssh-copy-id -f -i /etc/ceph/ceph.pub root@node2
ssh-copy-id -f -i /etc/ceph/ceph.pub root@node3
2.4.1 创建mon和mgr
#只能一个一个添加
ceph orch host add node2
ceph orch host add node3
#查看目前集群纳管的节点
[root@node1 ~]# ceph orch host ls
HOST ADDR LABELS STATUS
node1 node1
node2 node2
node3 node3
#纳管别的节点后会在别的节点自动安装mon和mgr两个组件,安装过程比较慢;安装完成后使用以下命令查看; #ceph集群一般默认会允许存在5个mon和2个mgr;可以使用ceph orch apply mon --placement="3 node1 node2 node3"进行手动修改
[root@node1 ~]# ceph orch ls |grep mon
mon 3/5 5m ago 17h count:5 quay.io/ceph/ceph:v15 296d7fe77d4e
[root@node1 ~]# ceph orch apply mon --placement="3 node1 node2 node3"
Scheduled mon update...
[root@node1 ~]# ceph orch ls
NAME RUNNING REFRESHED AGE PLACEMENT IMAGE NAME IMAGE ID
mon 3/3 6m ago 5s node1;node2;node3;count:3 quay.io/ceph/ceph:v15 296d7fe77d4e
[root@node1 ~]# ceph orch ls |grep mgr
mgr 2/2 7m ago 17h count:2 quay.io/ceph/ceph:v15 296d7fe77d4e
"/usr/bin/ceph-crash…" 15 hours ago Up 15 hours ceph-8e95f1ea-0cc2-11ed-8c01-000c298f2653-crash.node2
[root@node1 ~]# ceph orch apply mgr --placement="3 node1 node2 node3"
[root@node1 ~]# ceph orch ls |grep mgr
mgr 3/3 70s ago 74s node1;node2;node3;count:3 quay.io/ceph/ceph:v15 296d7fe77d4e
2.4.2 创建osd
#查看目前ceph集群内的osd,因为还未创建,回显为空
ceph orch deveice ls
#创建osd
ceph orch daemon add osd <hostname>:</dev/sdX>
2.4.3 创建mds
#首先创建cephfs,不指定pg的话,默认自动调整
ceph osd pool create cephfs_data
ceph osd pool create cephfs_metadata
ceph fs new cephfs cephfs_metadata cephfs_data
#开启mds组件,cephfs:文件系统名称;–placement:指定集群内需要几个mds,后面跟主机名
ceph orch apply mds cephfs --placement="3 node1 node2 node3"
#查看各节点是否已启动mds容器;还可以使用ceph orch ps 查看某一节点运行的容器
[root@node1 ~]# ceph orch ps --daemon-type mds
mds.cephfs.node1.xwflet node1 running (13m) 3m ago 13m 15.2.16 quay.io/ceph/ceph:v15 296d7fe77d4e d3016ca78432
mds.cephfs.node2.zgcxxv node2 running (13m) 3m ago 13m 15.2.16 quay.io/ceph/ceph:v15 296d7fe77d4e 71b53d26f319
mds.cephfs.node3.lvwumj node3 running (13m) 3m ago 13m 15.2.16 quay.io/ceph/ceph:v15 296d7fe77d4e aae556cadd84
2.4.4 创建rgw
#首先创建一个领域
radosgw-admin realm create --rgw-realm=myorg --default
#创建区域组
radosgw-admin zonegroup create --rgw-zonegroup=default --master --default
#创建区域
radosgw-admin zone create --rgw-zonegroup=default --rgw-zone=cn-east-1 --master --default
#为特定领域和区域部署radosgw守护程序
ceph orch apply rgw myorg cn-east-1 --placement="3 node1 node2 node3"
#验证各节点是否启动rgw容器
[root@node1 ~]# ceph orch ps --daemon-type rgw
rgw.myorg.cn-east-1.node1.skjzzm node1 running (3m) 3m ago 3m 15.2.16 quay.io/ceph/ceph:v15 296d7fe77d4e ee7d5843e78a
rgw.myorg.cn-east-1.node2.wcizhr node2 running (3m) 3m ago 3m 15.2.16 quay.io/ceph/ceph:v15 296d7fe77d4e ab1d93c9013b
rgw.myorg.cn-east-1.node3.dmxggg node3 running (3m) 3m ago 3m 15.2.16 quay.io/ceph/ceph:v15 296d7fe77d4e 2d5ced948fe3
2.5 为所有节点安装ceph-common包
#其他节点因为没有cephadm脚本,所以不能使用ceph命令,我们手动安装ceph-common进行解决
scp /etc/yum.repos.d/ceph.repo node2:/etc/yum.repos.d/ #将主节点的ceph源同步至其他节点
yum -y install ceph-common #在节点安装ceph-common,ceph-common包会提供ceph命令并在etc下创建ceph目录
scp /etc/ceph/ceph.conf node2:/etc/ceph/ #将ceph.conf文件传输至对应节点
scp /etc/ceph/ceph.client.admin.keyring node2:/etc/ceph/ #将密钥文件传输至对应节点
#在对应节点进行测试
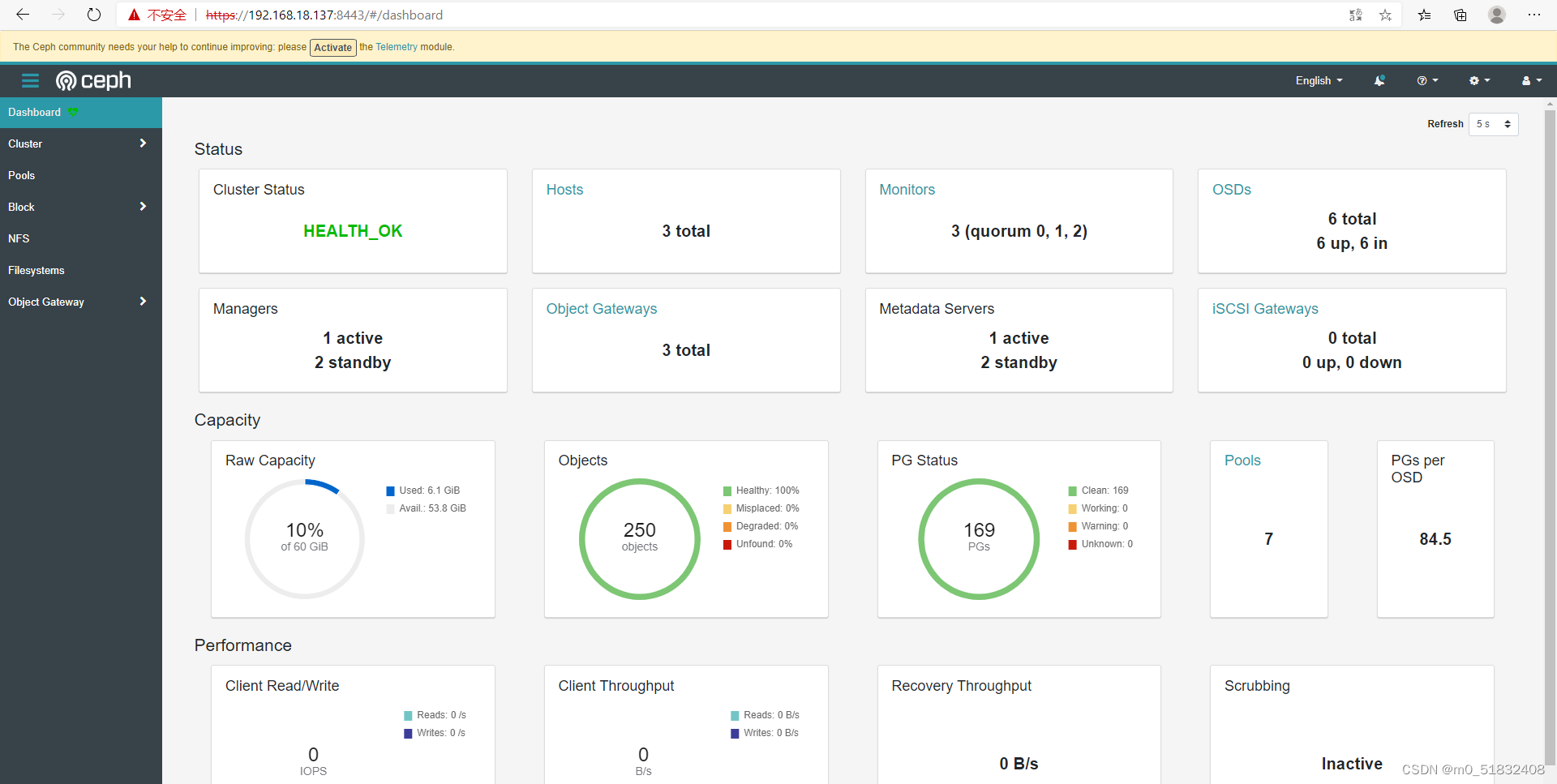
[root@node2 ceph]# ceph -s
cluster:
id: 8e95f1ea-0cc2-11ed-8c01-000c298f2653
health: HEALTH_OK
services:
mon: 3 daemons, quorum node1,node2,node3 (age 38m)
mgr: node1.nsnfhq(active, since 21h), standbys: node2.wtbkhf, node3.vkrufi
mds: cephfs:1 {0=cephfs.node1.xwflet=up:active} 2 up:standby
osd: 6 osds: 6 up (since 38m), 6 in (since 5h)
rgw: 3 daemons active (myorg.cn-east-1.node1.skjzzm, myorg.cn-east-1.node2.wcizhr, myorg.cn-east-1.node3.dmxggg)
task status:
data:
pools: 7 pools, 169 pgs
objects: 250 objects, 7.7 KiB
usage: 6.1 GiB used, 54 GiB / 60 GiB avail
pgs: 169 active+clean
3. 简单命令整理
ceph orch ls #列出集群内运行的组件 ceph orch host ls #列出集群内的主机 ceph orch ps #列出集群内容器的详细信息 ceph orch apply mon --placement="3 node1 node2 node3" #调整组件的数量 ceph orch ps --daemon-type rgw #--daemon-type:指定查看的组件 ceph orch host label add node1 mon #给某个主机指定标签 ceph orch apply mon label:mon #告诉cephadm根据标签部署mon,修改后只有包含mon的主机才会成为mon,不过原来启动的mon现在暂时不会关闭 ceph orch device ls #列出集群内的存储设备 例如,要在newhost1IP地址10.1.2.123上部署第二台监视器,并newhost2在网络10.1.2.0/24中部署第三台monitor ceph orch apply mon --unmanaged #禁用mon自动部署 ceph orch daemon add mon newhost1:10.1.2.123 ceph orch daemon add mon newhost2:10.1.2.0/24
4. ceph可视化展示
#这里需要用到第一次引导集群时升级的dashboard账密,建议在浏览器使用IP进行访问,因为自己的windows系统没有配置主机名解析是访问不到的;
https://192.168.18.137:8443
4.2Prometheus
#Prometheus用的是http协议登录 http://192.168.18.137:9095/ #查看Prometheus的target
4.3 grafana
#点击manager https://192.168.18.137:3000/ #点击ceph-cluter #集群运行状态