文章目录
- JPEG原理分析及JPEG调试解码器
-
- 一、JPEG格式介绍
-
- § \text{\S} § 1.1 JPEG简介
- § \text{\S} § 1.2 JPEG编码流程
-
- § \text{\S} § 1.2.1 色彩空间转换
- § \text{\S} § 1.2.2 采样
- § \text{\S} § 1.2.3 电平偏置
- § \text{\S} § 1.2.4 8 × 8 8 \times 8 8×8DCT变换
- § \text{\S} § 1.2.5 量化
- § \text{\S} § 1.2.6 DC系数编码
- § \text{\S} § 1.2.7 AC系数编码
- § \text{\S} § 1.3 JPEG文件格式
-
- § \text{\S} § 1.3.1 JPEG语法结构
- § \text{\S} § 1.3.2 APP0 Segment
- § \text{\S} § 1.3.3 量化表DQT
- § \text{\S} § 1.3.4 帧图像开始SOF0
- § \text{\S} § 1.3.5 Huffman表
-
- 建立Huffman表
- 直流
- 交流
- 二、JPEG代码分析
-
- § \text{\S} § 2.1 代码架构
-
- § \text{\S} § 2.1.1 main函数
- § \text{\S} § 2.1.2 convert_one_image
- § \text{\S} § 2.1.3 tinyjpeg_decode
- § \text{\S} § 2.1.4 tinyjpeg_parse_header
- § \text{\S} § 2.1.5 parse_JFIF
- § \text{\S} § 2.1.6 parse_DQT
- § \text{\S} § 2.1.7 parse_DHT
- § \text{\S} § 2.2 结构体解析
-
- § \text{\S} § 2.2.1 huffman_table
- § \text{\S} § 2.2.2 component
- § \text{\S} § 2.2.3 jdec_private
- 三、实验结果
-
- § \text{\S} § 3.1 JPEG to YUV
- § \text{\S} § 3.2 得到量化矩阵和Huffman表
-
- § \text{\S} § 3.2.1 输出量化矩阵
- § \text{\S} § 3.2.2 输出Huffman码表
- § \text{\S} § 3.3 输出某一个DC、AC值图像并统计其概率分布
JPEG原理分析及JPEG解码器的调试
一、JPEG格式介绍
§ \text{\S} § 1.1 JPEG简介
JPEG 是 Joint Photographic Exports Group 的英文缩写,中文称之为联合图像专家小组。该小组隶属于 ISO 国际标准化组织,主要负责定制静态数字图像的编码方法,即所谓的 JPEG算法。 JPEG图像压缩算法能够在提供良好的压缩性能的同时,具有比较好的重建质量,被广泛应用于图像、视频处理领域,网站上80%的图像都采用了JPEG压缩标准。
§ \text{\S} § 1.2 JPEG编码流程
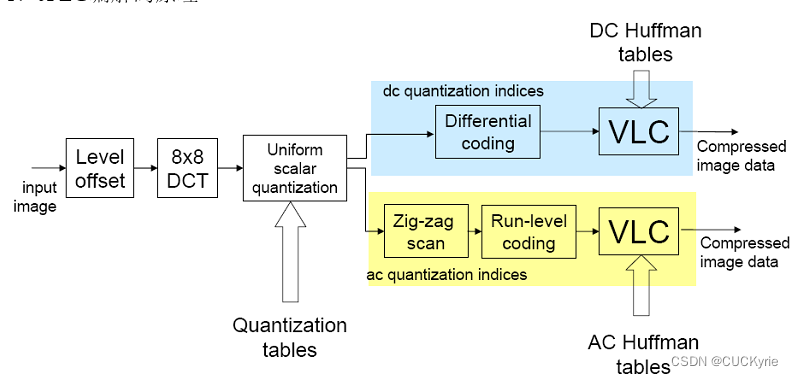 过程解析:
过程解析:
- 将传入的图像的亮度分量全部进行128电平偏置,即 p i x e l v a l = p i x e l v a l − 128 pixel_{val} = pixel_{val} -128 pixelval=pixelval−128,以此将每个像素点的取值范围从 [ 0 , 255 ] [0,255] [0,255]变换到 [ − 128 , 127 ] [-128,127] [−128,127]。这个部分其实是一个历史遗留问题,但是也可以发现这一操作使我们的算法系统设计更为便利。
- 进行 8 × 8 8 \times 8 8×8的DCT变换,实现能量集中和去相关,降低空间冗余度。
- 进行均匀量化,这一过程需要使用由人眼特性制作的量化表,特点是低频细量化,高频粗量化。
- 对直流系数进行差分和VLC编码,对交流系数使用
zig-zag扫描和游程编码,再进行VLC编码。
§ \text{\S} § 1.2.1 颜色空间转换
JPEG采用的是YCbCr颜色空间,所以在传入RGB图片前,需要先进行色彩空间转换,YCrCb颜色空间中,Y 代表亮度,Cr,Cb则代表色度和饱和度(也有人将 Cb,Cr 两者统称为色度),三者通常以 Y,U,V 来表示,即用 U 代表 Cb,用 V 代表 Cr。 Y = 0.299 R + 0.587 G + 0.114 B C b = − 0.1687 R − 0.3313 G + 0.5 B + 128 C r = 0.5 R = 0.418 G − 0.0813 B + 128 Y = 0.299R+0.587G+0.114B \\ Cb = -0.1687R-0.3313G+0.5B+128 \\ Cr = 0.5R=0.418G-0.0813B+128 Y=0.299R+0.587G+0.114BCb=−0.1687R−0.3313G+0.5B+128Cr=0.5R=0.418G−0.0813B+128
§ \text{\S} § 1.2.2 采样
,因此一般我们选用的图像都是4:2:0或者4:2:2的采样格式。
§ \text{\S} § 1.2.3 电平偏置
如上述过程解析中所说,
§ \text{\S} § 1.2.4 8 × 8 8 \times 8 8×8DCT变换
DCT 变换是对 8 × 8 8 \times 8 8×8 的子块进行处理的,因此,在进行 DCT 变换之前必须把源图象数据进行分块。源图像中每点的 3个分量是交替出现的,先要把这 3 个分量分开,存放到 3 张表中去。然后由左及右,由上到下依次读取 8 × 8 8 \times 8 8×8的子块,存放在长度为 64 的表中,即可以进行 DCT 变换。这里注意,如果图像的宽高不是8的倍数,需要进行填充,
DCT变换(离散余弦变换)使傅里叶变换相关的一种变换,通过DCT变换可以使图像能量集中,同时去除相关性,降低冗余度。
§ \text{\S} § 1.2.5 量化
对进行DCT变换后的系数进行量化,会有一张量化表规定每个DCT系数的量化步长。
§ \text{\S} § 1.2.6 DC系数编码
直流系数 f ( 0 , 0 ) f(0,0) f(0,0)反映了该图像包含的全部直流成分,一般值会很大,又因为通常两个相邻子图像块之间具有较强的相关性,所以可以引入DPCM差分预测编码。即:
§ \text{\S} § 1.2.7 AC系数编码
经过DCT变换后,大部分的非零系数都集中在了DCT矩阵的左上角,通过Z字型读取后我们可以尽可能将0系数集中在一起,方便后续的游程编码。这一部分的实现在代码中体现为类似八皇后问题的思路: zig-zag扫描后,进行游程编码(RLC)。在JPEG中,游程编码的格式规定为: ( r u n , l e v e l ) (run, level) (run,level)。
- 表示连续run个0,后面跟一个值为level的系数。
- run最多15个,用4位表示XXXX。
- level类似DC,分成16个类别,用4位表示类别号RRRR,并支持类内索引。
- 对(XXXX,RRRR)进行Huffman编码。
- 对类内索引进行定长码编码
§ \text{\S} § 1.3 JPEG文件格式
§ \text{\S} § 1.3.1 JPEG语法结构
JPEG在文件中以Segment的形式组织,具有以下特点:
- 均以
0xFF开始,后跟1字节的标记标识符和2字节的标记长度以及该标记所对应的payloada。 - 标记长度部分高位在前,低位在后,不包含该标记的头两个字节。
- 熵编码部分的数据在
0xFF后由编码器插入0x00,解码器解码时跳过此字节不予处理。 SOI和EOI标记没有payload。
参数说明:
SOI:Start Of Image表示图像的开始,固定值为FFD8。SOF0:帧图像的开始,记录每一帧图像的数据长度、样本数据的位数、图像的宽高、颜色分量数、颜色分量信息(分量ID(Y、U、v)、采样因子(4:4:4、4:2:2、4:2:0)、量化表ID)。DQT:DCT量化表,记录量化表长度、量化精度、量化表ID、表项(长度为64bit(8位精度),记录了8*8DCT变换后每个像素的量化步长,由于DC、AC、亮度、色度使用不同的量化编,所有量化表最多有4个)。DHT0:定义Huffman码表。表长度、表ID(0:亮度 1:色度)、表类型(0:直流 1:交流)不同位数的码字数量(16字节分别记录了长度为1到16的码字的个数)、权值。APP0:应用程序保留标记 (版本参数信息)。DC表:权值的大小直流分量数值的二进制位数,读取后经过查表查得对应的DC值。权值的字节数为DC经DPCM编码后码字个数的总和。AC表:权值的高四位表示当前数值前面有多少个0,低4为表示交流分量数值的二进制位数。SOS:扫描开始标记,记录了数据长度、颜色分量数(与SOF0相同)、颜色分量信息(颜色分量ID:123对应YUV)、表号:(高位为直流系数使用的Huffman表数、低位为交流系数使用的Huffman表数)、压缩图像数据。EOI:End Of Image,图像结束标记。
- JPEG由若干个必不可少的标记顺序连接构成整个文件。
- 文件一定以
0xFFD8开始,即表示图像开始的SOI标记。 - 文件一定以
0xFFD9结束,表示图像结束的EOI标记。
§ \text{\S} § 1.3.2 APP0 Segment
有九个字段
| 字段 | 字节数 | 含义 |
|---|---|---|
| 数据长度 | 2字节 | 1-9共9个字段的总长度 |
| 标识符 | 5字节 | 固定值0x4A46494600,即字符串“JFIF0” |
| 版本号 | 2字节 | 一般是0x0102,表示JFIF的版本号1.2 |
| X和Y的密度单位 | 1字节 | 只有三个值可选 0:无单位;1:点数/英寸;2:点数/厘米 |
| X方向像素密度 | 2字节 | X方向像素密度 |
| Y方向像素密度 | 2字节 | Y方向像素密度 |
| 缩略图水平像素数 | 1字节 | 缩略图水平像素数目 |
| 缩略图垂直像素数 | 1字节 | 缩略图垂直像素数目 |
| 缩略图RGB位图 | 3字节的倍数 | 缩略RGB位图,n为像素数 |
§ \text{\S} § 1.3.3 量化表DQT
- 一般是两个量化表,即亮度和色度各一张。
- 以
0xFFDB开始:- 量化表长度,一般是
0043或者0084。 - 量化表信息(1字节)
bit 0-3:QT号,取值只能是0-3。bit 4-7:QT精度,0为8比特,否则是16比特。
- 量化表的实际数据,按照Z字形保存量化表内 8 × 8 8 \times 8 8×8的数据。
- 量化表长度,一般是
§ \text{\S} § 1.3.4 帧图像开始SOF0
以0xFFC0开始
| 字段 | 字节数 | 含义 |
|---|---|---|
| SOF长度 | 2字节 | 固定为0x0011 |
| 精度 | 1字节 | 每个颜色分量每个像素的位数,通常为8 |
| 图像高度 | 2字节 | 以像素数表示图像的高度 |
| 图像宽度 | 2字节 | 以像素数表示图像的宽度 |
| 颜色分量数 | 1字节 | 通常是3 |
| 颜色分量信息 | 颜色分量数x3字节,一般是9字节 | 1字节 1字节 高四位为水平采样因子,低四位为垂直采样因子 1字节 当前分量所使用量化表的ID |
§ \text{\S} § 1.3.5 Huffman表
数值为0xFFC4。
Huffman表的长度- 类型(
AC或者DC) - 索引
index - 位表
bit table - 值表
value table
其中Huffman表的类型只有四种:
0x00表示DC直流0号表0x01表示DC直流1号表0x10表示AC交流0号表0x11表示AC交流1号表
举例说明:如下是一个Huffman码表
- 黑色部分包含表头和长度(
0x001D) - 红色部分是表的ID和类型,这里的
00表示此部分数据描述的是DC直流0号表。 - 蓝色部分(16字节),为不同位数的码字的数目。这16个数值的实际意义是:没有1位的码字;有3个2位的码字;有1个3位的码字…以此类推。
- 绿色部分(10字节):为编码内容,通过蓝色数据部分我们知道
Huffman树中一共有10个叶子节点,所以这一部分的数据长度就是10字节。表示每个叶子节点从小到大(所谓从小到大实际上是指的码长和出现顺序)排序后,对应的权值(权值对直流和交流系数的含义不同,这一点在后面会说明)。
建立Huffman表
建立Huffman表的方式其实很简单:
具体方法为:
-
- 如果第一个码字位为1,则码字为0;
- 如果第一个码字位为2,则为00;
- 以此类推…
- 从第二个码字开始
- 如果它和它前面的码字位数相同,则当前码字为它前面的码字加1;
- 如果它的位数比它前面的码字位数大,则当前码字是前面的码字加1后再在后边添若干个0,直至满足位数长度为止。
我们按照上面给出的例子建立一个Huffman码表:
| 序号 | 码长 | 码字 | 权重 |
|---|---|---|---|
| 1 | 2 | 00 | 4 |
| 2 | 2 | 01 | 5 |
| 3 | 2 | 10 | 6 |
| 4 | 3 | 110 | 3 |
| 5 | 4 | 1110 | 2 |
| 6 | 5 | 11110 | 1 |
| 7 | 6 | 111110 | 0 |
| 8 | 7 | 1111110 | 9 |
| 9 | 8 | 11111110 | 7 |
| 10 | 9 | 111111110 | 8 |
下面解释一下在直流和交流中权重的作用:
直流
对于直流来说,。这个再次读入的数通过查表来得到真正的码值。 比如比特流:0110101011 读入01后码字结束,查表可以得到额外比特数为5,所以需要额外读5位数,此处为10101,译码可以得到21,所以直流系数为21。要注意的是,直流系数是差分编码之后得到的。
实际中的过程是把所有的颜色分量单元按颜色分量(Y、Cr、Cb)分类。每一种颜色分量内,相邻的两个颜色分量单元的直流变量是以差分来编码的。也就是说,通过Huffman码表解码出来的直流变量数值。也就是说,当前直流变量要通过前一个颜色分量单元的实际(非解码)直流分量来校正,即 D C n = D C n − 1 + D i f f DC_n = DC_{n-1} + Diff DCn=DCn−1+Diff,这里的 D i f f Diff Diff就是我们解码得到的直流系数,如果此时的颜色分量单元是第一个单元,则解码出来的直流系数就是真正的直流变量值。
交流
对于交流系数,用交流哈夫曼树/表查得该码字对应的权值。权值的高4位表示当前数值前面有多少个连续的零,低4位表示该交流分量数值的二进制位数,也就是接下来需要读入的位数。
例如,权值0x31可以表示为(3,1)。表明交流系数前面有3个0,此外交流系数的具体值还需要再读入1bit的码字才能得到。
二、JPEG代码分析
§ \text{\S} § 2.1 代码架构
§ \text{\S} § 2.1.1 main函数
接受输入输出文件名称参数,打开TRACEFILE。通过输入参数选择需要输出的文件格式,此实验为YUV420,同时调用convert_one_image()。
int main(int argc, char* argv[])
{
int output_format = TINYJPEG_FMT_YUV420P;
char* output_filename, * input_filename;
clock_t start_time, finish_time;
unsigned int duration;
int current_argument;
int benchmark_mode = 0;
#if TRACE
p_trace = fopen(TRACEFILE, "w");
if (p_trace == NULL)
{
printf("trace file open error!");
}
#endif
if (argc < 3)
usage();
current_argument = 1;
while (1)
{
if (strcmp(argv[current_argument], "--benchmark") == 0)
benchmark_mode = 1;
else
break;
current_argument++;
}
if (argc < current_argument + 2)
usage();
input_filename = argv[current_argument];
if (strcmp(argv[current_argument + 1], "yuv420p") == 0)
output_format = TINYJPEG_FMT_YUV420P;
else if (strcmp(argv[current_argument + 1], "rgb24") == 0)
output_format = TINYJPEG_FMT_RGB24;
else if (strcmp(argv[current_argument + 1], "bgr24") == 0)
output_format = TINYJPEG_FMT_BGR24;
else if (strcmp(argv[current_argument + 1], "grey") == 0)
output_format = TINYJPEG_FMT_GREY;
else
exitmessage("Bad format: need to be one of yuv420p, rgb24, bgr24, grey\n");
output_filename = argv[current_argument + 2];
start_time = clock();
if (benchmark_mode)
load_multiple_times(input_filename, output_filename, output_format);
else
convert_one_image(input_filename, output_filename, output_format);
finish_time = clock();
duration = finish_time - start_time;
snprintf(error_string, sizeof(error_string), "Decoding finished in %u ticks\n", duration);
#if TRACE
fclose(p_trace);
#endif
return 0;
}
§ \text{\S} § 2.1.2 convert_one_image
打开输入输出文件,初始化jdec结构体,获得文件参数信息,主要调用tinyjpeg_parse_header()解码jpeg图像,最后调用write_yuv()写入yuv文件。
/** * Load one jpeg image, and decompress it, and save the result. * 加载一个JPEG图像,并进行解压缩和存储 */